Service Fabric クラスターの均衡をとる
Service Fabric クラスター リソース マネージャーは、動的な負荷の変更、ノードやサービスの追加や削除への応答をサポートしています。 また、制約違反を自動的に修正し、必要に応じてクラスターを再調整することもできます。 このような操作はどのくらいの頻度で実行されるでしょうか。また、何によってトリガーされるでしょうか。
Cluster Resource Manager が実行する作業には、3 つのカテゴリがあります。
- 配置: この段階では、不足している任意のステートフル レプリカまたはステートレスなインスタンスの配置が処理されます。 配置には、新しいサービスと、失敗したステートフルなレプリカやステートレスなインスタンスの処理の両方が含まれます。 レプリカまたはインスタンスの削除はここで処理されます。
- 制約チェック: この段階では、システム内のさまざまな配置の制約 (ルール) 違反の確認および修正が行われます。 ルールとは、たとえば、ノードに過剰な負荷がかかっていないこと、およびサービスを配置するうえでの制約が満たされていることを確認することです。
- 分散: この段階では、さまざまなメトリックの構成済みの望ましい均衡レベルを基準に、再調整が必要であるかが確認されます。 必要な場合、よりクラスターの均衡をとる編成が検出されます。
クラスター リソース マネージャーのタイマーを構成する
均衡化に関する最初のコントロールは、一連のタイマーです。 これらのタイマーによって、クラスター リソース マネージャーがクラスターを検査し、是正措置を実行する頻度が制御されます。
Cluster Resource Manager が行うことのできる、これらの異なる修正はいずれも、その頻度を制御する別々のタイマーによって管理されています。 それぞれのタイマーが作動したとき、タスクがスケジュールされます。 既定では、Resource Manager では次の処理が実行されます。
- 1/10 秒ごとに状態をスキャンして更新を適用する (例: ノードがダウンしたことを記録する)
- 配置チェック フラグを毎秒設定する
- 制約チェック フラグを毎秒設定する
- 分散フラグを 5 秒ごとに設定する
これらのタイマーを制御する構成例を次に示します。
ClusterManifest.xml:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="PLBRefreshGap" Value="0.1" />
<Parameter Name="MinPlacementInterval" Value="1.0" />
<Parameter Name="MinConstraintCheckInterval" Value="1.0" />
<Parameter Name="MinLoadBalancingInterval" Value="5.0" />
</Section>
スタンドアロン デプロイの ClusterConfig.json 経由または Azure でホストされたクラスターの Template.json 経由:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "PLBRefreshGap",
"value": "0.10"
},
{
"name": "MinPlacementInterval",
"value": "1.0"
},
{
"name": "MinConstraintCheckInterval",
"value": "1.0"
},
{
"name": "MinLoadBalancingInterval",
"value": "5.0"
}
]
}
]
現在、クラスター リソース マネージャーは、常に一度に 1 つずつ、順番にこれらの処理を実行します。 そのため、これらのタイマーを "最小間隔" と呼び、タイマーが切れたときに実行されるアクションを "設定フラグ" と呼びします。 たとえば、Cluster Resource Manager は保留中の要求を処理して、クラスターに分散処理を行う前にサービスを作成します。 指定されている既定の時間間隔でわかるように、クラスター リソース マネージャーは頻繁に実行する必要があるすべての処理をスキャンします。 その結果、通常、各手順で加えられる一連の変更は小規模になります。 小規模な変更を頻繁に実行することで、クラスターで発生する事象に Cluster Resource Manager が応答できます。 同じ種類のイベントの多くは同時に発生する傾向があるため、既定のタイマーにはバッチ処理がいくつか用意されています。
たとえば、ノードで障害が発生した場合、フォールト ドメイン全体を一度で処理することができます。 これらすべての障害は、PLBRefreshGap の次の状態更新時にキャプチャされます。 以降の配置、制約チェック、分散の実行中に、修正が決定されます。 既定では、Cluster Resource Manager は、クラスター内の何時間もの変更をスキャンしてすべての変更に一度に対処しようとするものではありません。 これにより、チャーンが突発的に発生することがあります。
また、クラスターが不均衡であるかどうかを Cluster Resource Manager が判定するには、追加の情報が必要です。 そのために、他に 2 つの構成があります (BalancingThresholds と ActivityThresholds)。
分散しきい値
分散しきい値は、再調整をトリガーする主要コントロールです。 メトリックの分散しきい値は 割合 で規定されます。 最も負荷がかかっているノードのメトリックの負荷を、最も負荷がかかっていないノードの負荷量で割ったものが、そのメトリックの分散しきい値を超える場合、クラスターは不均衡であると見なされます。 結果として、次回 Cluster Resource Manager のチェックが行われるときに分散処理がトリガーされます。 MinLoadBalancingInterval タイマーは、再調整が必要かどうかをクラスター リソース マネージャーでチェックする頻度を定義します。 チェックは、何かがおこる処理ではありません。
分散しきい値は、クラスター定義の一部としてメトリックごとに定義されます。 メトリックの詳細については、メトリックに関する記事を参照してください。
ClusterManifest.xml
<Section Name="MetricBalancingThresholds">
<Parameter Name="MetricName1" Value="2"/>
<Parameter Name="MetricName2" Value="3.5"/>
</Section>
スタンドアロン デプロイの ClusterConfig.json 経由または Azure でホストされたクラスターの Template.json 経由:
"fabricSettings": [
{
"name": "MetricBalancingThresholds",
"parameters": [
{
"name": "MetricName1",
"value": "2"
},
{
"name": "MetricName2",
"value": "3.5"
}
]
}
]
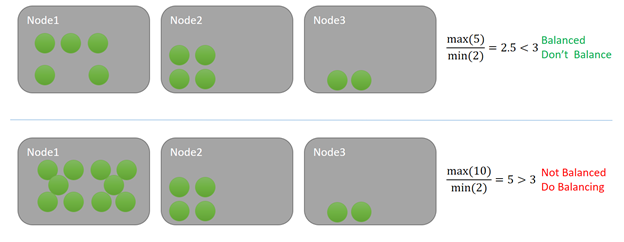
この例では、各サービスはいくつかのメトリックの 1 つの単位を消費しています。 一番上の例では、ノードに対する最大の負荷は 5 で最小は 2 です。 このメトリックの分散しきい値は 3 だとします。 クラスターの割合は 5/2 = 2.5 で、指定の分散しきい値 3 を下回るため、クラスターの均衡はとれています。 Cluster Resource Manager のチェックが行われるときに分散処理はトリガーされません。
下の例では、ノードに対する最大の負荷は 10 で最小は 2 であり、割合は 5 になります。 5 はそのメトリックの指定の分散しきい値 3 を上回ります。 その結果、再分散の実行が、次回の分散タイマーの作動時にスケジュールされます。 このような状況では、通常、一部の負荷がノード 3 に分散されます。 Service Fabric の Cluster Resource Manager は最長一致のアプローチを使用しないため、一部の負荷はノード 2 にも分散される可能性があります。
Note
"分散" は、クラスター内の負荷を管理するために 2 つの戦略を処理しています。 クラスター リソース マネージャーが使用する既定の戦略では、クラスター内のノード全体に負荷が分散されます。 もう 1 つの戦略は最適化です。 最適化は、同じ分散処理の実行時に実行されます。 分散および最適化の戦略は、同じクラスター内の複数のメトリックに使用できます。 1 つのサービスが分散メトリックと最適化メトリックの両方を使用することができます。 最適化メトリックの場合、クラスターの負荷の比率が分散しきい値を "下回った" 場合に再調整がトリガーされます。
分散しきい値を下回ることは明確な目標ではありません。 分散しきい値は、単なるトリガーです。 分散を実行すると、クラスター リソース マネージャーは、実行可能な改善がある場合はそれを決定します。 分散検索が開始されたからといって、何かが移動するとは限りません。 場合によっては、クラスターの均衡が取れていなくても、制約が多すぎて修正できないことがあります。 また、改善には移動が必要であり、移動にはコストがかかりすぎる場合があります。
アクティビティしきい値
ノードが相対的に不均衡であるにもかかわらず、クラスターの負荷 "全体" が低い場合があります。 負荷がないことは一時的な低下またはクラスターが新しくて現在起動中であることが原因の可能性もあります。 いずれの場合も、得られる成果はほとんどないため、時間をかけてクラスターを分散することはお勧めしません。 クラスターで分散処理を実行しても、ネットワークとコンピューティングのリソースを無駄に消費し、確実で大きな成果を挙げられないこともあります。 不要な移動を回避するために、アクティビティしきい値と呼ばれるもう 1 つのコントロールが用意されています。 アクティビティしきい値では、アクティビティに対して絶対的な下限を指定できます。 このしきい値を超えるノードがない場合、分散しきい値に達していても分散処理はトリガーされません。
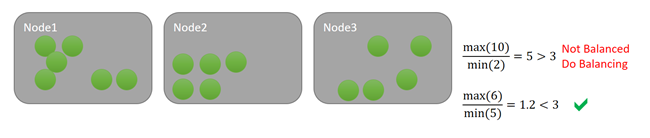
このメトリックに 3 の分散しきい値を保持しているとします。 また、1536 のアクティビティしきい値があるとします。 最初の例では、クラスターは分散しきい値に対しては不均衡ですが、アクティビティしきい値を満たすノードはないため、分散処理は発生しません。 下の例では、ノード 1 がアクティビティしきい値を超えています。 メトリックが分散しきい値とアクティビティしきい値の両方を超過しているため、分散処理がスケジュールされます。 例として、次の図を見てみましょう。

分散しきい値同様、アクティビティしきい値もクラスター定義でメトリックごとに定義します。
ClusterManifest.xml
<Section Name="MetricActivityThresholds">
<Parameter Name="Memory" Value="1536"/>
</Section>
スタンドアロン デプロイの ClusterConfig.json 経由または Azure でホストされたクラスターの Template.json 経由:
"fabricSettings": [
{
"name": "MetricActivityThresholds",
"parameters": [
{
"name": "Memory",
"value": "1536"
}
]
}
]
分散しきい値とアクティビティしきい値は、両方とも特定のメトリックに関連付けられています。同じメトリックが分散しきい値とアクティビティしきい値の両方を超えた場合にのみ分散処理がトリガーされます。
注意
指定しない場合、メトリックの分散しきい値は 1、アクティビティしきい値は 0 です。 つまり、クラスター リソース マネージャーは、指定された負荷について、そのメトリックが完全に分散された状態を保とうとします。 カスタム メトリックを使用している場合、メトリックの分散しきい値とアクティビティしきい値を明示的に定義することをお勧めします。
同時にサービスの均衡をとる
クラスターの均衡がとれているかどうかは、クラスター全体の判断です。 ただし、個々のサービス レプリカやインスタンスを移動することでこれを修正します。 ご理解いただけましたでしょうか。 1 つのノードで発生するメモリのスタックは、複数のレプリカやインスタンスが関与している場合があります。 不均衡を修正するには、不均衡なメトリックを使用するステートフル レプリカやステートレス インスタンスを移動する必要がある場合があります。
ただし、不均衡ではないサービスが移動されることもよくあります (前述のローカルとグローバルの重み付けの説明を参照してください)。 サービスすべてのメトリックのバランスがとれている場合に、サービスが移動されるのはなぜでしょうか。 例を見てみましょう。
- たとえば、サービス 1、サービス 2、サービス 3、サービス 4 という 4 つのサービスがあるとします。
- サービス 1 で報告されるメトリックは、メトリック 1 とメトリック 2 です。
- サービス 2 で報告されるメトリックは、メトリック 2 とメトリック 3 です。
- サービス 3 で報告されるメトリックは、メトリック 3 とメトリック 4 です。
- サービス 4 で報告されるメトリックは、メトリック 99 です。
実際には 4 つの独立したサービスがあるのではなく、関連している 3 つのサービスと、独立したサービスが 1 つあります。
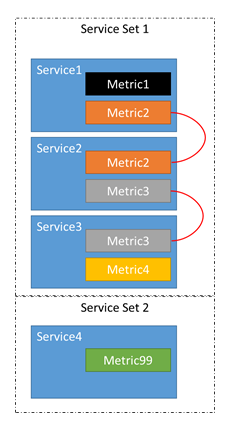
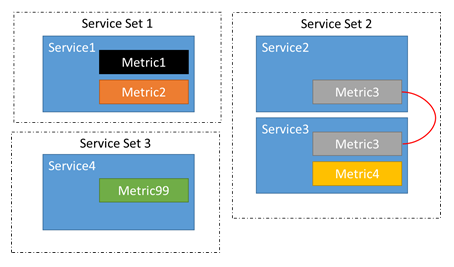
このチェーンがあるため、Metric1-4 が不均衡な場合、Service1-3 に属するレプリカやインスタンスが移動する可能性があります。 また、メトリック 1、2、または 3 の不均衡によってサービス 4 で移動が発生しないこともわかります。 サービス 4 に属するレプリカやインスタンスを移動しても、メトリック 1 から 3 の均衡にはまったく影響しないため、移動しても意味がありません。
クラスター リソース マネージャーは、関連するサービスを自動的に判別します。 サービスのメトリックを追加、削除、または変更すると、それらの関係に影響する可能性があります。 たとえば、分散処理を 2 回実行する間にサービス 2 が更新されてメトリック 2 が削除される可能性があります。 これによって、サービス 1 とサービス 2 の間のチェーンが崩れます。 2 グループの関連するサービスでなく、3 グループになります。
ノード タイプごとのクラスターの均衡化
ここまでのセクションで説明したように、再調整をトリガーする主要コントロールは、アクティビティしきい値、分散しきい値、タイマーです。 Service Fabric の Cluster Resource Manager では、ノード タイプごとにパラメーターを指定し、不均衡なノード タイプでのみ移動を許可することで、再調整のトリガーをより細かく制御できます。 ノード タイプごとに均衡化する主な利点は、他のノード タイプのパフォーマンスを低下させることなく、より厳密な分散規則を必要とするノード タイプのパフォーマンス向上が可能になることです。 この機能には、2 つの主要な部分があります。
- 不均衡の検出は、ノード タイプごとに行われます。 以前は、不均衡のグローバルな計算がノード タイプごとに計算されていました。 すべてのノード タイプで均衡がとれている場合、CRM で分散フェーズはトリガーされません。 それ以外の場合で、少なくとも 1 つのノード タイプが不均衡な場合は、分散フェーズが必要です。
- 分散では、不均衡なノード タイプでのみレプリカが移動され、他のノード タイプは分散フェーズの影響を受けません。
ノード タイプごとの均衡化がクラスターに与える影響
ノード タイプごとのクラスター均衡化の際、Service Fabric の Cluster Resource Manager によってノード タイプごとに不均衡状態が計算されます。 少なくとも 1 つのノード タイプが不均衡な場合、分散フェーズがトリガーされます。 分散フェーズでは、これらのノード タイプで分散が短期的に一時停止されている場合 (たとえば、以前の分散フェーズ以降に最小の分散間隔が経過していない場合) に、不均衡なノード タイプのレプリカは移動されません。 不均衡状態の検出では、従来のクラスター均衡化で既に利用されている一般的なメカニズムが使用されますが、構成の粒度と柔軟性が向上します。 ノード タイプごとの均衡化で不均衡を検出するために使用されるメカニズムを次の一覧に示します。
- ノード タイプごとのメトリック分散しきい値は、従来の均衡化で使用されるグローバルに定義された分散しきい値と同様の役割を持つ値です。 最小と最大のメトリック負荷の比率が、ノード タイプごとに計算されます。 あるノード タイプで、その比率がノード タイプの定義済み分散しきい値よりも高い場合、そのノード タイプは不均衡としてマークされます。 ノード タイプごとのメトリック アクティビティしきい値の構成について詳しくは、「ノード タイプごとの分散しきい値」セクションを参照してください。
- ノード タイプごとのメトリック アクティビティしきい値は、従来の均衡化で使用されるグローバルに定義されたアクティビティしきい値と同様の役割を持つ値です。 最大のメトリック負荷がノード タイプごとに計算されます。 あるノード タイプで、最大負荷がノード タイプの定義済みアクティビティしきい値よりも高い場合、そのノード タイプは不均衡としてマークされます。 ノード タイプごとのメトリック アクティビティしきい値の構成について詳しくは、「ノード タイプごとのアクティビティしきい値」セクションを参照してください。
- ノード タイプごとの最小分散間隔は、グローバルに定義された最小分散間隔と同様の役割を持ちます。 ノード タイプごとに、Cluster Resource Manager によって最後の分散のタイムスタンプが保持されます。 あるノード タイプで、定義済みの最小分散間隔内に連続する 2 回の分散フェーズを実行できませんでした。 ノード タイプごとの最小分散間隔の構成について詳しくは、「ノード タイプごとの最小分散間隔」セクションを参照してください。
ノード タイプごとの均衡化の説明
ノード タイプごとの均衡化を有効にするには、クラスター マニフェストでパラメーター SeparateBalancingStrategyPerNodeType を有効にする必要があります。 さらに、サブクラスター化の機能も有効にする必要があります。 機能を有効にするためのクラスター マニフェストの PlacementAndLoadBalancing セクションの例を次に示します。
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="SeparateBalancingStrategyPerNodeType" Value="true" />
<Parameter Name="SubclusteringEnabled" Value="true" />
<Parameter Name="SubclusteringReportingPolicy" Value="1" />
</Section>
スタンドアロン デプロイの ClusterConfig.json または Azure でホストされたクラスターの Template.json:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "SeparateBalancingStrategyPerNodeType",
"value": "true"
},
{
"name": "SubclusteringEnabled",
"value": "true"
},
{
"name": "SubclusteringReportingPolicy",
"value": "1"
},
]
}
]
前のセクションで説明したように、ノード タイプごとにしきい値と間隔を指定できます。 特定のパラメーターの更新について詳しくは、以下のセクションを参照してください。
ノード タイプごとの分散しきい値
分散構成から粒度を高めるために、ノード タイプごとにメトリック分散しきい値を定義できます。 分散しきい値は、特定のノード タイプにおける最大と最小の負荷値の比率のしきい値を表すので、浮動小数点型です。 分散しきい値は、ノード タイプごとに PlacementAndLoadBalancingOverrides セクションで定義されます。
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricBalancingThresholdsPerNodeType>
<BalancingThreshold Name="Metric1" Value="2.5">
<BalancingThreshold Name="Metric2" Value="4">
<BalancingThreshold Name="Metric3" Value="3.25">
</MetricBalancingThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
ノード タイプに対してメトリックの分散しきい値が定義されていない場合、PlacementAndLoadBalancing セクションでグローバルに定義されているメトリック分散しきい値の値が、しきい値として継承されます。 それ以外の場合で、PlacementAndLoadBalancing セクションでメトリックの分散しきい値がノード タイプに対してもグローバルにも定義されていない場合、しきい値の既定値は 1 になります。
ノード タイプごとのアクティビティしきい値
分散構成の粒度を高めるために、ノード タイプごとにメトリック アクティビティしきい値を定義できます。 アクティビティしきい値は、特定のノード タイプにおける最大負荷値のしきい値を表すので、整数型です。 アクティビティしきい値は、ノード タイプごとに PlacementAndLoadBalancingOverrides セクションで定義されます。
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricActivityThresholdsPerNodeType>
<ActivityThreshold Name="Metric1" Value="500">
<ActivityThreshold Name="Metric2" Value="40">
<ActivityThreshold Name="Metric3" Value="1000">
</MetricActivityThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
ノード タイプに対してメトリックのアクティビティしきい値が定義されていない場合、PlacementAndLoadBalancing セクションでグローバルに定義されているメトリック アクティビティしきい値の値が、しきい値として継承されます。 それ以外の場合で、PlacementAndLoadBalancing セクションでメトリックのアクティビティしきい値がノード タイプに対してもグローバルにも定義されていない場合、しきい値の既定値は 0 になります。
ノード タイプごとの最小分散間隔
分散構成の粒度を高めるために、ノード タイプごとに最小分散間隔を定義できます。 最小分散間隔は、同じノード タイプで分散ラウンドが 2 回連続する前に経過する必要がある最小時間を表すので、整数型です。 最小分散間隔は、ノード タイプごとに PlacementAndLoadBalancingOverrides セクションで定義されます。
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MinLoadBalancingIntervalPerNodeType>100</MinLoadBalancingIntervalPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
ノード タイプに対して最小分散間隔が定義されていない場合、この間隔として、PlacementAndLoadBalancing セクションでグローバルに定義されている最小分散間隔から値が継承されます。 それ以外の場合で、PlacementAndLoadBalancing セクションで最小間隔がノード タイプに対してもグローバルにも定義されていない場合、最小間隔の既定値は 0 になります。これは、連続する分散ラウンド間の一時停止が必要ないことを示します。
例
例 1
クラスターにノード タイプ A とノード タイプ B という 2 つのノード タイプが含まれている場合を考えてみましょう。すべてのサービスで同じメトリックが報告され、これらのノード タイプ間で分割されるため、負荷の統計は異なります。 この例では、ノード タイプ A は最大負荷が 300 で最小負荷が 100、ノード タイプ B は最大負荷が 700 で最小負荷が 500 です。
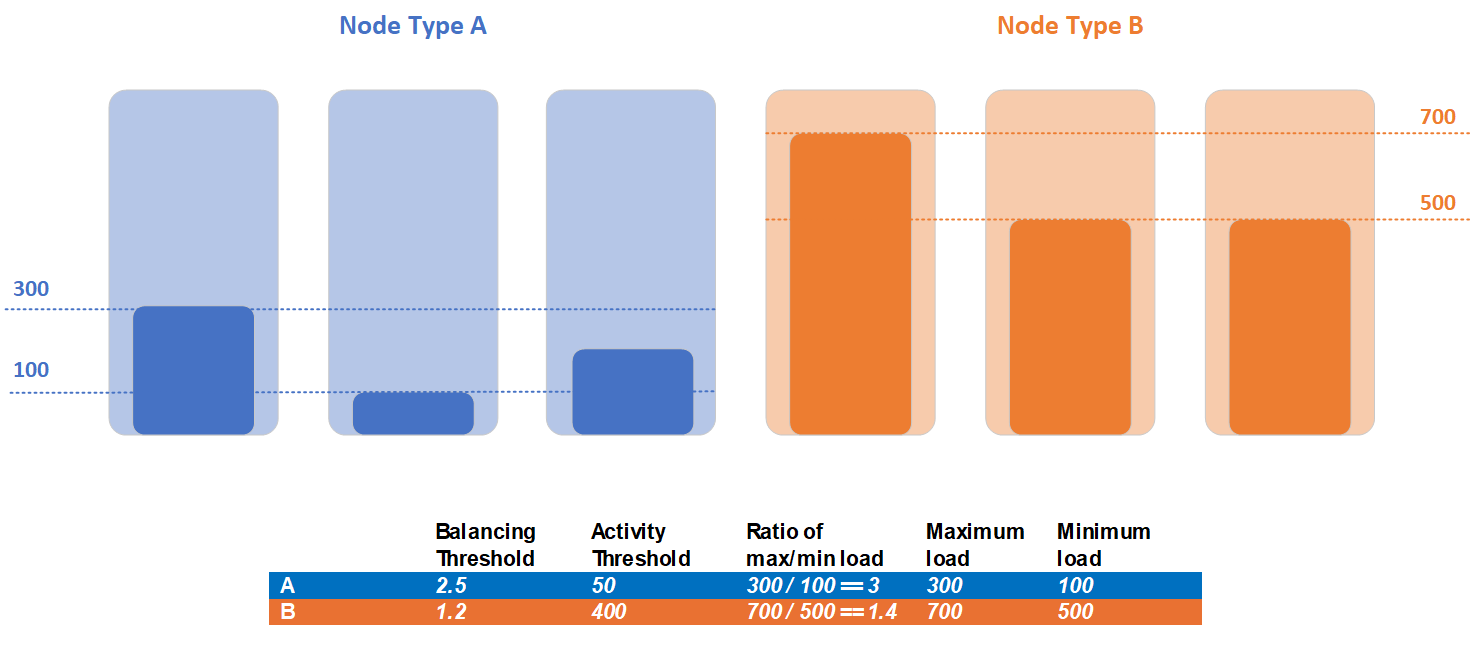
お客様は、2 つのノード タイプのワークロードに異なる分散ニーズがあることを特定し、ノード タイプごとに異なる分散とアクティビティのしきい値を設定することにしました。 ノード タイプ A は分散しきい値が 2.5 で、アクティビティしきい値が 50 です。 ノード タイプ B について、お客様は分散しきい値を 1.2 に、アクティビティしきい値を 400 に設定しました。
この例のクラスターの不均衡の検出で、両方のノード タイプにアクティビティしきい値の違反がありました。 ノード タイプ A の最大負荷 300 は、定義されたアクティビティしきい値である 50 を超えています。 ノード タイプ B の最大負荷 700 は、定義されたアクティビティしきい値である 400 を超えています。 ノード タイプ A は、最大負荷と最小負荷の現在の比率が 3 で、分散しきい値が 2.5 であるため、分散しきい値の条件に違反しています。 反対に、ノード タイプ B は、分散しきい値の条件に違反していません。このノード タイプの最大負荷と最小負荷の現在の比率は 1.2 ですが、分散しきい値は 1.4 であるためです。 分散は、ノード タイプ A のレプリカに対してのみ必要であり、分散フェーズ中に移動の対象となるレプリカのセットは、ノード タイプ A に配置されたレプリカのみです。
例 2
クラスターにノード タイプ A、B、C という 3 つのノード タイプが含まれている場合を考えてみましょう。すべてのサービスで同じメトリックが報告され、これらのノード タイプ間で分割されるため、負荷の統計は異なります。 この例では、ノード タイプ A の最大負荷は 600 で最小負荷は 100、ノード タイプ B の最大負荷は 900 で最小負荷は 100、ノード タイプ C の最大負荷は 600 で最小負荷は 300 です。

お客様は、これらのノード タイプのワークロードに異なる分散ニーズがあることを特定し、ノード タイプごとに異なる分散とアクティビティのしきい値を設定することにしました。 ノード タイプ A は分散しきい値が 5 で、アクティビティしきい値が 700 です。 ノード タイプ B について、お客様は分散しきい値を 10 に、アクティビティしきい値を 200 に設定しました。 ノード タイプ C について、お客様は分散しきい値を 2 に、アクティビティしきい値を 300 に設定しました。
ノード タイプ A の最大負荷 600 は、定義されたアクティビティしきい値である 700 よりも小さいため、ノード タイプ A はバランス調整されません。 ノード タイプ B の最大負荷 900 は、定義されたアクティビティしきい値である 200 を超えています。 ノード タイプ B はアクティビティしきい値の条件に違反しています。 ノード タイプ C の最大負荷 600 は、定義されたアクティビティしきい値である 300 を超えています。 ノード タイプ C はアクティビティしきい値の条件に違反しています。 ノード タイプ B は、分散しきい値の条件に違反していません。このノード タイプの最大負荷と最小負荷の現在の比率は 9 ですが、分散しきい値は 10 であるためです。 ノード タイプ C は、最大負荷と最小負荷の現在の比率が 2 で、分散しきい値が 2 であるため、分散しきい値の条件に違反しています。 分散は、ノード タイプ C のレプリカに対してのみ必要であり、分散フェーズ中に移動の対象となるレプリカのセットは、ノード タイプ C に配置されたレプリカのみです。
次のステップ
- メトリックは、Service Fabric クラスター リソース マネージャーが管理するクラスターの利用量と容量を表します。 メトリックの詳細とその構成方法については、メトリックに関する記事を参照してください
- 移動コストは、特定のサービスが他のサービスよりも高額になっていることをクラスター リソース マネージャーに警告する信号の 1 つです。 移動コストについて詳しくは、移動コストに関する記事を参照してください
- クラスター リソース マネージャーにはスロットルがいくつかあります。クラスターのチャーン (激しい動き) を落ち着かせるようにスロットルを構成できます。 通常は必要ありませんが、必要であれば、高度なスロットリングに関する記事で詳細を確認できます
- Cluster Resource Manager でサブクラスター化を認識して処理できます。 サブクラスター化は、配置の制約と分散を使用するときに発生する可能性があります。 サブクラスター化が負荷分散とその処理方法に与える影響については、サブクラスター化に関する記事を参照してください