チュートリアル: Azure AI サービスを使用した Text Analytics
このチュートリアルでは、Text Analytics を使用して、Azure Synapse Analytics の非構造化テキストを分析する方法を説明します。 Text Analytics は、自然言語処理 (NLP) 機能を使用してテキスト マイニングとテキスト分析を実行できる Azure AI services です。
このチュートリアルでは、SynapseML でテキスト分析を使用して次の処理を行う方法を示します。
- 文またはドキュメント レベルでセンチメント ラベルを検出する
- 特定のテキスト入力の言語を識別する
- 既知のナレッジ ベースへのリンクを使用して、テキストからエンティティを認識する
- テキストからのキー フレーズの抽出
- テキスト内の異なるエンティティを識別し、事前定義済みのクラスまたは型に分類する
- 特定のテキスト内の機密性の高いエンティティを識別して編集する
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
- Azure Data Lake Storage Gen2 ストレージ アカウントが既定のストレージとして構成されている Azure Synapse Analytics ワークスペース。 使用する Data Lake Storage Gen2 ファイル システムの "Storage Blob データ共同作成者" である必要があります。
- Azure Synapse Analytics ワークスペースの Spark プール。 詳細については、Azure Synapse での Spark プールの作成に関する記事を参照してください。
- Azure Synapse での Azure AI サービスの構成に関するチュートリアルで説明されている事前構成の手順。
作業の開始
Synapse Studio を開き、新しいノートブックを作成します。 はじめに、SynapseML をインポートします。
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
テキスト分析を構成する
事前構成の手順で構成した、リンクされたテキスト分析を使用します。
linked_service_name = "<Your linked service for text analytics>"
テキスト センチメント
テキスト感情分析を使用すると、文とドキュメントのレベルでセンチメント ラベル ("negative"、"neutral"、"positive" など) と信頼度スコアを検出する手段が得られます。 有効な言語の一覧については、「Text Analytics API でサポートされている言語」を参照してください。
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
予想される結果
| text | センチメント |
|---|---|
| I'm so happy today, it's sunny! (今日はとても幸せです、天気も晴れています) | ポジティブ |
| I am frustrated by this rush hour traffic! (この通勤ラッシュで苛立っています) | 否定的 |
| Spark 上の Azure AI サービスは悪くありません | 中立的 |
Language Detector
Language Detector では、テキスト入力が評価され、各ドキュメントについて言語識別子と、分析の強度を示すスコアが返されます。 この機能は、言語が不明な任意のテキストを取集するコンテンツ ストアに役立ちます。 有効な言語の一覧については、「Text Analytics API でサポートされている言語」を参照してください。
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
予想される結果
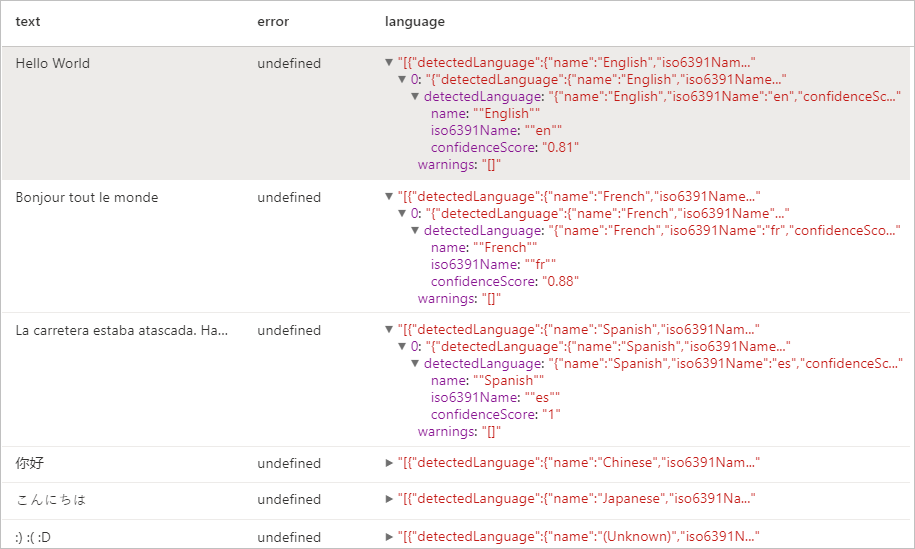
Entity Detector
Entity Detector は、既知のナレッジ ベースへのリンクを含む認識されたエンティティの一覧を返します。 有効な言語の一覧については、「Text Analytics API でサポートされている言語」を参照してください。
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
予想される結果
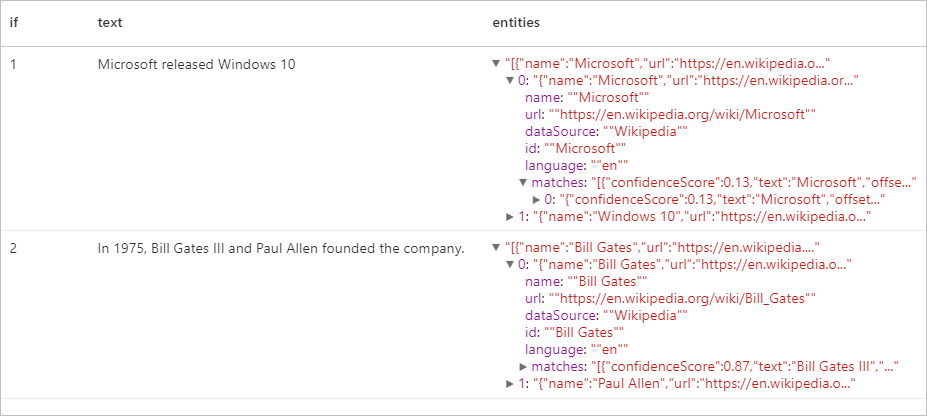
キー フレーズ抽出
キー フレーズ抽出は、非構造化テキストを評価し、キー フレーズのリストを返します。 この機能は、ドキュメントのコレクション内の要点をすばやく特定する必要がある場合に便利です。 有効な言語の一覧については、「Text Analytics API でサポートされている言語」を参照してください。
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
予想される結果
| text | keyPhrases |
|---|---|
| Hello world. これは、私が気に入っている入力テキストです。 | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
名前付きエンティティの認識 (NER)
固有表現認識 (NER) とは、人、場所、イベント、製品や組織などの事前に定義されているさまざまなテキスト形式のエンティティを、クラスまたは種類に分類する機能です。 有効な言語の一覧については、「Text Analytics API でサポートされている言語」を参照してください。
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
予想される結果
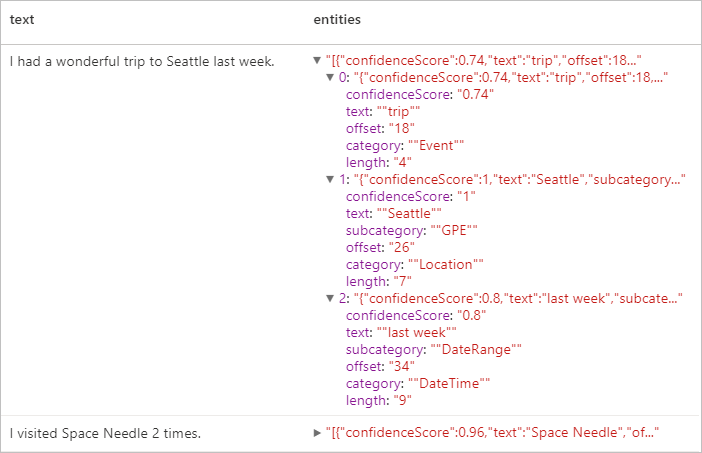
個人を特定できる情報 (PII) V3.1
PII 機能は NER の一部であり、電話番号、メール アドレス、郵送先住所、パスポート番号など、テキスト内で個人に関連付けられている機密性の高いエンティティを識別し、編集することができます。 有効な言語の一覧については、「Text Analytics API でサポートされている言語」を参照してください。
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
予想される結果
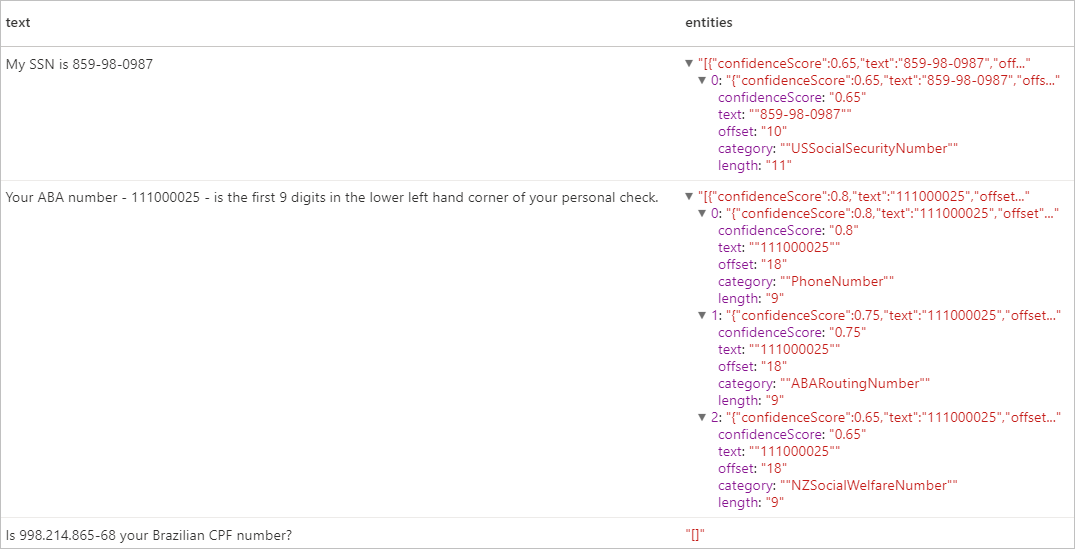
リソースをクリーンアップする
Spark インスタンスがシャットダウンされるようにするには、接続されているセッション (ノートブック) を終了します。 プールは、Apache Spark プールに指定されているアイドル時間に達したときにシャットダウンされます。 また、ノートブックの右上にあるステータス バーから [セッションの停止] を選択することもできます。
![ステータス バーの [セッションの停止] ボタンを示すスクリーンショット。](media/tutorial-build-applications-use-mmlspark/stop-session.png)