Service Fabric のメトリックと負荷の最適化
Service Fabric クラスター リソース マネージャーで、クラスターの負荷メトリックを管理する既定の戦略は、負荷を分散することです。 ノードが均等に利用されるようにすることで、リソースの競合や無駄につながるホット スポットとコールド スポットを回避します。 また、クラスター内のワークロードの分散化も、障害対応の観点から見て最も安全です。障害が発生しても、ワークロードの大部分が消費される事態を回避できるからです。
Service Fabric クラスター リソース マネージャーは、最適化と呼ばれる別の負荷管理戦略をサポートしています。 最適化は、メトリックの使用量をクラスター全体に分散させる処理ではなく、統合する処理を意味します。 統合は、既定の分散戦略とは逆の処理です。クラスター リソース マネージャーでは、メトリック負荷の平均標準偏差の最小化ではなく、増大が試行されます。
最適化を使用する場合
クラスターの負荷を分散すると、各ノードのリソースの一部が消費されます。 ワークロードによっては、非常に大きなサービスが作成され、ノードの大部分が消費される可能性があります。 このような場合、実行できるだけの領域がどのノードにもない、大きなワークロードが作成される可能性があります。 大きなワークロードは、Service Fabric では問題ではありません。このような場合、クラスター リソース マネージャーは、クラスターを再編成してこの大きなワークロード用の領域を作成する必要があると判断します。 しかしその間、そのワークロードはクラスター内でスケジュールされるのを待機しなければなりません。
移動するサービスや状態の数が多い場合には、大きなワークロードがクラスター内に配置されるまでに、長い時間がかかる可能性があります。 他にも大きいワークロードがクラスター内に存在する場合は、特にこの問題が起こりやすく、再編成にかかる時間が長くなります。 Service Fabric チームでは、このシナリオをシミュレートして作成時間を測定しました。 クラスターの使用率が 30% から 50% を超えるとすぐに、大きなサービスの作成にはるかに長い時間がかかるようになることがわかりました。 そしてこのシナリオに対応するために、均衡化戦略としての最適化が導入されました。 ワークロードが大きい場合 (特に作成時間が重要である場合) には、最適化を使用することで、それらの新しいワークロードをクラスター内で効果的にスケジュールできます。
最適化メトリックを構成すると、クラスター リソース マネージャーはサービスの負荷をより少ないノードに集約しようとします。 そのため、クラスターを再編成しなくても、大きなサービスに対してもほぼ常に十分な領域を確保することができます。 クラスターを再編成する必要がないので、大きなワークロードをすばやく作成できます。
ほとんどの場合、最適化が必要になることはありません。 通常、サービスは小さいので、クラスター内で十分な領域を確保することは難しくありません。 繰り返しになりますが、ほとんどのサービスは小さく、同時にすばやく移動できるので、再編成が可能な場合は短時間で実行されます。 ただし、サービスの規模が大きく、すばやく作成する必要がある場合には、最適化が最適な戦略と言えます。 次に、最適化を使用する場合のトレードオフについて説明します。
最適化のトレードオフ
障害が発生したノードで実行されているサービスの数が多くなるため、最適化を行うと障害の影響範囲が広くなります。 大きなワークロードの作成を待機するために、クラスター内のリソースを予約する必要があるため、最適化によってコストが増大する可能性もあります。
次の図は、2 つのクラスターを視覚的に表現したものです。一方は最適化され、もう一方は最適化されていません。
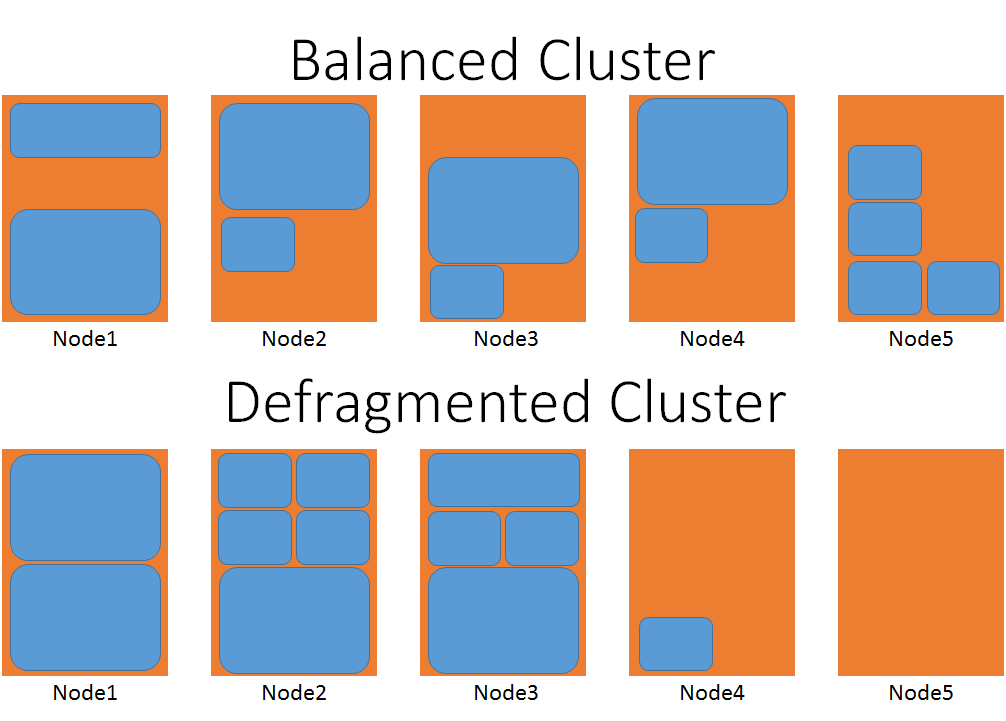
分散化されたほうのクラスターでは、大きなサービス オブジェクトを配置するために、多くの移動が必要になることがわかります。 最適化されたクラスターでは、他のサービスが移動されるまで待機することなく、大きなワークロードをノード 4 または 5 に配置できます。
最適化の長所と短所
他の概念的トレードオフとはどのようなものでしょうか。 次の表は考慮すべきことを簡単にまとめたものです。
| 最適化の長所 | 最適化の短所 |
|---|---|
| 大きいサービスを短時間で作成できる | 少数のノードに負荷をまとめるので、競合が増える |
| 作成の間のデータ移動が減る | 障害の影響を受けるサービスが増え、混乱が増す |
| 要件の記述を増やし領域を再利用できる | 全体的なリソース管理構成が複雑になる |
最適化と通常のメトリックを、同じクラスター内に混在させることもできます。 クラスター リソース マネージャーは、最適化メトリックを可能な限り統合しようとしながら、その他のメトリックを分散化します。 最適化戦略と分散戦略を混合すると、次のようないくつかの要因によって結果は変わります。
- 分散メトリック数と最適化メトリック数
- 両方の種類のメトリックを使用しているサービスがあるかどうか
- メトリックの重み
- 現在のメトリックの負荷
厳密な構成が必要かどうかを判断するには、実験を行う必要があります。 運用環境で最適化メトリックを有効にする前に、ワークロードを詳細に測定することをお勧めします。 同じサービス内で最適化メトリックと分散メトリックを混合する場合は特にお勧めです。
最適化メトリックを構成する
最適化メトリックの構成はクラスターでのグローバルな決定であり、最適化対象としてメトリックを個別に選択できます。 次の構成スニペットは、最適化に合わせてメトリックを構成する方法を示しています。 この例では、"Metric1" は最適化メトリックとして構成され、通常、"Metric2" は引き続き均衡をとるために使用されます。
ClusterManifest.xml:
<Section Name="DefragmentationMetrics">
<Parameter Name="Metric1" Value="true" />
<Parameter Name="Metric2" Value="false" />
</Section>
スタンドアロン デプロイの ClusterConfig.json 経由または Azure でホストされたクラスターの Template.json 経由:
"fabricSettings": [
{
"name": "DefragmentationMetrics",
"parameters": [
{
"name": "Metric1",
"value": "true"
},
{
"name": "Metric2",
"value": "false"
}
]
}
]
次のステップ
- Cluster Resource Manager には、クラスターを記述するためのさまざまなオプションがあります。 オプションの詳細については、Service Fabric クラスターの記述に関するこの記事を参照してください。
- メトリックは、Service Fabric クラスター リソース マネージャーが管理するクラスターの利用量と容量を表します。 メトリックの詳細とその構成方法については、この記事を参照してください。