Azure Stream Analytics のクエリのトラブルシューティング
この記事では、Stream Analytics のクエリの開発に関する一般的な問題と、そのトラブルシューティングの方法について説明します。
この記事では、Azure Stream Analytics クエリの開発に関する一般的な問題、クエリの問題のトラブルシューティングの方法、および問題を修正する方法について説明します。 多くのトラブルシューティングの手順では、Stream Analytics ジョブに対してリソース ログを有効にする必要があります。 リソース ログが有効になっていない場合は、「リソース ログを使用した Azure Stream Analytics のトラブルシューティング」を参照してください。
クエリが予想される出力を生成しない
ローカルでテストしてエラーを調査します。
- Azure portal の [クエリ] タブで [テスト] を選択します。 ダウンロードしたサンプル データを使用してクエリをテストします。 すべてのエラーを調査し、修正を試みます。
- また、Visual Studio の Azure Stream Analytics ツール、または Visual Studio Code を使用して、クエリをローカルでテストすることもできます。
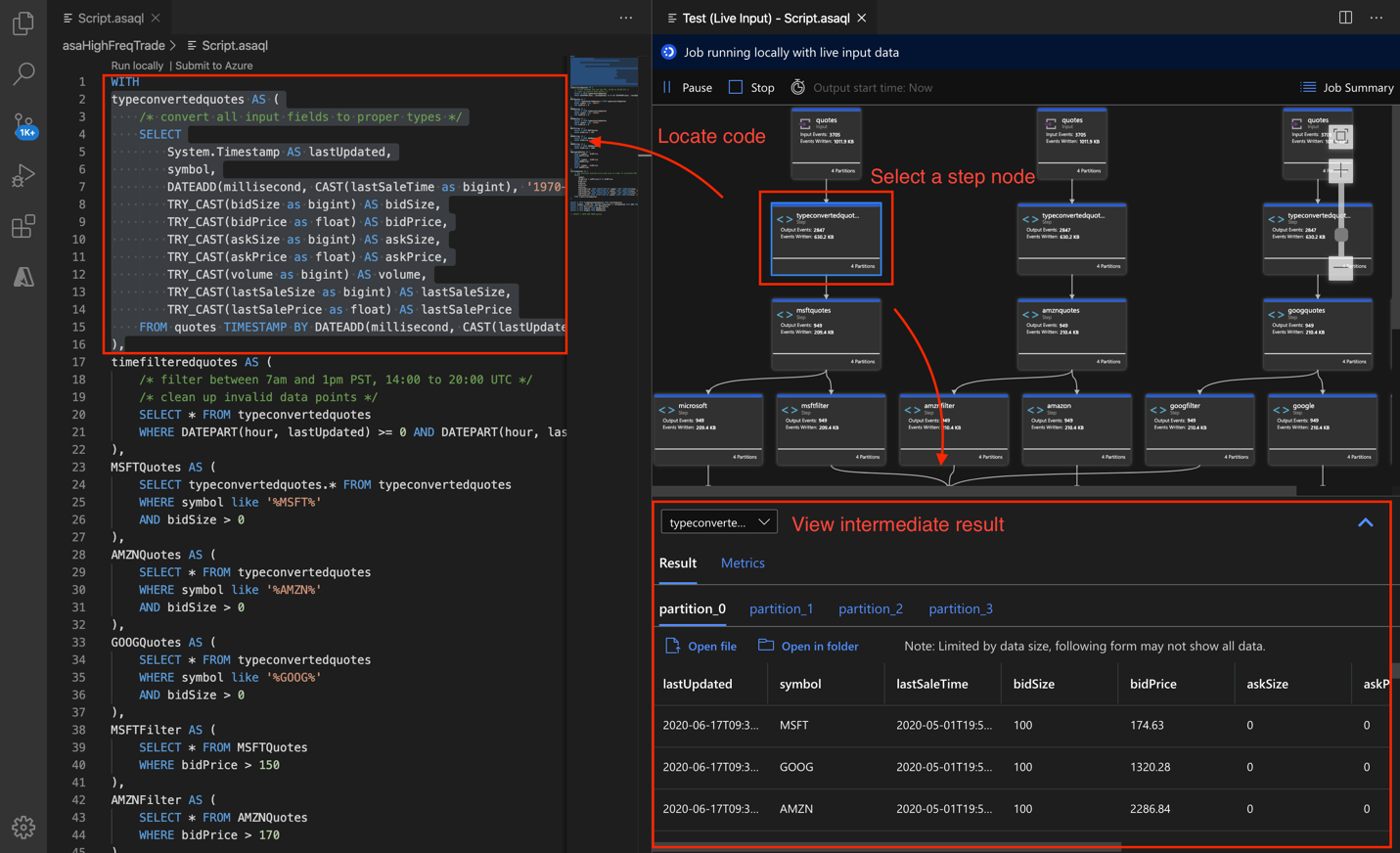
Visual Studio Code の Azure Stream Analytics ツールで、ジョブ ダイアグラムを使用して段階を追ってローカルでクエリをデバッグします。 ジョブ ダイアグラムには、入力ソース (イベント ハブ、IoT Hub など) のデータが複数のクエリ手順を介して最終的に出力シンクまでどのように流れるかが示されます。 各クエリ ステップは、WITH ステートメントを使用してスクリプトに定義された一時的結果セットにマップされます。 各中間結果セット内のデータとメトリックを表示して、問題の原因を見つけることができます。
Timestamp By を使用する場合は、イベントのタイムスタンプがジョブの開始時刻より後であることを確認します。
よくある次のような問題を解消する。
イベント順序ポリシーが期待どおりに構成されていることを確認します。 [設定] に移動し、[イベント順序] を選択します。 このポリシーは、 [テスト] ボタンを使用してクエリをテストする場合には適用 "されません"。 この結果が、ブラウザーでテストする場合と、運用環境でジョブを実行する場合の相違点の 1 つです。
アクティビティとリソース ログを使用したデバッグ:
- アクティビティ ログを使用してフィルター処理を行い、エラーを特定してデバッグします。
- ジョブのリソース ログを使用してエラーを特定し、デバッグします。
リソース使用率が高い
Azure Stream Analytics で並列処理を活用していることを確認します。 入力パーティションの構成と分析クエリ定義のチューニングによって、Stream Analytics ジョブのクエリ並列処理を使用してスケーリングすることをお勧めします。
リソース使用率が常に 80% を超え、透かしの遅延が増加し、バックログされたイベントの数が増加している場合は、ストリーミング ユニットを増やすことを検討してください。 使用率が高い場合は、最大数に近い割り当てリソースがジョブによって使用されていることを示します。
クエリを段階的にデバッグする
リアルタイムのデータ処理では、クエリの実行中にデータの状況を把握することが役に立つ場合があります。 これは、Visual Studio のジョブ ダイアグラムを使用して確認できます。 Visual Studio がない場合は、中間データを出力するための追加の手順を実行できます。
Azure Stream Analytics ジョブの入力またはステップは複数回読み取ることができるため、追加の SELECT INTO ステートメントを記述することができます。 これを実行すると、中間データがストレージに出力され、データの正確性を確認できるようになります。これは、プログラムをデバッグする際に "watch 変数" によって行われる確認とまったく同じです。
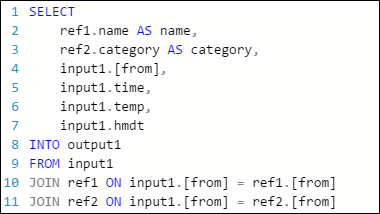
Azure Stream Analytics ジョブの次のサンプル クエリには、1 つのストリーム入力と 2 つの参照データ入力があり、Azure Table Storage に出力が行われます。 このクエリはイベント ハブと 2 つの参照 BLOB からのデータを結合し、名前とカテゴリの情報を取得します。
ジョブが実行中なのに出力でイベントが生成されていないことに注意してください。 次に示す [監視] タイルでは、入力からデータが生成中であることがわかります。しかし、JOIN のどのステップが原因ですべてのイベントが欠落したのかはわかりません。
![Stream Analytics の [監視] タイル](media/stream-analytics-select-into/stream-analytics-select-into-monitor.png)
この状況では、いくつかの SELECT INTO ステートメントを追加して、JOIN の中間結果と入力から読み取られたデータの "ログを記録" することができます。
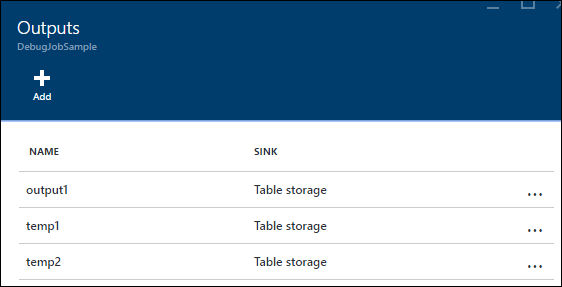
この例では、2 つの "一時的な出力" を新しく追加しました。これらの出力には任意のシンクを使用してかまいません。 ここでは例として Azure Storage を使用します。
クエリは次のように書き換えることができます。
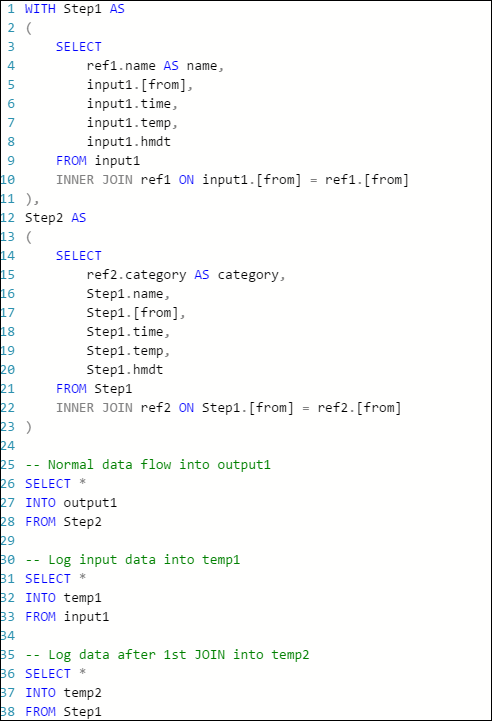
もう一度ジョブを開始して、数分間実行します。 temp1 と temp2 の各クエリによって、Visual Studio Cloud Explorer で次のテーブルが生成されます。
temp1 テーブル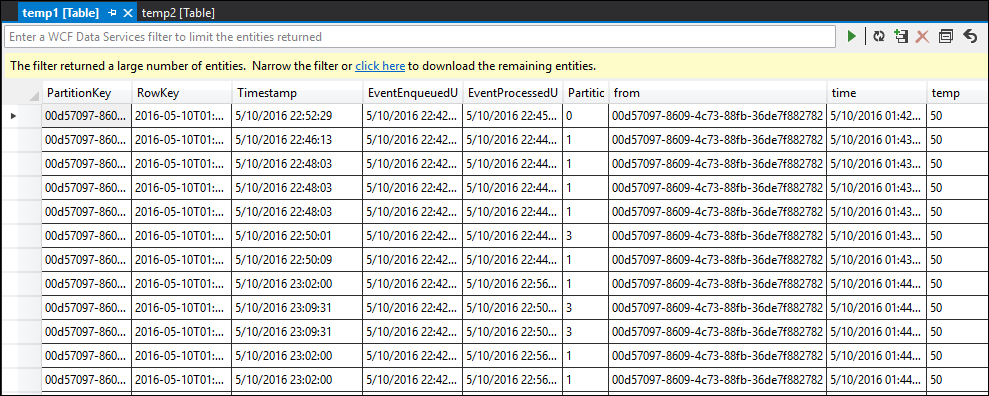
temp2 テーブル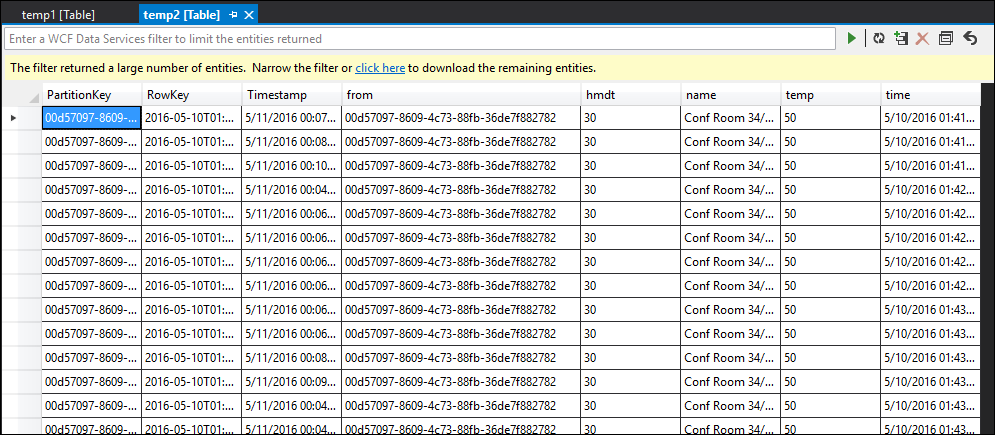
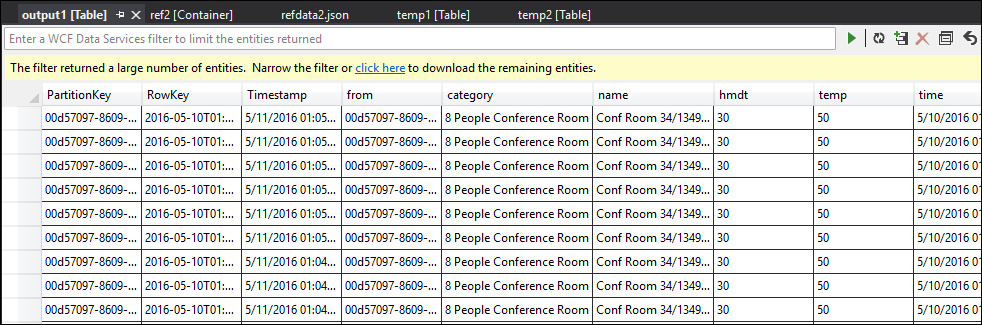
ご覧のとおり、temp1 と temp2 のどちらにもデータがあり、temp2 では名前列が正しく入力されています。 しかし出力には依然としてデータがなく、何らかの問題が発生していることがわかります。
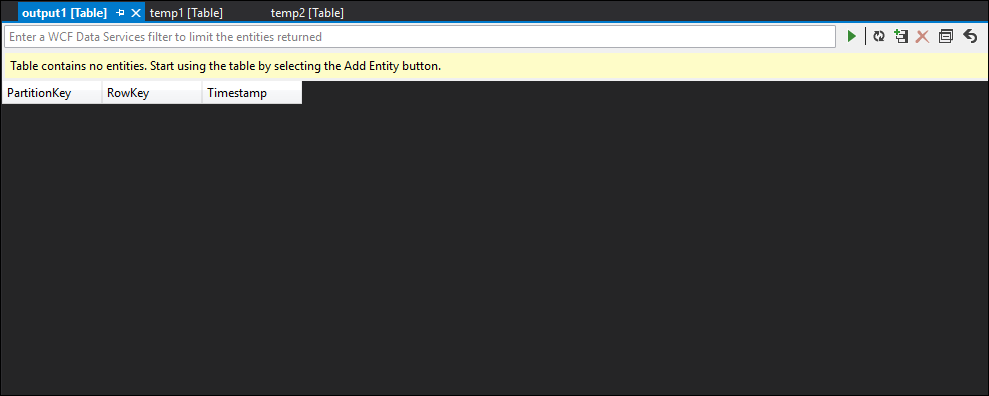
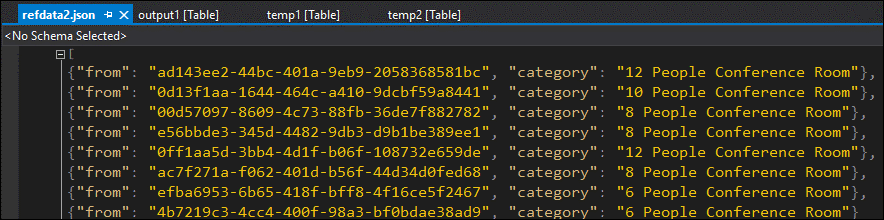
データをサンプリングすることで、2 番目の JOIN に問題があることがほぼ確実にわかります。 BLOB から参照データをダウンロードして確認できます。
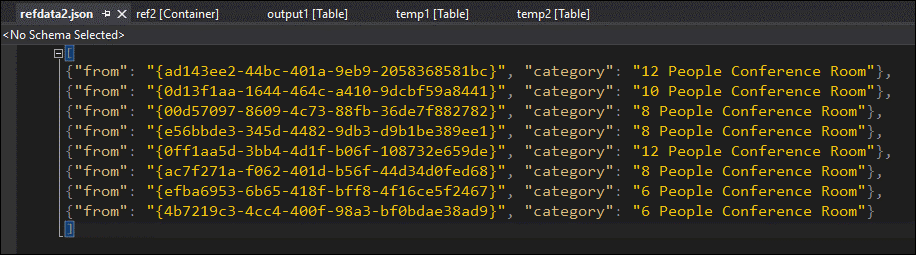
ご覧のとおり、この参照データの GUID の形式が temp2 の "from" 列の形式と異なります。 これが、データが想定どおりに output1 に届かなかった原因です。
データ形式を修正して参照 BLOB にアップロードし、やり直すことができます。
今度は、出力のデータが想定どおりに書式設定されて入力されます。
ヘルプの参照
詳細については、Azure Stream Analytics に関する Microsoft Q&A 質問ページを参照してください。