チュートリアル:Databricks Delta テーブルを更新する Data Lake キャプチャ パターンを実装する
このチュートリアルでは、階層型名前空間を持つストレージ アカウント内でイベントを処理する方法について説明します。
販売注文を記述したコンマ区切り値 (csv) ファイルをアップロードすることで、ユーザーが Databricks Delta テーブルにデータを設定できるようにするための小規模なソリューションを構築します。 このソリューションを構築するには、Event Grid サブスクリプション、Azure 関数、および Azure Databricks 内のジョブを 1 つに接続します。
このチュートリアルでは、次のことについて説明します。
- Azure 関数を呼び出す Event Grid サブスクリプションを追加します。
- イベントから通知を受信し、Azure Databricks 内でジョブを実行する Azure 関数を作成します。
- ストレージ アカウントに配置されている Databricks Delta テーブルに顧客注文を挿入する Databricks ジョブを作成します。
このソリューションの構築は、Azure Databricks ワークスペースから始めて、逆の順序で行います。
前提条件
階層型名前空間 (Azure Data Lake Storage) を持つストレージ アカウントを作成します。 このチュートリアルでは、
contosoordersという名前のストレージ アカウントを使用します。「Azure Data Lake Storage で使用するストレージ アカウントを作成する」を参照してください。
ユーザー アカウントにストレージ BLOB データ共同作成者ロールが割り当てられていることを確認します。
サービス プリンシパルを作成し、クライアント シークレットを作成し、サービス プリンシパルにストレージ アカウントへのアクセス権を付与します。
「チュートリアル: Azure Data Lake Storage に接続する」 (手順 1 から 3) を参照してください。 これらの手順を完了したら、テナント ID、アプリ ID、クライアント シークレットの値をテキスト ファイルに貼り付けてください。 これらはすぐに必要になります。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
販売注文を作成する
まず、販売注文を記述した csv ファイルを作成し、そのファイルをストレージ アカウントにアップロードします。 後で、このファイルのデータを使用して、Databricks Delta テーブルの最初の行に値を設定します。
Azure Portal で新しいストレージ アカウントに移動します。
[ストレージ ブラウザー]->[BLOB コンテナー] - >[コンテナーの追加] を選択し、data という名前の新しいコンテナーを作成します。
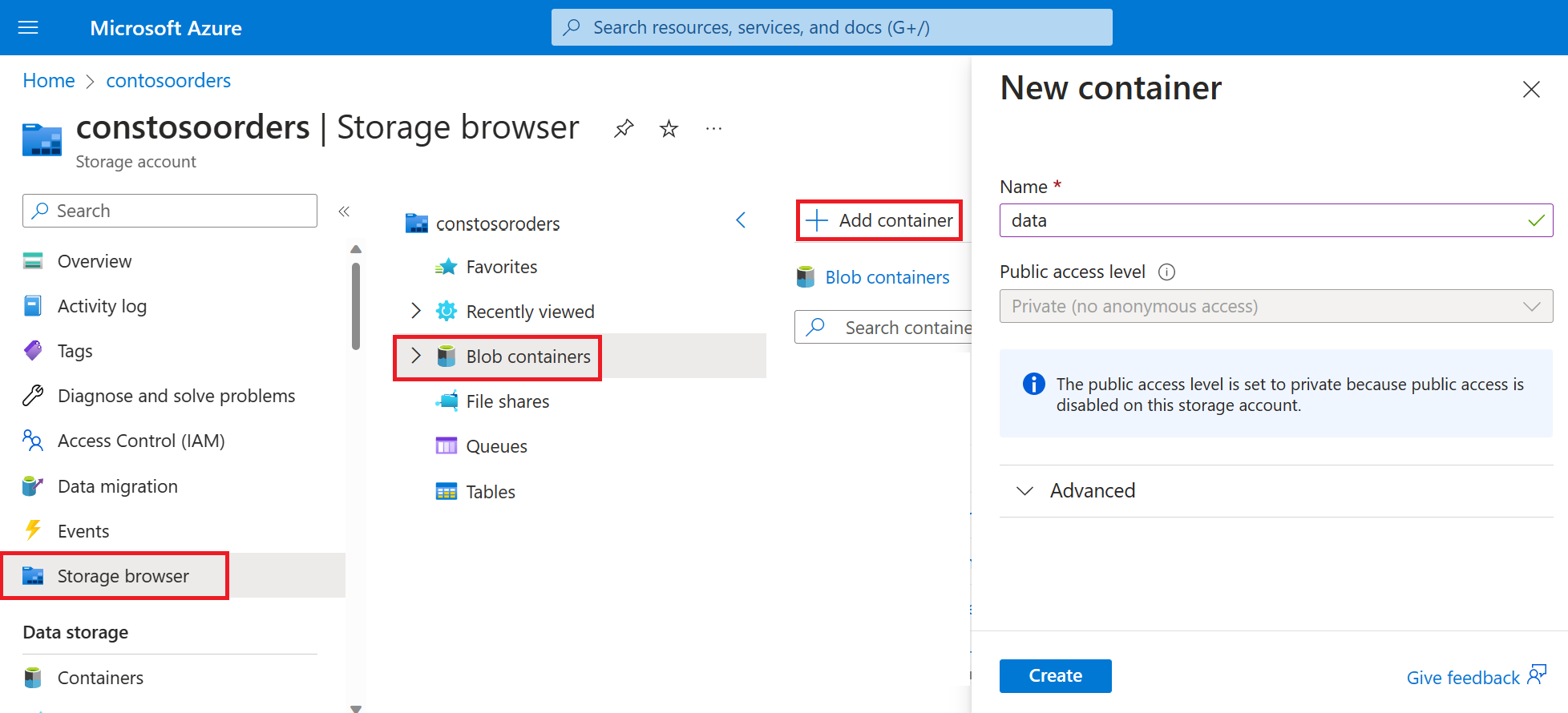
data コンテナーで、input という名前のディレクトリを作成します。
次のテキストをテキスト エディターに貼り付けます。
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United Kingdomこのファイルをローカル コンピューターに保存し、data.csv という名前を付けます。
ストレージ ブラウザーで、このファイルを input フォルダーにアップロードします。
Azure Databricks でジョブを作成する
このセクションでは、以下のタスクを実行します。
- Azure Databricks ワークスペースを作成する。
- Notebook を作成します。
- Databricks Delta テーブルを作成し、データを設定します。
- Databricks Delta テーブルに行を挿入するコードを追加します。
- ジョブを作成します。
Azure Databricks ワークスペースを作成する
このセクションでは、Azure Portal を使って Azure Databricks ワークスペースを作成します。
Azure Databricks ワークスペースを作成する。 そのワークスペースに
contoso-ordersという名前を付けます。 「Azure Databricks ワークスペースを作成する」をご覧ください。クラスターを作成する。 クラスターに
customer-order-clusterという名前を付けます。 クラスターの作成に関する記事を参照してください。Notebook を作成します。 ノートブックに
configure-customer-tableという名前を付け、そのノートブックの既定の言語として Python を選択します。 「ノートブックを作成する」を参照してください。
Databricks Delta テーブルを作成してデータを設定する
作成したノートブックで、次のコード ブロックをコピーして最初のセルに貼り付けます。ただし、このコードはまだ実行しないでください。
このコード ブロックの
appId、password、およびtenantのプレースホルダー値を、このチュートリアルの前提条件を満たすための作業で収集した値に置き換えます。dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'このコードによって、source_file という名前のウィジェットが作成されます。 後で、このコードを呼び出し、そのウィジェットにファイル パスを渡す Azure 関数を作成します。 また、このコードは、ストレージ アカウントを使用してサービス プリンシパルを認証し、他のセルで使用する変数をいくつか作成します。
Note
運用設定では、認証キーを Azure Databricks に格納することを検討してください。 次に、認証キーではなくルック アップ キーをコード ブロックに追加します。
たとえば、spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>")というコード行を使用する代わりに、spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>"))というコード行を使用します。
このチュートリアルの完了後、Azure Databricks Web サイトの記事「Azure Data Lake Storage」で、このアプローチの例を参照してください。Shift + Enter キーを押して、このブロック内のコードを実行します。
次のコード ブロックをコピーして別のセルに貼り付け、Shift + Enter キーを押して、このブロックのコードを実行します。
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))このコードは、ストレージ アカウントに Databricks Delta テーブルを作成し、前にアップロードした csv ファイルからいくつかの初期データを読み込みます。
このコード ブロックが正常に実行された後、このコード ブロックをノートブックから削除します。
Databricks Delta テーブルに行を挿入するコードを追加する
次のコード ブロックをコピーして、別のセルに貼り付けます。ただし、このセルは実行しないでください。
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")このコードは、csv ファイルのデータを使用して、一時テーブル ビューにデータを挿入します。 その csv ファイルへのパスは、前の手順で作成した入力ウィジェットから取得されます。
次のコード ブロックをコピーして別のセルに貼り付けます。 このコードにより、一時テーブル ビューの内容を Databricks Delta テーブルとマージします。
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
ジョブを作成する
先ほど作成したノートブックを実行するジョブを作成します。 後で、イベントが発生したときにこのジョブを実行する Azure 関数を作成します。
[新規]->[ジョブ]を選択します。
ジョブに名前を付け、作成したノートブックを選択してクラスター化します。 次に、[作成] を選択してジョブを作成します。
Azure Function の作成
ジョブを実行する Azure 関数を作成します。
Azure Databricks ワークスペースの上部バーで、目的の Azure Databricks ユーザー名をクリックし、次にドロップダウン リストから [ユーザー設定] を選択します。
[アクセス トークン] タブで、[新しいトークンの生成] を選択します。
表示されたトークンをコピーしてから、[完了] をクリックします。
Databricks ワークスペースの上隅で、人のアイコンを選択し、 [ユーザー設定] を選択します。

[新しいトークンの生成] を選択し、[生成] を選択します。
トークンは安全な場所にコピーしてください。 Azure 関数では、Databricks に認証してジョブを実行するためにこのトークンが必要です。
Azure portal のメニューまたは [ホーム] ページから [リソースの作成] を選択します。
[新規] ページで、 [計算]>、 [関数アプリ] の順に選択します。
[関数アプリを作成する] ページの [基本] タブで、リソース グループを選択し、次の設定を変更または確認します。
設定 値 関数アプリ名 contosoorder ランタイム スタック .NET 発行 コード オペレーティング システム Windows プランの種類 "従量課金 (サーバーレス)" [確認と作成] を選択し、次に [作成] を選択します。
デプロイが完了したら、[リソースに移動] を選択して関数アプリの概要ページを開きます。
[設定] グループで、[構成] を選択します。
[アプリケーションの設定] ページで、 [新しいアプリケーション設定] を選択して各設定を追加します。

以下の設定を追加します。
設定名 Value DBX_INSTANCE Databricks ワークスペースのリージョン。 例: westus2.azuredatabricks.netDBX_PAT 前に生成した個人用アクセス トークン。 DBX_JOB_ID 実行中のジョブの識別子。 [保存] を選択して、これらの設定をコミットします。
[関数] グループで [関数] を選択し、[作成] を選択します。
[Azure Event Grid Trigger](Azure Event Grid トリガー) を選択します。
Microsoft.Azure.WebJobs.Extensions.EventGrid 拡張機能のインストールを求めるメッセージが表示されたら、インストールします。 インストールが必要な場合、関数を作成するには、 [Azure Event Grid Trigger](Azure Event Grid トリガー) を再度選択する必要があります。
[新しい関数] ウィンドウが表示されます。
[新しい関数] ウィンドウで、関数に UpsertOrder という名前を付け、[作成] を選択します。
コード ファイルの内容を次のコードに置き換え、[保存] を選択します。
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
このコードは、発生したストレージ イベントに関する情報を解析し、イベントをトリガーしたファイルの URL を含む要求メッセージを作成します。 この関数は、前に作成した source_file ウィジェットに、メッセージの一部として値を渡します。 この関数コードは、Databricks ジョブにメッセージを送信し、前に取得したトークンを認証として使用します。
Event Grid のサブスクリプションを作成する
このセクションでは、ファイルがストレージ アカウントにアップロードされたときに Azure 関数を呼び出す Event Grid サブスクリプションを作成します。
[統合] を選択し、[統合] ページで [Event Grid トリガー] を選択します。
[トリガーの編集] ウィンドウで、イベントに
eventGridEventという名前を付け、[イベント サブスクリプションの作成] を選択します。注意
名前
eventGridEventは、Azure 関数に渡される名前付きパラメーターと一致します。[イベント サブスクリプションの作成] ページの [基本] タブで、次の設定を変更または確認します。
設定 値 Name contoso-order-event-subscription トピックの種類 ストレージ アカウント ソース リソース contosoorders [システム トピック名] <create any name>イベントの種類のフィルター 作成された BLOB、および削除された BLOB [作成] ボタンを選択します。
Event Grid サブスクリプションをテストする
customer-order.csvという名前のファイルを作成し、そのファイルに次の情報を貼り付けて、ローカル コンピューターに保存します。InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneStorage Explorer で、このファイルを自分のストレージ アカウントの input フォルダーにアップロードします。
ファイルをアップロードすると、Microsoft.Storage.BlobCreated イベントが発生します。 Event Grid は、そのイベントのすべてのサブスクライバーに通知を発信します。 ここでは、Azure 関数が唯一のサブスクライバーです。 Azure 関数は、イベント パラメーターを解析して、発生したイベントを特定します。 その後、ファイルの URL を Databricks ジョブに渡します。 Databricks ジョブはファイルを読み取り、ストレージ アカウントにある Databricks Delta テーブルに行を追加します。
ジョブが成功したかどうかを確認するには、ジョブの実行を表示します。 完了状態が表示されます。 ジョブの実行を表示する方法の詳細については、「ジョブの実行を表示する」を参照してください
新しいワークブック セルで、セル内のこのクエリを実行して、更新された Delta テーブルを表示します。
%sql select * from customer_data返されるテーブルには、最新のレコードが表示されます。

このレコードを更新するには、
customer-order-update.csvという名前のファイルを作成し、そのファイルに次の情報を貼り付けて、ローカル コンピューターに保存します。InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra Leoneこの CSV ファイルは、前出のファイルとほぼ同じものですが、発注数量が
228から22に変更されています。Storage Explorer で、このファイルを自分のストレージ アカウントの input フォルダーにアップロードします。
selectクエリを再実行して、更新された Delta テーブルを表示します。%sql select * from customer_data返されるテーブルには、更新後のレコードが表示されます。

リソースをクリーンアップする
リソース グループおよび関連するすべてのリソースは、不要になったら削除します。 これを行うには、ストレージ アカウントのリソース グループを選択し、 [削除] を選択してください。