アプリケーションの回復性パターン
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

防御の最前線は、アプリケーションの回復性です。
かなりの時間を費やして独自の回復性フレームワークの作成することもできますが、そのような製品は既に存在しています。 Polly は、.NET の回復性および一時的障害処理の包括的なライブラリです。開発者はこれを使用して、緩やかかつスレッドセーフな方法で回復性ポリシーを表すことができます。 Polly の対象は、.NET Framework または .NET 7 のいずれかを使用してビルドされたアプリケーションです。 次の表では、Polly ライブラリで使用できる、policies と呼ばれる回復性機能について説明します。 これらは個別に適用することも、グループ化することもできます。
| ポリシー | エクスペリエンス |
|---|---|
| 再試行 | 指定された操作について再試行操作を構成します。 |
| Circuit Breaker | エラーが構成されたしきい値を超えたとき、事前に定義された期間、要求された操作をブロックします。 |
| タイムアウト | 呼び出し元が応答を待機できる期間を制限します。 |
| バルクヘッド | 失敗した呼び出しによってリソースが枯渇しないように、固定サイズのリソース プールにアクションを制限します。 |
| キャッシュ | 応答を自動的に保存します。 |
| フォールバック | エラー発生時の構造化動作を定義します。 |
前の表では、外部クライアントとバックエンド サービスのどちらから送信されたかにかかわらず、要求メッセージに回復性ポリシーが適用されることに注意してください。 目標は、一時的に使用できなくなる可能性があるサービスのために要求を補正することです。 通常、このような短時間の中断は、次の表に示す HTTP 状態コードを使用して表されます。
| HTTP 状態コード | 原因 |
|---|---|
| 404 | Not Found |
| 408 | 要求タイムアウト |
| 429 | 要求が多すぎます (おそらく調整されている可能性があります) |
| 502 | Bad gateway |
| 503 | Service unavailable |
| 504 | ゲートウェイ タイムアウト |
質問: HTTP 状態コード 403 - 禁止の場合に再試行できますか。 いいえ。 ここで、システムは正常に機能していますが、要求された操作を実行する権限がないことを呼び出し元に通知しています。 障害によって発生した操作のみを再試行するように注意する必要があります。
第 1 章で推奨されているように、クラウドネイティブ アプリケーションを構築する Microsoft 開発者は、.NET プラットフォームを対象とする必要があります。 バージョン 2.1 では、URL ベースのリソースと対話するための HTTP クライアント インスタンスを作成するために HTTPClientFactory ライブラリが導入されました。 ファクトリ クラスは、元の HTTPClient クラスを置き換えることで、強化された多くの機能をサポートしています。その 1 つは、Polly 回復性ライブラリとの緊密な統合です。 これを使用すると、アプリケーションのスタートアップ クラスで回復性ポリシーを簡単に定義して、部分的なエラーや接続の問題を処理することができます。
次に、再試行パターンおよびサーキット ブレーカー パターンについて説明します。
再試行パターン
分散型クラウドネイティブ環境では、サービスとクラウド リソースへの呼び出しが、一時的な (短期間の) エラーのために失敗することがあります。これらは、通常、しばらくして自動的に修正されます。 再試行戦略を実装すると、クラウドネイティブ サービスでこのようなシナリオを軽減できるようになります。
再試行パターンでは、サービスが、失敗した要求操作を数回 (構成可能) 再試行できます (待機時間は指数関数的に長くなります)。 図 6-2 は、実施中の再試行を示しています。
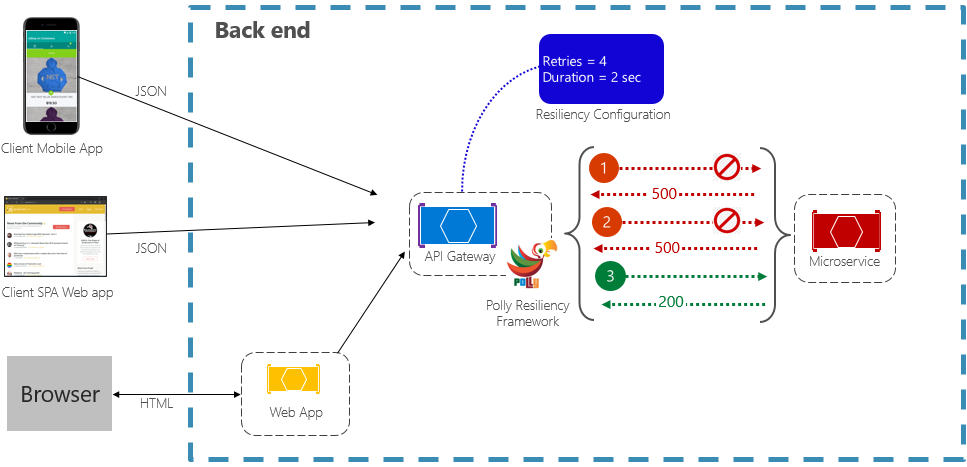
図 6-2。 動作中の再試行パターン
前の図では、要求操作に対して再試行パターンが実装されています。 失敗するまでに、最大で 4 回の再試行を許可するように構成されており、最初はバックオフ間隔 (待機時間) は 2 秒ですが、試行のたびに指数関数的に倍増します。
- 最初の呼び出しは失敗し、HTTP 状態コード 500 が返されます。 アプリケーションは 2 秒間待機し、呼び出しを再試行します。
- 2 回目の呼び出しも失敗し、HTTP 状態コード 500 が返されます。 アプリケーションは、バックオフ間隔を 2 倍の 4 秒にして、呼び出しを再試行します。
- 最後に、3 回目の呼び出しが成功します。
- このシナリオでは、呼び出しが失敗するまでに、再試行操作によって最大 4 回再試行され、そのたびにバックオフ期間が 2 倍になります。
- 4 回目の再試行が失敗した場合には、フォールバック ポリシーが呼び出されて、問題を適切に処理します。
サービスが自動的に修正される時間を確保するために、呼び出しを再試行する前にバックオフ期間を長くすることが重要です。 最適な修正時間を確保するには、指数関数的に長くなるバックオフ (再試行ごとに期間が 2倍 になる) を実装することをお勧めします。
サーキット ブレーカー パターン
再試行パターンを使用すると、部分的な障害に巻き込まれる要求を減らすことができますが、予期しないイベントのためにエラーが発生する状況があり、これを解決するには長い時間がかかります。 このような障害の重大度は、部分的な接続の損失からサービスの完全な不具合まで多岐にわたります。 このような状況では、アプリケーションが成功の見込みの薄い操作を再試行し続けても意味がありません。
事態を悪化させるのは、応答しないサービスに対して継続的な再試行操作を実行すると、サービス拒否シナリオを自ら引き起こす可能性があるということです。継続的な呼び出しを大量にサービスに送りつけるために、リソース (メモリ、スレッド、データベース接続など) が枯渇し、システムの関連していない部分でも同じリソースを使用していると障害が発生する可能性があります。
このような状況では、操作はすぐに失敗し、成功する可能性がある場合のみサービスの呼び出しが試行されることが望ましいでしょう。
サーキット ブレーカー パターンは、アプリケーションが失敗する可能性のある操作を繰り返し試行するのを防ぐことができます。 事前定義された回数の呼び出し失敗が発生すると、サービスへのすべてのトラフィックがブロックされます。 エラーが解決したかどうかを判別するために、定期的に呼び出しを試すことは許可されます。 図 6-3 は、動作中のサーキット ブレーカー パターンを示しています。
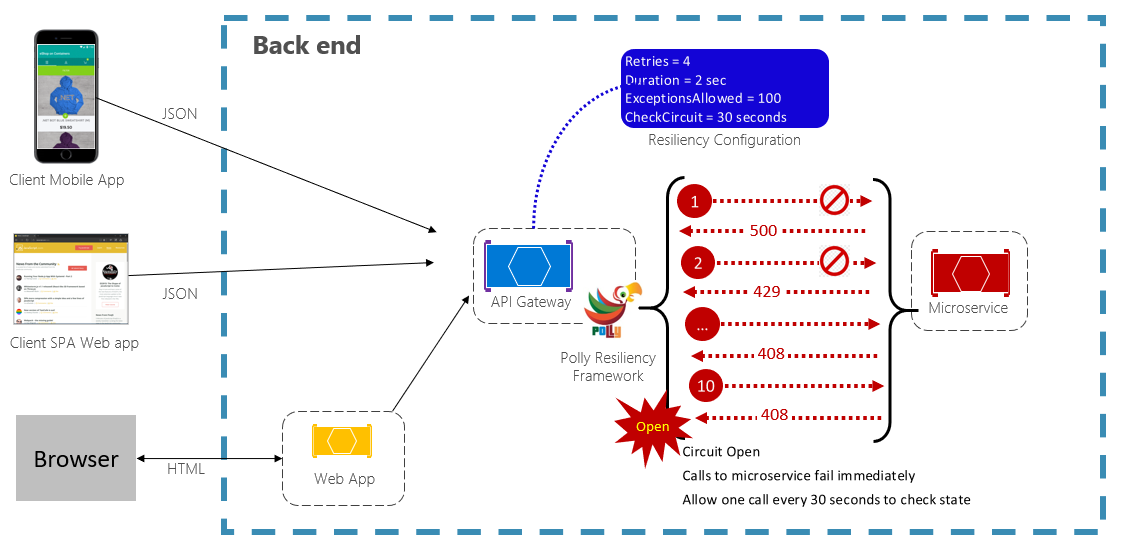
図 6-3。 動作中のサーキット ブレーカー パターン
前の図では、サーキット ブレーカー パターンが元の再試行パターンに追加されています。 100 回要求が失敗するとサーキット ブレーカーが開き、サービスへの呼び出しが許可されなくなることに注意してください。 CheckCircuit 値 (30 秒に設定) によって、ライブラリがサービスに 1 つの要求を送ることができる間隔が指定されます。 その呼び出しが成功すると、サーキットが閉じて、サービスがトラフィックに対して再び使用可能になります。
サーキット ブレーカー パターンの目的は、再試行パターンとは "異なる" ことに注意してください。 再試行パターンでは、操作が最終的には成功するとの見込みをもってアプリケーションに操作を再試行させます。 サーキット ブレーカー パターンは、失敗する可能性の高い操作をアプリケーションが実行しないようにします。 通常、アプリケーションは、サーキット ブレーカーを介して操作を呼び出す再試行パターンを使用して、これら 2 つのパターンを "結合" できます。
回復性のテスト
回復性のテストは、常に、アプリケーション機能のテストと同じ方法 (単体テストや統合テストなどの実行) では実行できません。 代わりに、断続的にのみ発生する障害条件下で、エンドツーエンドのワークロードが動作する方法をテストする必要があります。 たとえば、プロセスをクラッシュしてエラーを挿入したり、証明書を期限切れにしたり、依存サービスを使用不可にしたりします。このようなカオス テストには chaos-monkey などのフレームワークを使用できます。
アプリケーションの回復性は、問題のある要求操作を処理するために必須です。 しかし、これではまだ十分ではありません。 次に、Azure クラウドで使用できる回復性機能について説明します。
.NET