Azure プラットフォームの回復性
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

クラウドで信頼性の高いアプリケーションを構築することは、従来のオンプレミスでのアプリケーション開発とは異なります。 従来は、よりハイエンドのハードウェアを購入してスケールアップしていましたが、クラウド環境ではスケールアウトします。障害を防ごうとするのではなく、障害の影響を最小限に抑えてシステムの安定性を維持することが目標です。
とは言え、信頼性の高いクラウド アプリケーションには明らかな特性が認められます。
- 回復性があり、問題から適切に回復し、引き続き機能します。
- 高可用性 (HA) があり、大幅なダウンタイムのない正常な状態で設計どおりに動作します。
これらの特性の連携およびコストへの影響について理解することは、信頼性の高いクラウドネイティブ アプリケーションを構築するうえで不可欠です。 次に、Azure クラウドの機能を利用して、ご自身のクラウドネイティブ アプリケーションに回復性と可用性を構築する方法について見ていきましょう。
回復性を備えた設計
前述のように、回復性とは、アプリケーションが障害に対処して継続的に機能できることを言います。 Azure の回復性についてのホワイトペーパーには、Azure プラットフォームで回復性を実現するためのガイダンスが示されています。 以下に、重要な推奨事項をいくつか示します。
"ハードウェア障害"。 異なる複数の障害ドメインにコンポーネントを配置することで、アプリケーションに冗長性を持たせることができます。 たとえば、可用性セットを使用して、Azure VM が確実に別々のラックに配置されるようにします。
"データセンターの障害"。 データセンター間に障害分離ゾーンを設けて、アプリケーションに冗長性を持たせることができます。 たとえば、Azure Availability Zones を使用して、Azure VM が確実に別々の障害分離データセンターに配置されるようにします。
"リージョンの障害"。 アプリケーションを迅速に復旧できるように、データとコンポーネントを別のリージョンにレプリケートします。 たとえば、Azure Site Recovery を使用して Azure VM を別の Azure リージョンにレプリケートします。
"高負荷"。 インスタンス間の負荷分散によって、使用量の急増に対応します。 たとえば、ロード バランサーの背後に 2 台以上の Azure VM を配置し、トラフィックをすべての VM に分散させることができます。
"過失によるデータの削除または破損"。 削除または破損した場合に復元できるように、データをバックアップします。 たとえば、Azure Backup を使用して、Azure VM を定期的にバックアップします。
冗長性を備えた設計
障害によって影響の範囲が異なります。 障害が発生したディスクなどのハードウェア障害は、クラスター内の 1 つのノードに影響を与える場合があります。 ネットワーク スイッチで障害が発生すると、サーバー ラック全体に影響する可能性があります。 停電などのあまり一般的ではない障害の場合、データセンター全体が停止するおそれがあります。 リージョン全体が利用できなくなることはほとんどありません。
冗長性は、アプリケーションに回復性を持たせる 1 つの方法です。 必要とされる冗長性の正確なレベルは、ビジネス要件によって異なり、システムのコストと複雑さの両方に影響します。 たとえば、複数リージョンのデプロイは、単一リージョンのデプロイよりもコストがかかり、管理も複雑です。 フェールオーバーとフェールバックを処理するための操作手順が必要になります。 追加コストと複雑さが理にかなっているかどうかは、ビジネス シナリオによって決まる場合もあれば、そうでない場合もあります。
冗長性を設計するには、アプリケーションのクリティカル パスを特定し、パスの各ポイントに冗長性があるかどうかを確認する必要があります。 サブシステムで障害が発生した場合、アプリケーションから他の何かにフェールオーバーしますか。 最後に、冗長性の要件を満たすために利用できる、Azure クラウド プラットフォームに組み込まれている機能を明確に理解する必要があります。 冗長性を設計するための推奨事項を次に示します。
複数のインスタンスのサービスをデプロイします。 アプリケーションがサービスの 1 つのインスタンスに依存する場合は、単一障害点が発生します。 複数のインスタンスをプロビジョニングすると、回復性とスケーラビリティの両方が改善されます。 Azure Kubernetes Service でホストする場合は、Kubernetes マニフェスト ファイル内に冗長インスタンス (レプリカ セット) を宣言によって構成できます。 レプリカ数の値は、プログラム、ポータル、または自動スケーリング機能を使用して管理できます。
"ロード バランサーを活用する"。 負荷分散を使用すると、アプリケーションの要求を正常なサービス インスタンスに分散し、正常でないインスタンスをローテーションから自動的に除去できます。 Kubernetes にデプロイする場合は、Kubernetes マニフェスト ファイルのサービスのセクションに負荷分散を指定できます。
"複数リージョンのデプロイに関する計画を立てる"。 アプリケーションを 1 つのリージョンにデプロイすると、そのリージョンが使用できなくなった場合は、アプリケーションも使用できなくなります。 これは、ご自身のアプリケーションに適用されるサービス レベル アグリーメントの条項によっては、受け入れることができない場合があります。 その場合は、アプリケーションとそのサービスを複数のリージョンにデプロイすることを検討してください。 たとえば、Azure Kubernetes Service (AKS) クラスターが 1 つのリージョンにデプロイされているとします。 リージョン内の障害からシステムを保護するには、異なるリージョンの複数の AKS クラスターにアプリケーションをデプロイし、ペアのリージョン機能を使用してプラットフォームの更新を調整し、復旧作業の優先順位を設定します。
" geo レプリケーションを有効にする"。 Azure SQL Database や Cosmos DB などのサービスの場合、geo レプリケーションで複数のリージョンにデータのセカンダリ レプリカが作成されます。 どちらのサービスでも同じリージョン内のデータが自動的にレプリケートされますが、geo レプリケーションの場合、セカンダリ リージョンへのフェールオーバーを可能にすることで、リージョンの停止を防ぐことができます。 geo レプリケーションに関するもう 1 つのベスト プラクティスは、コンテナー イメージの格納に関することです。 AKS でサービスをデプロイするには、リポジトリからイメージを格納してプルする必要があります。 Azure Container Registry は AKS と統合されており、コンテナー イメージを安全に格納できます。 パフォーマンスや可用性を改善するには、AKS クラスターが置かれている各リージョン内のレジストリへの geo レプリケーションを検討してください。 その後、図 6-4 に示すように、そのリージョンのローカル コンテナー レジストリから各 AKS クラスターにコンテナー イメージがプルされます。
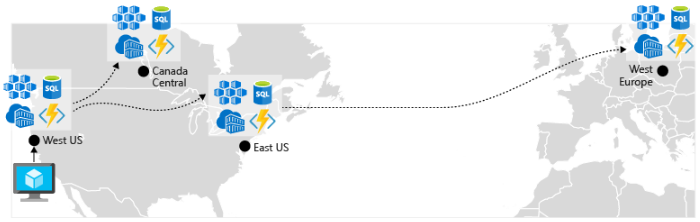
図 6-4。 リージョン間でレプリケートされたリソース
- "DNS トラフィックのロード バランサーを実装する"。Azure Traffic Manager を使用すると、DNS レベルでの負荷分散によって、重要なアプリケーションに高可用性が提供されます。 地理、クラスターの応答時間、さらにはアプリケーションのエンドポイントの正常性に基づいて、異なるリージョンにトラフィックをルーティングすることができます。 たとえば、Azure Traffic Manager を使用して、お客様を最も近い AKS クラスターおよびアプリケーション インスタンスに送ることができます。 複数のリージョンに複数の AKS クラスターがある場合は、Traffic Manager を使用して、各クラスターで実行されているアプリケーションにトラフィックをどのように送信するかを制御します。 図 6-5 に、このシナリオを示します。
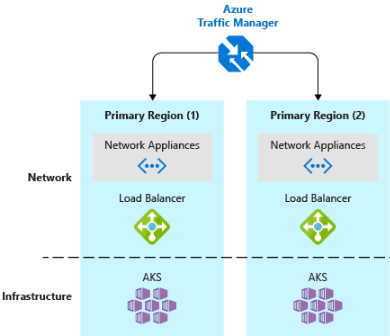
図 6-5。 AKS と Azure Traffic Manager
スケーラビリティのための設計
クラウドはスケーリングによって成立しています。 システム負荷の増減に対応してシステム リソースを増減する機能は、Azure クラウドの重要な理念です。 しかし、アプリケーションを効果的にスケーリングするには、アプリケーションに含める各 Azure サービスのスケーリング機能について理解しておく必要があります。 ここでは、ご自身のシステムにスケーリングを効果的に実装するための推奨事項を示します。
スケーリングを考慮して設計します。 アプリケーションは、スケーリングできるように設計する必要があります。 第一に、サービスがステートレスである必要があります。これにより、任意のインスタンスに要求をルーティングできます。 サービスがステートレスであれば、インスタンスを追加または削除しても現在のユーザーに悪影響はありません。
"ワークロードを分割する"。 ドメインを独立した自己完結型マイクロサービスに分解することにより、各サービスを他のサービスとは無関係にスケーリングできます。 通常、スケーラビリティのニーズと要件はサービスによって異なります。 分割することで、アプリケーション全体のスケーリングに不要なコストをかけることなく、スケーリングする必要があるものだけをスケーリングすることができます。
"スケールアウトを優先する"。クラウドベースのアプリケーションでは、リソースのスケールアップではなくスケールアウトが優先されます。 スケールアウト (水平スケーリングとも呼ばれます) の場合、必要なレベルのパフォーマンスを満たして共有するために、既存のシステムにサービス リソースが追加されます。 スケールアップ (垂直スケーリングとも呼ばれます) の場合、既存のリソースをより強力なハードウェア (より多くのディスク、メモリ、処理コア) に置き換える必要があります。 スケールアウトは、一部の Azure クラウド リソースで使用可能な自動スケーリング機能を使用して自動的に呼び出すことができます。 複数のリソース間でスケールアウトすると、システム全体の冗長性も追加されます。 最後に、単一リソースのスケールアップは一般的に、小さい多数のリソース間のスケールアウトよりもコストが高くなります。 図 6-6 はこの 2 つの方法を示しています。
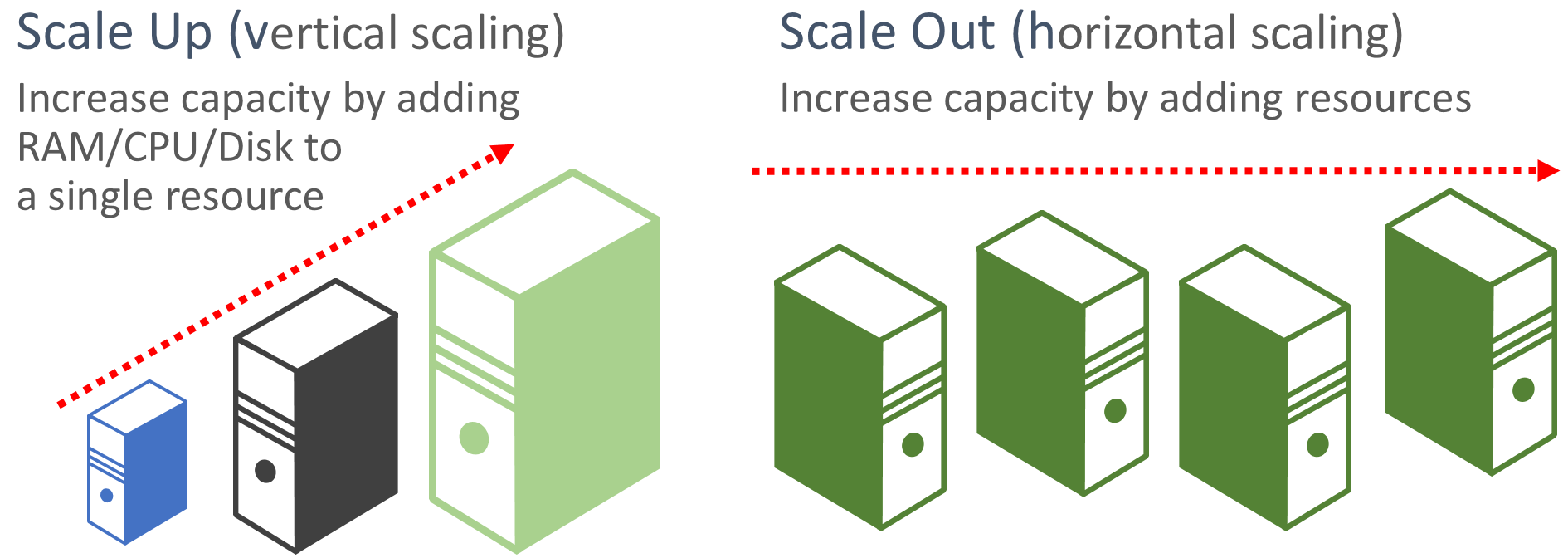
図 6-6 スケールアップとスケールアウト
"比例的にスケーリングする"。 サービスをスケーリングする場合は、"リソース セット" について考慮します。 特定のサービスを大幅にスケールアウトした場合、バックエンドのデータ ストア、キャッシュ、依存サービスに対してどのような影響があるでしょうか。 Cosmos DB などの一部のリソースは比例的なスケールアウトができますが、他の多くではそれができません。 他の関連リソースを使い果たすまでリソースをスケールアウトしないようにする必要があります。
"アフィニティを避ける"。 ベスト プラクティスは、ノードにローカル アフィニティが必要にならないようにすることで、これは "スティッキー セッション" と呼ばれることがよくあります。 要求は、任意のインスタンスにルーティングできなければなりません。 状態を永続化する必要がある場合は、Azure Redis Cache などの分散キャッシュに保存する必要があります。
プラットフォームの自動スケーリング機能を利用します。 可能な限り、カスタムまたはサードパーティのメカニズムではなく、組み込みの自動スケーリング機能を使用します。 可能な場合は、スケジュールされたスケーリング ルールを使用し、起動時の遅延なしで確実にリソースを使用可能にします。しかし、必要に応じてリアクティブ自動スケーリングをルールに追加し、予期しない要求の変化に対応する必要があります。 詳しくは、「自動スケール」のガイダンスをご覧ください。
"積極的にスケールアウトする"。 最後の方法は、ビジネスを失うことなくトラフィックの急増にすばやく対応できるように、積極的にスケールアウトすることです。 そしてその後、システムを安定した状態に維持するために、注意しながらスケールイン (つまり、不要なインスタンスを削除) します。 これを実装する簡単な方法は、クールダウン期間を設定することです。これは、スケーリング操作の間の待機時間であり、リソースを追加する場合は 5 分に、インスタンスを削除する場合は最大 15 分とします。
サービスでの組み込みの再試行
前のセクションでは、プログラムによる再試行操作を実装するというベスト プラクティスをお勧めしました。 多くの Azure サービスとそれらに対応するクライアント SDK にも再試行メカニズムが含まれていることにご注意ください。 次の一覧は、このブックで説明されている多くの Azure サービスの再試行機能をまとめたものです。
Azure Cosmos DB。 クライアント API の DocumentClient クラスを使用すると、失敗した試行が自動的に再試行されます。 再試行回数と最大待機時間は構成可能です。 クライアント API によってスローされる例外は、再試行ポリシーを超過した要求または一時的でないエラーのいずれかです。
Azure Redis Cache。 Redis StackExchange クライアントの場合、失敗した試行に対する再試行を含む接続マネージャー クラスを使用します。 再試行回数、特定の再試行ポリシー、待機時間はすべて構成可能です。
Azure Service Bus。 Service Bus クライアントが公開している RetryPolicy クラス は、バックオフ間隔、再試行回数、および操作の最長所要時間を指定する TerminationTimeBuffer を使用して構成できます。 既定のポリシーは、最大再試行回数が 9 回で、試行の間のバックオフ期間が 30 秒です。
Azure SQL Database。 Entity Framework Core ライブラリを使用する場合は、再試行のサポートが提供されます。
Azure Storage です。 ストレージ クライアント ライブラリで再試行操作がサポートされています。 戦略は、Azure Storage のテーブル、BLOB、キューによって異なります。 さらに、geo 冗長機能が有効になっている場合は、プライマリとセカンダリのストレージ サービスの場所が交互に再試行されます。
Azure Event Hubs。 Event Hub クライアント ライブラリには、構成可能なエクスポネンシャル バックオフ機能を含む RetryPolicy プロパティが用意されています。
.NET