ジョブ シミュレーションを使用してクエリを最適化する
Azure Stream Analytics (ASA) ジョブのパフォーマンスを向上させる方法の 1 つが、クエリに並列処理を適用することです。 この記事では、Azure portal と Visual Studio Code (VS Code) のジョブ シミュレーションを使用して、Stream Analytics ジョブに対するクエリの並列処理を評価する方法について説明します。 さまざまな数のストリーミング ユニットについて、クエリの実行を視覚化し、編集候補に基づいてクエリの並列処理を改善する方法について説明します。
並列クエリとは
クエリの並列処理では、複数のプロセス (またはストリーミング ノード) を作成してクエリのワークロードを分割し、並列で実行します。 これにより、クエリの全体的な実行時間が大幅に短縮されるため、必要なストリーミング時間が削減されます。
ジョブを並列にするには、すべての入力、すべての出力、すべてのクエリ ステップをアラインし、同じパーティション キーを使用する必要があります。 クエリ ロジックのパーティション分割は、集約のために使われるキー (GROUP BY) によって決まります。
クエリの並列化の詳細については、「Azure Stream Analytics でのクエリの並列処理の活用」を参照してください。
VS Code でジョブ シミュレーションを使用する
ジョブ シミュレーション機能では、Azure でのジョブによるトポロジの実行方法をシミュレートします。 このチュートリアルでは、編集候補に基づいてクエリのパフォーマンスを向上させ、並列で実行する方法について説明します。 例として、イベント ハブから入力データを受け取り、結果を別のイベント ハブに送信する非並列ジョブを使用しています。
前提条件:
- VS Code 用 ASA Tools 拡張機能。 まだインストールしていない場合は、このガイドに従ってインストールしてください。
- Stream Analytics ジョブのライブ入力とライブ出力を構成します。
- ライブ入力とライブ出力をクエリに含める必要があります。
注意
ジョブ シミュレーションでは、ローカルで入力および出力されたジョブ実行トポロジをシミュレートすることはできません。 シミュレーション中に出力先にデータが送信されることはありません。
VS Code で ASA プロジェクトを開きます。 クエリ ファイル *.asaql に移動し、[Simulate job](ジョブのシミュレート) を選択してジョブ シミュレーションを開始します。

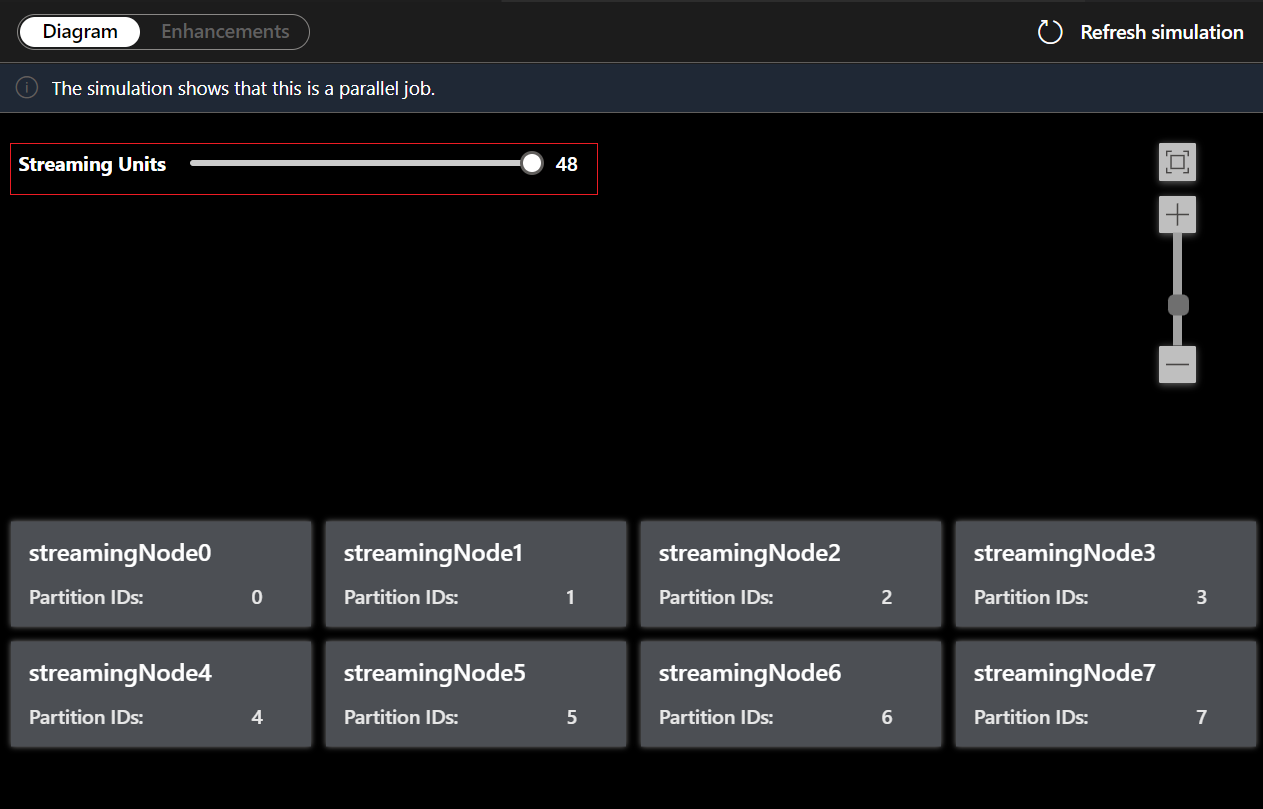
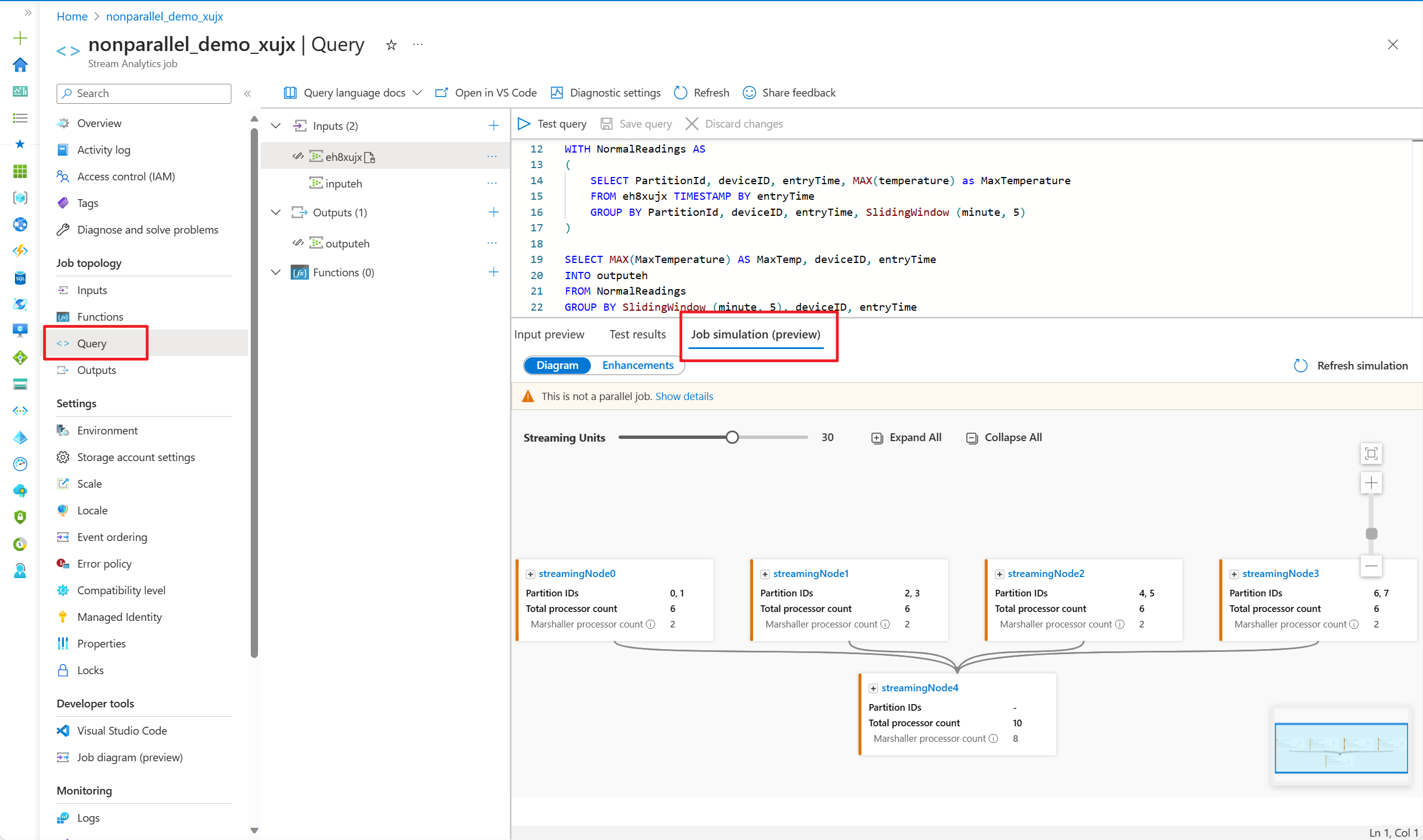
[図] タブに、ジョブに割り当てられたストリーミング ノードの数と、各ストリーミング ノード内のパーティションの数が表示されます。 次のスクリーンショットは、ノード間でデータが流れている非並列ジョブの例です。

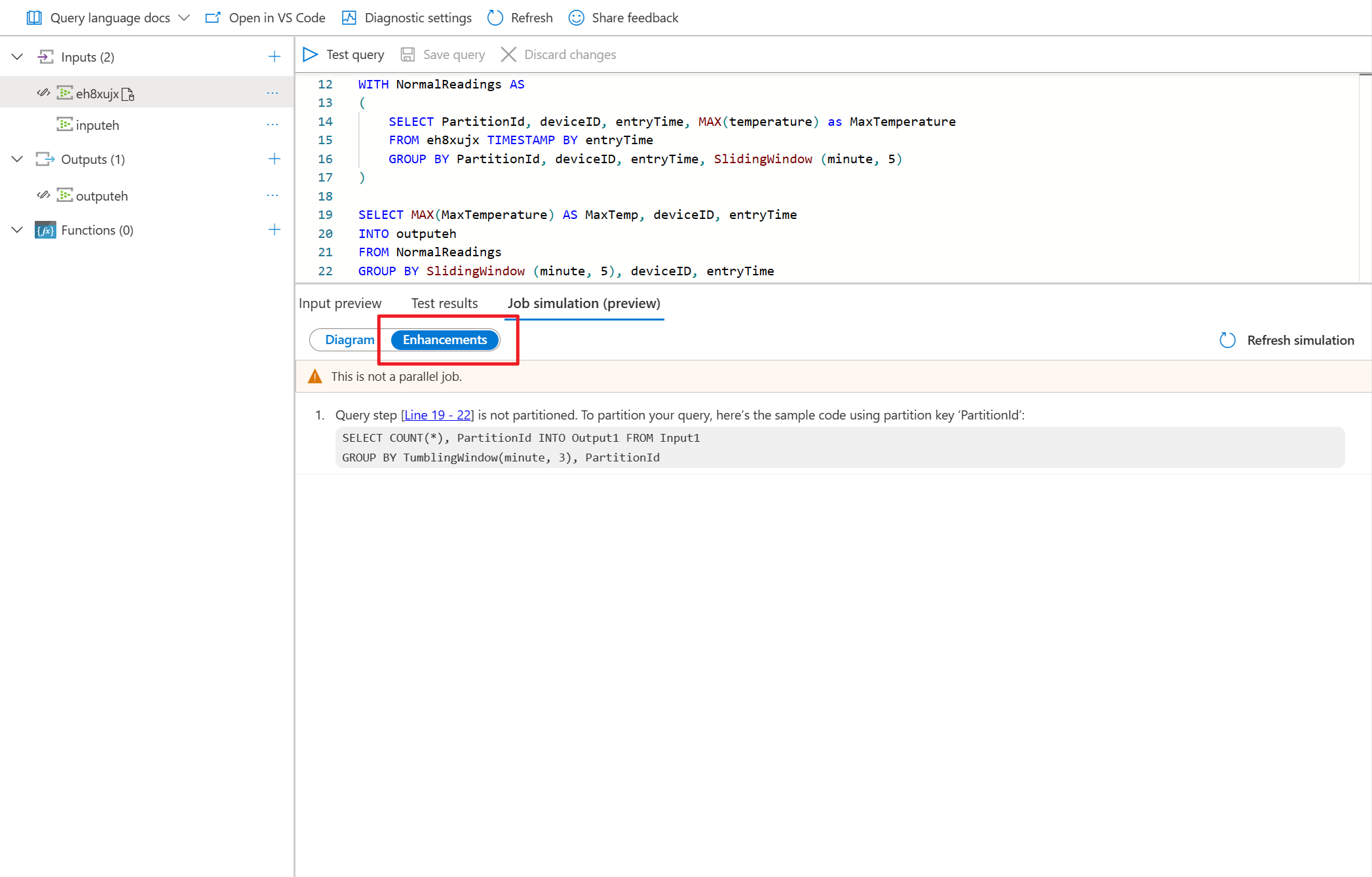
このクエリは並列でないため、[拡張] タブを選択して、クエリ処理を向上させる推奨事項を表示させることができます。

拡張機能の一覧でクエリ ステップを選択すると、対応する行が強調表示され、候補に基づいてクエリを編集できます。

Note
これらは、クエリの並列処理を改善するための編集候補です。 ただし、すべてのパーティションで集計関数を使用している場合、並列クエリの使用を、シナリオに適用できない可能性があります。
この例では、PartitionId を行 22 に追加し、変更を保存します。 次に、[シミュレーションを最新の情報に更新] を使用して、新しいダイアグラムを取得できます。

ストリーミング ユニットを調整して、ストリーミング ノードがさまざまな SU でどのように割り当てられるかをシミュレートすることもできます。 ワークロードを処理するために必要な SU の数を把握できます。






Azure portal でジョブ シミュレーションを使用する
- Azure portal でクエリ エディターに移動し、下部ウィンドウの [Job simulation](ジョブ シミュレーション) を選択します。 クエリと定義済みのストリーミング ユニットに基づいて、トポロジを実行しているジョブをシミュレートします。
- [拡張] を選択して、クエリの並列処理を向上させるための推奨事項を表示させます。
- ストリーミング ユニットを調整して、ワークロードの処理に必要な SU の数を確認します。




プロセッサ レベルの図
ジョブのトポロジをシミュレートするようにストリーミング ユニットを調整したら、ストリーミング ノードを展開して、プロセッサ レベルでデータがどのように処理されているかを確認できます。

プロセッサ レベルの図では、次のことができます。
- 各ストリーミング ノードで入力パーティションがどのように割り当てられ、処理されているかを確認します。
- 各コンピューティング プロセッサの時間シフトを確認します。
- 入力プロセッサと出力プロセッサが並列に配置されるかどうかに関する情報を提供します。
プロセッサをクエリ ステップにマップするには、図をダブルクリックします。 この機能は、集計を行うクエリ ステップを特定するのに役立ちます。

機能強化の候補
拡張機能の説明を次に示します。
| Type | 意味 |
|---|---|
| カスタマイズされたパーティションはサポートされていません | 入力 'xxx' パーティション キーを 'xxx' に変更します。 |
| パーティションの数が一致しません | 入力と出力には、同じ数のパーティションが必要です。 |
| パーティション キーが一致しません | 入力、出力、および各クエリ ステップでは、同じパーティション キーを使用する必要があります。 |
| 入力パーティションの数が一致しません | すべての入力には同じ数のパーティションが必要です。 |
| 入力パーティション キーが一致しません | すべての入力で同じパーティション キーを使用する必要があります。 |
| 互換性レベルが低いです | JobConfig.json ファイルの CompatibilityLevel をアップグレードします。 |
| 出力パーティション キーが見つかりません | 出力には指定されたパーティション キーを使用する必要があります。 |
| カスタマイズされたパーティションはサポートされていません | 定義済みのパーティション キーのみを使用できます。 |
| クエリ ステップでパーティションを使用していません | クエリで PARTITION BY 句が使用されていません。 |
次の手順
クエリの並列化とジョブ ダイアグラムの詳細については、次のチュートリアルを参照してください。