Azure.Search.Documents クライアント ライブラリを使用してコンソール アプリケーションを構築し、検索インデックスの作成、読み込み、クエリの実行を行います。
代わりに、ソース コードをダウンロードして完成したプロジェクトから開始することも、次の手順に従って独自のアプリケーションを作成することもできます。
環境を設定する
Visual Studio を起動し、コンソール アプリ用の新しいプロジェクトを作成します。
[ツール]>[NuGet パッケージ マネージャー] で、 [ソリューションの NuGet パッケージの管理] を選択します。
[参照] を選択します。
Azure.Search.Documents パッケージを検索し、バージョン 11.0 以降を選択します。
[インストール] を選択して、プロジェクトとソリューションにアセンブリを追加します。
検索クライアントを作成する
Program.cs で名前空間を AzureSearch.SDK.Quickstart.v11 に変更し、次の using ディレクティブを追加します。
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Azure.Search.Documents.Models;
次のコードをコピーして、2 つのクライアントを作成します。 SearchIndexClient はインデックスを作成するクライアントで、SearchClient は既存のインデックスを読み込んで照会するクライアントです。 どちらも、作成と削除の権限に関する認証のためのサービス エンドポイントと管理 API キーが必要です。
コードによって URI が構築されるため、serviceName プロパティに検索サービス名のみを指定します。
static void Main(string[] args)
{
string serviceName = "<your-search-service-name>";
string apiKey = "<your-search-service-admin-api-key>";
string indexName = "hotels-quickstart";
// Create a SearchIndexClient to send create/delete index commands
Uri serviceEndpoint = new Uri($"https://{serviceName}.search.windows.net/");
AzureKeyCredential credential = new AzureKeyCredential(apiKey);
SearchIndexClient adminClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
SearchClient srchclient = new SearchClient(serviceEndpoint, indexName, credential);
. . .
}
インデックスを作成する
このクイックスタートでは、Hotels インデックスを作成します。そこにホテル データを読み込んでクエリを実行することになります。 この手順では、インデックス内のフィールドを定義します。 それぞれのフィールドの定義には、名前とデータ型、属性が存在し、それらによってフィールドの使い方が決まります。
簡潔で読みやすくするために、この例では、"Azure.Search.Documents" ライブラリの同期メソッドを使用しています。 ただし運用環境のシナリオでは、アプリのスケーラビリティと応答性を確保するために非同期メソッドを使用する必要があります。 たとえば、CreateIndex ではなく CreateIndexAsync を使用します。
空のクラス定義を Hotel.cs プロジェクトに追加します。
Hotel.cs に次のコードをコピーして、ホテル ドキュメントの構造を定義します。 フィールドは、その属性によって、アプリケーション内でどのように使用できるかが決まります。 たとえばフィルター式をサポートするフィールドには、それぞれ IsFilterable 属性が割り当てられている必要があります。
using System;
using System.Text.Json.Serialization;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
namespace AzureSearch.Quickstart
{
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.FrLucene)]
[JsonPropertyName("Description_fr")]
public string DescriptionFr { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[SearchableField(IsFilterable = true, IsFacetable = true)]
public string[] Tags { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public bool? ParkingIncluded { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public DateTimeOffset? LastRenovationDate { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public double? Rating { get; set; }
[SearchableField]
public Address Address { get; set; }
}
}
"Azure.Search.Documents" クライアント ライブラリでは、SearchableField と SimpleField を使用してフィールドの定義を効率化できます。 どちらも SearchField から派生したもので、コードの簡素化に役立つ可能性があります。
SimpleField は任意のデータ型にすることができます。また、常に検索不可能 (フルテキスト検索クエリでは無視される) で、取得可能 (非表示ではない) となります。 その他の属性は、既定ではオフですが、有効にすることができます。 SimpleField は、フィルター、ファセット、スコアリング プロファイルでのみ使用されるフィールドやドキュメント ID での使用が考えられます。 その場合は必ず、シナリオに必要な属性を適用してください (ドキュメント ID の IsKey = true など)。 詳細については、ソース コードの SimpleFieldAttribute.cs を参照してください。
SearchableField は文字列であることが必要です。常に検索可能で、取得可能となります。 その他の属性は、既定ではオフですが、有効にすることができます。 検索可能なタイプのフィールドであるため、同意語がサポートされるほか、アナライザーのプロパティがすべてサポートされます。 詳細については、ソース コードの SearchableFieldAttribute.cs を参照してください。
基本 SearchField API を使用する場合も、そのいずれかのヘルパー モデルを使用する場合も、フィルター、ファセット、並べ替えの属性は明示的に有効にする必要があります。 たとえば、IsFilterable、IsSortable、IsFacetable の各属性は、前のサンプルのように明示的に指定する必要があります。
2 つ目の空のクラス定義をプロジェクトに追加します (Address.cs)。 このクラスに次のコードをコピーします。
using Azure.Search.Documents.Indexes;
namespace AzureSearch.Quickstart
{
public partial class Address
{
[SearchableField(IsFilterable = true)]
public string StreetAddress { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string City { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string StateProvince { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string PostalCode { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Country { get; set; }
}
}
さらに次の 2 つのクラスを作成します。ToString() のオーバーライドの "Hotel.Methods.cs" と "Address.Methods.cs" です。 これらのクラスは、コンソール出力に検索結果をレンダリングするために使用されます。 これらのクラスの内容はこの記事では提供されていませんが、GitHub のファイルからコードをコピーできます。
Program.cs に SearchIndex オブジェクトを作成し、CreateIndex メソッドを呼び出して、検索サービスのインデックスを表現します。 インデックスには、指定されたフィールドでオートコンプリートを有効にするための SearchSuggester も含まれています。
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient adminClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
adminClient.CreateOrUpdateIndex(definition);
}
ドキュメントを読み込む
Azure AI Search は、サービスに保存されているコンテンツを検索します。 この手順では、先ほど作成したホテル インデックスに準拠した JSON ドキュメントを読み込みます。
Azure AI Search では、検索ドキュメントは、インデックス作成への入力とクエリからの出力の両方であるデータ構造です。 外部データ ソースから取得するドキュメント入力には、データベース内の行、Blob storage 内の BLOB、ディスク上の JSON ドキュメントがあります。 この例では、手短な方法として、4 つのホテルの JSON ドキュメントをコード自体に埋め込みます。
ドキュメントをアップロードするときは、IndexDocumentsBatch オブジェクトを使用する必要があります。 IndexDocumentsBatch オブジェクトには、 Actionsのコレクションが含まれています。各オブジェクトには、Azure AICognitive Searchに実行するアクション (アップロード、マージ、削除、および mergeOrUpload) を示すドキュメントとプロパティが含まれています。
Program.cs で、ドキュメントとインデックス アクションの配列を作成し、その配列を IndexDocumentsBatch に渡します。 以下のドキュメントは、Hotel クラスで定義されている hotels-quickstart インデックスに準拠しています。
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
Description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
DescriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
Category = "Boutique",
Tags = new[] { "pool", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1970, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Old Century Hotel",
Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Boutique",
Tags = new[] { "pool", "free wifi", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1979, 2, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.60,
Address = new Address()
{
StreetAddress = "140 University Town Center Dr",
City = "Sarasota",
StateProvince = "FL",
PostalCode = "34243",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Gastronomic Landscape Hotel",
Description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Resort and Spa",
Tags = new[] { "air conditioning", "bar", "continental breakfast" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero),
Rating = 4.80,
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
City = "Atlanta",
StateProvince = "GA",
PostalCode = "30326",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "4",
HotelName = "Sublime Palace Hotel",
Description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
DescriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
Category = "Boutique",
Tags = new[] { "concierge", "view", "24-hour front desk service" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(1960, 2, 06, 0, 0, 0, TimeSpan.Zero),
Rating = 4.60,
Address = new Address()
{
StreetAddress = "7400 San Pedro Ave",
City = "San Antonio",
StateProvince = "TX",
PostalCode = "78216",
Country = "USA"
}
})
);
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs the failed document keys and continues.
Console.WriteLine("Failed to index some of the documents: {0}");
}
}
IndexDocumentsBatch オブジェクトを初期化したら、SearchClient オブジェクトの IndexDocuments を呼び出すことによって、それをインデックスに送信することができます。
次の行を Main() に追加します。 ドキュメントの読み込みは SearchClient を使用して実行されますが、この操作にはサービスに対する管理者権限も必要であり、通常、SearchIndexClient に関連付けられています。 この操作を設定する 1 つの方法は、SearchIndexClient (この例ではadminClient) を使用して SearchClient を取得することです。
SearchClient ingesterClient = adminClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
これはすべてのコマンドを連続して実行するコンソール アプリであるため、インデックス作成とクエリの間に 2 秒の待ち時間を追加します。
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
2 秒の遅延により、非同期のインデックス作成を待ち、クエリの実行前にすべてのドキュメントのインデックスを作成できるようにしています。 通常、遅延のコーディングは、デモ、テスト、およびサンプル アプリケーションでのみ必要です。
インデックスを検索する
最初のドキュメントのインデックスが作成されるとすぐにクエリの結果を取得できますが、インデックスの実際のテストではすべてのドキュメントのインデックスが作成されるまで待つ必要があります。
このセクションでは、クエリ ロジックと結果の 2 つの機能を追加します。 クエリには、Search メソッドを使用します。 このメソッドは、検索テキスト (クエリ文字列) と他のオプションを受け取ります。
その結果は、SearchResults クラスによって表されます。
"Program.cs" で、検索結果をコンソールに出力する WriteDocuments メソッドを作成します。
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
クエリを実行し、結果を返す RunQueries メソッドを作成します。 結果は、Hotel オブジェクトです。 このサンプルは、メソッド シグネチャと最初のクエリを示しています。 このクエリは、ドキュメントから選択されたフィールドを使用して結果を作成できる Select パラメーターを示しています。
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient srchclient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
2 つ目のクエリでは、語句を検索し、Rating が 4 を超えるドキュメントを選択するフィルターを追加したうえで、Rating の降順で並べ替えます。 フィルターは、インデックス内の IsFilterable フィールドに対して評価されるブール式です。 フィルター クエリでは、値は包含されるか除外されるかのどちらかです。 そのため、フィルター クエリに関連付けられている関連性スコアはありません。
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = srchclient.Search<Hotel>("hotels", options);
WriteDocuments(response);
3 番目のクエリは、フルテキスト検索操作の範囲を特定のフィールドに設定するために使用する searchFields を示しています。
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = srchclient.Search<Hotel>("pool", options);
WriteDocuments(response);
4 番目のクエリは、ファセット ナビゲーション構造を構築するために使用できる facets を示しています。
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
5 番目のクエリでは、特定のドキュメントを返します。 ドキュメント検索は、結果セット内の OnClick イベントに対する一般的な応答です。
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = srchclient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
最後のクエリは、オートコンプリートの構文を示しています。これは、インデックスで定義した suggester に関連付けられている sourceFields の 2 つの一致候補に解決される、"sa" という部分的なユーザー入力をシミュレートしています。
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = srchclient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
RunQueries を Main() に追加します。
// Call the RunQueries method to invoke a series of queries
Console.WriteLine("Starting queries...\n");
RunQueries(srchclient);
// End the program
Console.WriteLine("{0}", "Complete. Press any key to end this program...\n");
Console.ReadKey();
上記のクエリは、クエリで語句を照合する複数の方法 (フルテキスト検索、フィルター、オートコンプリート) を示しています。
フルテキスト検索とフィルターは、SearchClient.Search メソッドを使用して実行されます。 検索クエリは searchText 文字列で渡すことができます。一方、フィルター式は SearchOptions クラスの Filter プロパティで渡すことができます。 検索せずにフィルター処理を実行するには、Search メソッドの searchText パラメーターに "*" を渡します。 フィルター処理を行わずに検索するには、Filter プロパティを未設定のままにするか、SearchOptions インスタンスを 1 つも渡さないようにします。
プログラムを実行する
F5 キーを押して、アプリをリビルドし、プログラム全体を実行します。
出力には、Console.WriteLine からのメッセージに加え、クエリの情報と結果が表示されます。
検索インデックスを作成し、読み込み、クエリを実行するには、Azure SDK for Python の azure-search-documents ライブラリと Jupyter ノートブックを使用してください。
あるいは、完成したノートブックをダウンロードして実行することもできます。
環境を設定する
Visual Studio Code と Python 拡張機能、または Python 3.10 以降と同等の IDE を使用してください。
このクイックスタートでは仮想環境をお勧めします。
Visual Studio Code を起動します。
コマンド パレットを開きます (Ctrl + Shift + P キー)。
"Python: 環境の作成" を検索します。
Venv. を選択
Python インタープリターを選択します。 バージョン 3.10 以降を選択してください。
短時間で設定されます。 問題が発生した場合は、「VS Code での Python 環境」を参照してください。
パッケージをインストールし、変数を設定する
azure-search-documents などのパッケージをインストールします。
! pip install azure-search-documents==11.6.0b1 --quiet
! pip install azure-identity --quiet
! pip install python-dotenv --quiet
サービスのエンドポイントと API キーを指定します。
search_endpoint: str = "PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE"
search_api_key: str = "PUT-YOUR-SEARCH-SERVICE-ADMIN-API-KEY-HERE"
index_name: str = "hotels-quickstart"
インデックスを作成する
from azure.core.credentials import AzureKeyCredential
credential = AzureKeyCredential(search_api_key)
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
# Create a search schema
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),
SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),
SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),
SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),
SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),
SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),
SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),
SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),
ComplexField(name="Address", fields=[
SearchableField(name="StreetAddress", type=SearchFieldDataType.String),
SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
])
]
scoring_profiles = []
suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}]
# Create the search index
index = SearchIndex(name=index_name, fields=fields, suggesters=suggester, scoring_profiles=scoring_profiles)
result = index_client.create_or_update_index(index)
print(f' {result.name} created')
ドキュメント ペイロードを作成する
インデックス アクションで、upload や merge-and-upload などの操作の種類を指定します。 ドキュメントは、GitHub の HotelsData サンプルに由来します。
# Create a documents payload
documents = [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": [ "pool", "air conditioning", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": [ "air conditioning", "bar", "continental breakfast" ],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": [ "concierge", "view", "24-hour front desk service" ],
"ParkingIncluded": "true",
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.60,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216",
"Country": "USA"
}
}
]
ドキュメントのアップロード
# Upload documents to the index
search_client = SearchClient(endpoint=search_endpoint,
index_name=index_name,
credential=credential)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print (ex.message)
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
最初のクエリを実行する
search.client クラスの search メソッドを使用します。
この例では、空の検索 (search=*) が実行され、任意のドキュメントのランクなしの一覧 (search score = 1.0) が返されます。 条件がないため、すべてのドキュメントが結果に含まれます。
# Run an empty query (returns selected fields, all documents)
results = search_client.search(query_type='simple',
search_text="*" ,
select='HotelName,Description',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
用語クエリを実行する
次のクエリでは、検索式に完全な用語を追加しています ("wifi")。 このクエリでは、select ステートメント内のフィールドのみが結果に含まれることを指定しています。 返されるフィールドを制限すると、ネットワーク経由で返されるデータの量が最小限に抑えられ、検索の待ち時間が短縮されます。
results = search_client.search(query_type='simple',
search_text="wifi" ,
select='HotelName,Description,Tags',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
フィルターを追加する
評価が 4 を超えるホテルのみを降順に並べ替えて返すフィルター式を追加します。
# Add a filter
results = search_client.search(
search_text="hotels",
select='HotelId,HotelName,Rating',
filter='Rating gt 4',
order_by='Rating desc')
for result in results:
print("{}: {} - {} rating".format(result["HotelId"], result["HotelName"], result["Rating"]))
フィールドのスコープを追加する
search_fields を追加し、特定のフィールドにクエリ実行の範囲を制限します。
# Add search_fields to scope query matching to the HotelName field
results = search_client.search(
search_text="sublime",
search_fields=['HotelName'],
select='HotelId,HotelName')
for result in results:
print("{}: {}".format(result["HotelId"], result["HotelName"]))
ファセットを追加する
ファセットは、検索結果で見つかった正の一致に対して生成されます。 0 件の一致はありません。 検索結果に "wifi" という用語が含まれていない場合、"wifi" はファセット ナビゲーション構造に表示されません。
# Return facets
results = search_client.search(search_text="*", facets=["Category"])
facets = results.get_facets()
for facet in facets["Category"]:
print(" {}".format(facet))
ドキュメントを検索する
キーに基づいてドキュメントを返します。 この操作は、ユーザーが検索結果の項目を選択したときにドリルスルーを提供したい場合に便利です。
# Look up a specific document by ID
result = search_client.get_document(key="3")
print("Details for hotel '3' are:")
print("Name: {}".format(result["HotelName"]))
print("Rating: {}".format(result["Rating"]))
print("Category: {}".format(result["Category"]))
オートコンプリートを追加する
オートコンプリートでは、ユーザーが検索ボックスに入力したときに一致する可能性のあるものを提供することができます。
オートコンプリートでは、suggester (sg) を使用して、suggester 要求に一致する可能性があるものを含むフィールドを把握します。 このクイックスタートでは、これらのフィールドは Tags、Address/City、Address/Country です。
オートコンプリートをシミュレートするには、文字 "sa" を部分文字列として渡します。 SearchClient の autocomplete メソッドにより、一致する可能性のある用語が返されます。
# Autocomplete a query
search_suggestion = 'sa'
results = search_client.autocomplete(
search_text=search_suggestion,
suggester_name="sg",
mode='twoTerms')
print("Autocomplete for:", search_suggestion)
for result in results:
print (result['text'])
Azure.Search.Documents ライブラリを使用して Java コンソール アプリケーションを構築し、検索インデックスの作成、読み込み、クエリの実行を行います。
代わりに、ソース コードをダウンロードして完成したプロジェクトから開始することも、次の手順に従って独自のアプリケーションを作成することもできます。
環境を設定する
このクイックスタートを作成するために、次のツールを使用しました。
プロジェクトを作成する
Visual Studio Code を起動します。
Ctrl + Shift + P キーを使用してコマンド パレットを開きます。 「Create Java Project」を検索します。

[Maven] を選択します。
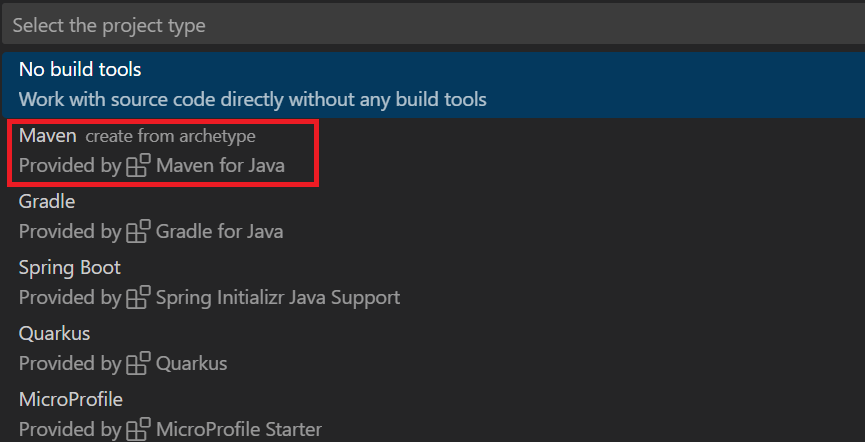
maven-archetype-quickstart を選択します。
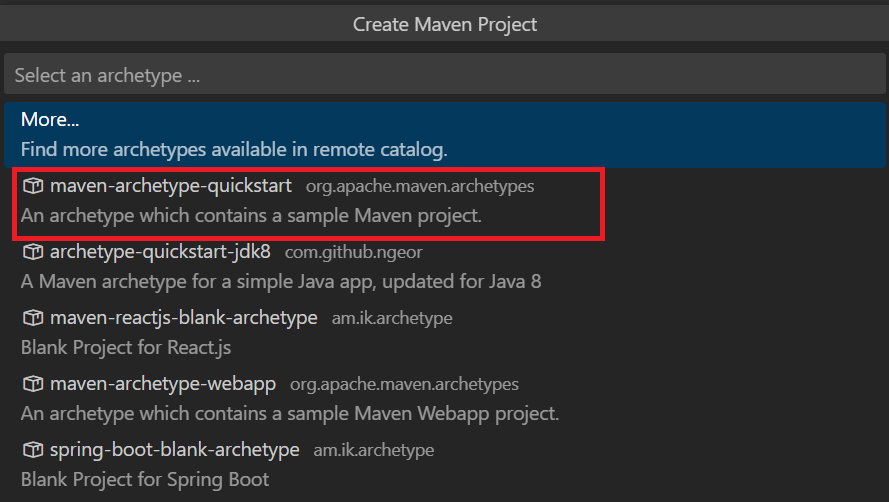
最新のバージョン番号 (現在、1.4) を選択します。

グループ ID として「azure.search.sample」と入力します。
成果物 ID として「azuresearchquickstart」と入力します。

プロジェクトを作成するフォルダーを選択します。
統合ターミナルでプロジェクトの作成を完了します。 Enter キーを押して "1.0-SNAPSHOT" の既定値をそのまま使用し、「y」と入力してプロジェクトのプロパティを確認します。
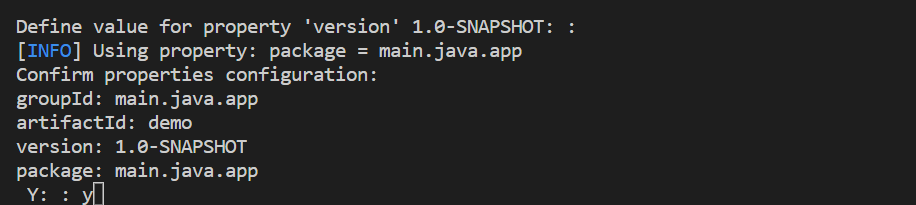
プロジェクトを作成したフォルダーを開きます。
Maven の依存関係を指定する
"pom.xml" ファイルを開き、次の依存関係を追加します。
<dependencies>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-search-documents</artifactId>
<version>11.7.3</version>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-core</artifactId>
<version>1.53.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
コンパイラの Java バージョンを 11 に変更します。
<maven.compiler.source>1.11</maven.compiler.source>
<maven.compiler.target>1.11</maven.compiler.target>
検索クライアントを作成する
src、main、java、azure、search、sample の下で App クラスを開きます。 次のインポート ディレクティブを追加します。
import java.util.Arrays;
import java.util.ArrayList;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.LocalDateTime;
import java.time.LocalDate;
import java.time.LocalTime;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.Context;
import com.azure.search.documents.SearchClient;
import com.azure.search.documents.SearchClientBuilder;
import com.azure.search.documents.models.SearchOptions;
import com.azure.search.documents.indexes.SearchIndexClient;
import com.azure.search.documents.indexes.SearchIndexClientBuilder;
import com.azure.search.documents.indexes.models.IndexDocumentsBatch;
import com.azure.search.documents.indexes.models.SearchIndex;
import com.azure.search.documents.indexes.models.SearchSuggester;
import com.azure.search.documents.util.AutocompletePagedIterable;
import com.azure.search.documents.util.SearchPagedIterable;
次の例には、検索サービス名、作成と削除のアクセス許可を付与する管理 API キー、インデックス名のプレースホルダーが含まれています。 3 つのプレースホルダーすべてで有効な値に置き換えます。 2 つのクライアントを作成します。SearchIndexClient はインデックスを作成するクライアントで、SearchClient は既存のインデックスを読み込んで照会するクライアントです。 どちらにも、作成と削除の権限に関する認証のためにサービス エンドポイントと管理 API キーが必要です。
public static void main(String[] args) {
var searchServiceEndpoint = "<YOUR-SEARCH-SERVICE-URL>";
var adminKey = new AzureKeyCredential("<YOUR-SEARCH-SERVICE-ADMIN-KEY>");
String indexName = "<YOUR-SEARCH-INDEX-NAME>";
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.buildClient();
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.indexName(indexName)
.buildClient();
}
インデックスを作成する
このクイックスタートでは、Hotels インデックスを作成します。そこにホテル データを読み込んでクエリを実行することになります。 この手順では、インデックス内のフィールドを定義します。 それぞれのフィールドの定義には、名前とデータ型、属性が存在し、それらによってフィールドの使い方が決まります。
簡潔で読みやすくするために、この例では、azure-search-documents ライブラリの同期メソッドを使用しています。 ただし運用環境のシナリオでは、アプリのスケーラビリティと応答性を確保するために非同期メソッドを使用する必要があります。 たとえば、SearchClient の代わりに SearchAsyncClient を使用します。
空のクラス定義を Hotel.java プロジェクトに追加します。
Hotel.java に次のコードをコピーして、ホテル ドキュメントの構造を定義します。 フィールドは、その属性によって、アプリケーション内でどのように使用できるかが決まります。 たとえばフィルター式をサポートするすべてのフィールドには、IsFilterable 注釈が割り当てられている必要があります。
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.azure.search.documents.indexes.SimpleField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import java.time.OffsetDateTime;
/**
* Model class representing a hotel.
*/
@JsonInclude(Include.NON_NULL)
public class Hotel {
/**
* Hotel ID
*/
@JsonProperty("HotelId")
@SimpleField(isKey = true)
public String hotelId;
/**
* Hotel name
*/
@JsonProperty("HotelName")
@SearchableField(isSortable = true)
public String hotelName;
/**
* Description
*/
@JsonProperty("Description")
@SearchableField(analyzerName = "en.microsoft")
public String description;
/**
* French description
*/
@JsonProperty("DescriptionFr")
@SearchableField(analyzerName = "fr.lucene")
public String descriptionFr;
/**
* Category
*/
@JsonProperty("Category")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String category;
/**
* Tags
*/
@JsonProperty("Tags")
@SearchableField(isFilterable = true, isFacetable = true)
public String[] tags;
/**
* Whether parking is included
*/
@JsonProperty("ParkingIncluded")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Boolean parkingIncluded;
/**
* Last renovation time
*/
@JsonProperty("LastRenovationDate")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public OffsetDateTime lastRenovationDate;
/**
* Rating
*/
@JsonProperty("Rating")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Double rating;
/**
* Address
*/
@JsonProperty("Address")
public Address address;
@Override
public String toString()
{
try
{
return new ObjectMapper().writeValueAsString(this);
}
catch (JsonProcessingException e)
{
e.printStackTrace();
return "";
}
}
}
Azure.Search.Documents クライアント ライブラリでは、SearchableField と SimpleField を使用してフィールドの定義を効率化できます。
SimpleField は任意のデータ型にすることができます。また、常に検索不可能 (フルテキスト検索クエリでは無視される) で、取得可能 (非表示ではない) となります。 その他の属性は、既定ではオフですが、有効にすることができます。 SimpleField は、フィルター、ファセット、スコアリング プロファイルでのみ使用されるフィールドやドキュメント ID での使用が考えられます。 その場合は必ず、シナリオに必要な属性を適用してください (ドキュメント ID の IsKey = true など)。SearchableField は文字列であることが必要です。常に検索可能で、取得可能となります。 その他の属性は、既定ではオフですが、有効にすることができます。 検索可能なタイプのフィールドであるため、同意語がサポートされるほか、アナライザーのプロパティがすべてサポートされます。
基本 SearchField API を使用する場合も、そのいずれかのヘルパー モデルを使用する場合も、フィルター、ファセット、並べ替えの属性は明示的に有効にする必要があります。 たとえば、isFilterable、isSortable、isFacetable の各属性は、上のサンプルのように明示的に指定する必要があります。
2 つ目の空のクラス定義を Address.java プロジェクトに追加します。 このクラスに次のコードをコピーします。
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
/**
* Model class representing an address.
*/
@JsonInclude(Include.NON_NULL)
public class Address {
/**
* Street address
*/
@JsonProperty("StreetAddress")
@SearchableField
public String streetAddress;
/**
* City
*/
@JsonProperty("City")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String city;
/**
* State or province
*/
@JsonProperty("StateProvince")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String stateProvince;
/**
* Postal code
*/
@JsonProperty("PostalCode")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String postalCode;
/**
* Country
*/
@JsonProperty("Country")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String country;
}
App.java で、main メソッドに SearchIndex オブジェクトを作成し、createOrUpdateIndex メソッドを呼び出して検索サービスにインデックスを作成します。 インデックスには、指定されたフィールドでオートコンプリートを有効にするための SearchSuggester も含まれています。
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
ドキュメントを読み込む
Azure AI Search は、サービスに保存されているコンテンツを検索します。 この手順では、先ほど作成したホテル インデックスに準拠した JSON ドキュメントを読み込みます。
Azure AI Search では、検索ドキュメントは、インデックス作成への入力とクエリからの出力の両方であるデータ構造です。 外部データ ソースから取得するドキュメント入力には、データベース内の行、Blob storage 内の BLOB、ディスク上の JSON ドキュメントがあります。 この例では、手短な方法として、4 つのホテルの JSON ドキュメントをコード自体に埋め込みます。
ドキュメントをアップロードするときは、IndexDocumentsBatch オブジェクトを使用する必要があります。 IndexDocumentsBatch オブジェクトには、 IndexActionsのコレクションが含まれており、それぞれにドキュメントと、実行するアクション (アップロード、マージ、削除、および mergeOrUpload) を Azure AI Search に伝えるプロパティが含まれています。
App.java で、ドキュメントとインデックス アクションを作成し、それらを IndexDocumentsBatch に渡します。 以下のドキュメントは、Hotel クラスで定義されている hotels-quickstart インデックスに準拠しています。
// Upload documents in a single Upload request.
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Stay-Kay City Hotel";
hotel.description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.";
hotel.descriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1970, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "2";
hotel.hotelName = "Old Century Hotel";
hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "free wifi", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1979, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.60;
hotel.address = new Address();
hotel.address.streetAddress = "140 University Town Center Dr";
hotel.address.city = "Sarasota";
hotel.address.stateProvince = "FL";
hotel.address.postalCode = "34243";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "3";
hotel.hotelName = "Gastronomic Landscape Hotel";
hotel.description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Resort and Spa";
hotel.tags = new String[] { "air conditioning", "bar", "continental breakfast" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.80;
hotel.address = new Address();
hotel.address.streetAddress = "3393 Peachtree Rd";
hotel.address.city = "Atlanta";
hotel.address.stateProvince = "GA";
hotel.address.postalCode = "30326";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "4";
hotel.hotelName = "Sublime Palace Hotel";
hotel.description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.";
hotel.descriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.";
hotel.category = "Boutique";
hotel.tags = new String[] { "concierge", "view", "24-hour front desk service" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1960, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.60;
hotel.address = new Address();
hotel.address.streetAddress = "7400 San Pedro Ave";
hotel.address.city = "San Antonio";
hotel.address.stateProvince = "TX";
hotel.address.postalCode = "78216";
hotel.address.country = "USA";
hotelList.add(hotel);
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
IndexDocumentsBatch オブジェクトは、初期化した後、SearchClient オブジェクトに対して indexDocuments を呼び出すことでインデックスに送信できます。
次の行を Main() に追加します。 ドキュメントの読み込みは SearchClient を使用して行われます。
// Upload sample hotel documents to the Search Index
uploadDocuments(searchClient);
これはすべてのコマンドを連続して実行するコンソール アプリであるため、インデックス作成とクエリの間に 2 秒の待ち時間を追加します。
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
2 秒の遅延により、非同期のインデックス作成を待ち、クエリの実行前にすべてのドキュメントのインデックスを作成できるようにしています。 通常、遅延のコーディングは、デモ、テスト、およびサンプル アプリケーションでのみ必要です。
インデックスを検索する
最初のドキュメントのインデックスが作成されるとすぐにクエリの結果を取得できますが、インデックスの実際のテストではすべてのドキュメントのインデックスが作成されるまで待つ必要があります。
このセクションでは、クエリ ロジックと結果の 2 つの機能を追加します。 クエリには、Search メソッドを使用します。 このメソッドは、検索テキスト (クエリ文字列) と他のオプションを受け取ります。
App.java で、検索結果をコンソールに出力する WriteDocuments メソッドを作成します。
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
クエリを実行し、結果を返す RunQueries メソッドを作成します。 結果は Hotel オブジェクトです。 このサンプルは、メソッド シグネチャと最初のクエリを示しています。 このクエリは、ドキュメントから選択されたフィールドを使用して結果を作成できる Select パラメーターを示しています。
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
2 つ目のクエリでは、語句を検索し、Rating が 4 を超えるドキュメントを選択するフィルターを追加したうえで、"Rating" の降順で並べ替えます。 フィルターは、インデックス内の isFilterable フィールドに対して評価されるブール式です。 フィルター クエリでは、値は包含されるか除外されるかのどちらかです。 そのため、フィルター クエリに関連付けられている関連性スコアはありません。
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
3 番目のクエリは、フルテキスト検索操作の範囲を特定のフィールドに設定するために使用する searchFields を示しています。
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
4 番目のクエリは、ファセット ナビゲーション構造を構築するために使用できる facets を示しています。
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
5 番目のクエリでは、特定のドキュメントを返します。
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
最後のクエリは、オートコンプリートの構文を示しています。これは、インデックスで定義した suggester に関連付けられている sourceFields の 2 つの一致候補に解決される、"s" という部分的なユーザー入力をシミュレートしています。
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
RunQueries を Main() に追加します。
// Call the RunQueries method to invoke a series of queries
System.out.println("Starting queries...\n");
RunQueries(searchClient);
// End the program
System.out.println("Complete.\n");
上記のクエリは、クエリで語句を照合する複数の方法 (フルテキスト検索、フィルター、オートコンプリート) を示しています。
フルテキスト検索とフィルターは、SearchClient.search メソッドを使用して実行されます。 検索クエリは searchText 文字列で渡すことができます。一方、フィルター式は SearchOptions クラスの filter プロパティで渡すことができます。 検索せずにフィルター処理を実行するには、search メソッドの searchText パラメーターに "*" を渡します。 フィルター処理を行わずに検索するには、filter プロパティを未設定のままにするか、SearchOptions インスタンスを 1 つも渡さないようにします。
プログラムを実行する
F5 キーを押して、アプリをリビルドし、プログラム全体を実行します。
出力には、System.out.println からのメッセージに加え、クエリの情報と結果が表示されます。
@azure/search-documents ライブラリを使用して Node.js アプリケーションを構築し、検索インデックスの作成、読み込み、クエリの実行を行います。
代わりに、ソース コードをダウンロードして完成したプロジェクトから開始することも、次の手順に従って独自のアプリケーションを作成することもできます。
環境を設定する
このクイックスタートを作成するために、次のツールを使用しました。
プロジェクトを作成する
Visual Studio Code を起動します。
Ctrl + Shift + P キーで コマンド パレット を開き、統合ターミナルを開きます。
開発用ディレクトリを作成して "quickstart" という名前を付けます。
mkdir quickstart
cd quickstart
次のコマンドを実行して、npm によって空のプロジェクトを初期化します。 プロジェクトを完全に初期化するには、Enter キーを複数回押して既定値をそのまま使用します。ただし、ライセンスは "MIT" に設定する必要があります。
npm init
@azure/search-documentsAzure AI Search 用の JavaScript/TypeScript SDKをインストールします。
npm install @azure/search-documents
dotenv をインストールします。これは、検索サービス名や API キーなど、環境変数をインポートするために使用されます。
npm install dotenv
"quickstart" ディレクトリに移動して、自分の package.json ファイルが次の json ファイルのようになっていることをチェックし、プロジェクトとその依存関係を構成できたことを確認します。
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^11.3.0",
"dotenv": "^16.0.2"
}
}
自分の検索サービスのパラメーターを保持するファイル .env を作成します。
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
YOUR-SEARCH-SERVICE-URL の値は、自分の検索サービス エンドポイント URL の名前に置き換えます。 <YOUR-SEARCH-ADMIN-API-KEY> は、前に記録した管理者キーに置き換えます。
index.js ファイルを作成する
次は "index.js" ファイルを作成します。これはコードをホストするメイン ファイルです。
このファイルの冒頭で、@azure/search-documents ライブラリをインポートします。
const { SearchIndexClient, SearchClient, AzureKeyCredential, odata } = require("@azure/search-documents");
その後、次のように dotenv パッケージに対して require を実行し、 .env ファイルからパラメーターを読み取る必要があります。
// Load the .env file if it exists
require("dotenv").config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
インポートと環境変数を用意できたところで、main 関数を定義する準備が整いました。
SDK 内の機能のほとんどは非同期のため、ここでは main 関数を async にします。 また、main 関数の下に main().catch() も追加します。エラーが発生した場合にキャッチしてログに記録するためです。
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
それが済んだら、インデックスを作成する準備は完了です。
インデックスの作成
hotels_quickstart_index.json というファイルを作成します。 このファイルは、次のステップで読み込むドキュメントで Azure AI Search がどのように機能するかを定義します。 各フィールドは name によって識別されます。それぞれ、指定された type を備えています。 各フィールドには、Azure AI Search がフィールドで検索、フィルター処理、並べ替え、ファセットを実行できるかどうかを指定する一連のインデックス属性もあります。 ほとんどのフィールドは単純なデータ型ですが、AddressType のように、自分のインデックスでリッチなデータ構造を作成できる複合型もあります。 サポートされているデータ型とインデックスの属性について詳しくは、インデックスの作成 (REST) に関するページを参照してください。
次の内容を hotels_quickstart_index.json に追加するか、ファイルをダウンロードします。
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
インデックスの定義が完了したら、main 関数でインデックスの定義にアクセスできるように、index.js の冒頭で hotels_quickstart_index.json をインポートする必要があります。
const indexDefinition = require('./hotels_quickstart_index.json');
main 関数内で、 SearchIndexClientを作成します。これは、Azure AI Search のインデックスの作成と管理に使用されます。
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
次に、インデックスが既に存在する場合はそれを削除します。 この操作は、テストやデモのコードでは一般的な手法です。
これを行うには、インデックスの削除を試行する単純な関数を定義します。
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
関数を実行するには、インデックス定義からインデックス名を抽出し、indexClient と共に indexName を deleteIndexIfExists() 関数に渡します。
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
その後、createIndex() メソッドを使用してインデックスを作成する準備が整います。
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
サンプルを実行する
これで、サンプルを実行する準備が整いました。 ターミナル ウィンドウを使用して次のコマンドを実行します。
node index.js
ソース コードをダウンロードしていても、必須のパッケージをまだインストールしていない場合は、最初に npm install を実行します。
プログラムにより実行されているアクションを示す一連のメッセージが表示されます。
Azure portal で、自分の検索サービスの [概要] を開きます。 [インデックス] タブを選択します。次の例のように表示されます。
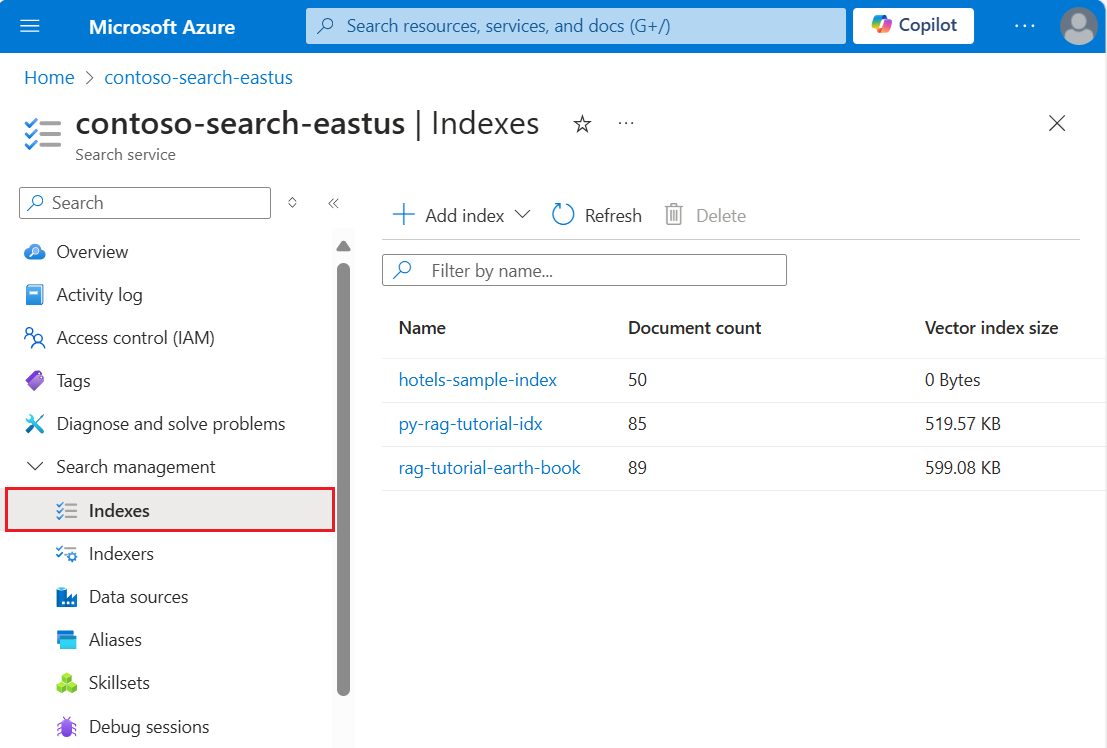
次の手順では、インデックスにデータを追加します。
ドキュメントを読み込む
Azure AI Search では、ドキュメントはインデックス作成への入力とクエリからの出力の両方であるデータ構造です。 このようなデータをインデックスにプッシュするか、インデクサーを使用することができます。 ここでは、プログラムでドキュメントをインデックスにプッシュします。
ドキュメント入力には、データベース内の行、Blob Storage 内の BLOB、またはこの例のようなディスク上の JSON ドキュメントがあります。 hotels.json をダウンロードするか、次の内容を使って独自の hotels.json ファイルを作成できます。
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
indexDefinition で行ったのと同様に、main 関数でデータにアクセスできるように、"index.js" の冒頭で hotels.json をインポートする必要もあります。
const hotelData = require('./hotels.json');
データに検索インデックスを付けるために、次は SearchClient を作成する必要があります。 SearchIndexClient はインデックスの作成と管理に使用され、SearchClient はドキュメントのアップロードとインデックスのクエリに使用されます。
SearchClient は 2 とおりの方法で作成できます。 1 つには、ゼロから SearchClient を作成する方法があります。
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
または、SearchIndexClient の getSearchClient() メソッドを使用して SearchClient を作成することもできます。
const searchClient = indexClient.getSearchClient(indexName);
クライアントが定義できたところで、ドキュメントを検索インデックスにアップロードします。 ここでは mergeOrUploadDocuments() メソッドを使用します。これにより、ドキュメントをアップロードしたり、同じキーのドキュメントが既に存在する場合に既存のドキュメントとマージしたりします。
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
node index.js でプログラムを再度実行します。 手順 1 で表示されたのとは若干異なるメッセージが表示されるはずです。 今回はインデックスが存在して "いる" ので、その削除に関するメッセージが表示されます。そしてその後に、アプリによって新しいインデックスが作成され、そこにデータがポストされます。
次の手順でクエリを実行する前に、プログラムを 1 秒間待機させる関数を定義します。 これは、インデックスの作成を確実に完了し、クエリ用のインデックスでドキュメントを利用できるようにするために、ただテストやデモの目的で行います。
function sleep(ms) {
var d = new Date();
var d2 = null;
do {
d2 = new Date();
} while (d2 - d < ms);
}
プログラムを 1 秒間待機させるには、以下のように sleep 関数を呼び出します。
sleep(1000);
インデックスを検索する
インデックスを作成し、ドキュメントをアップロードしたところで、クエリをインデックスに送信する準備が整いました。 このセクションでは、5 つの異なるクエリを検索インデックスに送信して、利用可能なさまざまなクエリ機能について説明します。
クエリは sendQueries() 関数で記述されます。それを、次のとおり main 関数で呼び出します。
await sendQueries(searchClient);
クエリは searchClient の search() メソッドを使用して送信されます。 1 つ目のパラメーターは検索テキストで、2 つ目のパラメーターは検索オプションを指定します。
最初のクエリでは * を検索します。これはすべてを検索することと同じで、インデックス内のフィールドのうち 3 つが選択されます。 不要なデータをプルするとクエリでの待ち時間が長くなる可能性があるため、必要なフィールドのみ select することをお勧めします。
このクエリの searchOptions は、includeTotalCount も true に設定されています。これにより、一致した結果の数が検出されて返されます。
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
以下で説明する残りのクエリも sendQueries() 関数に追加する必要があります。 ここでは読みやすいようにそれらを区切ってあります。
次のクエリでは、検索用語 "wifi" を指定します。また、状態が 'FL' と一致する結果のみが返されるようにフィルターも含めます。 さらに結果はホテルの Rating の順に並べられます。
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
次に、searchFields パラメーターを使用して検索が単一の検索可能なフィールドに制限されます。 この方法は、特定のフィールドとの一致にのみ関心があることがわかっている場合にクエリを効率化できる優れたオプションです。
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("Sublime Palace", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
クエリによく含められるもう 1 つのオプションは、facets です。 ファセットを使用すると、UI 上でフィルターを構築できます。そうすることで、ユーザーがどの値をフィルターで絞り込めるかを簡単に把握できるようになります。
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
最後のクエリでは、searchClient の getDocument() メソッドを使用します。 これにより、そのキーでドキュメントを効率的に取得できます。
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
サンプルを実行する
node index.jsを使用してプログラムを実行します。 今回は、これまでの手順に加えてクエリが送信され、結果がコンソールに書き込まれます。
@azure/search-documents ライブラリを使用して Node.js アプリケーションを構築し、検索インデックスの作成、読み込み、クエリの実行を行います。
代わりに、ソース コードをダウンロードして完成したプロジェクトから開始することも、次の手順に従って独自のアプリケーションを作成することもできます。
環境を設定する
このクイックスタートを作成するために、次のツールを使用しました。
プロジェクトの作成
Visual Studio Code を起動します。
Ctrl + Shift + P キーで コマンド パレット を開き、統合ターミナルを開きます。
開発用ディレクトリを作成して "quickstart" という名前を付けます。
mkdir quickstart
cd quickstart
次のコマンドを実行して、npm によって空のプロジェクトを初期化します。 プロジェクトを完全に初期化するには、Enter キーを複数回押して既定値をそのまま使用します。ただし、ライセンスは "MIT" に設定する必要があります。
npm init
@azure/search-documentsAzure AI Search 用の JavaScript/TypeScript SDKをインストールします。
npm install @azure/search-documents
dotenv をインストールします。これは、検索サービス名や API キーなど、環境変数をインポートするために使用されます。
npm install dotenv
"quickstart" ディレクトリに移動して、自分の package.json ファイルが次の json ファイルのようになっていることをチェックし、プロジェクトとその依存関係を構成できたことを確認します。
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^12.1.0",
"dotenv": "^16.4.5"
}
}
自分の検索サービスのパラメーターを保持するファイル .env を作成します。
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
YOUR-SEARCH-SERVICE-URL の値は、自分の検索サービス エンドポイント URL の名前に置き換えます。 <YOUR-SEARCH-ADMIN-API-KEY> は、前に記録した管理者キーに置き換えます。
index.ts ファイルを作成する
次は "index.ts" ファイルを作成します。これはコードをホストするメイン ファイルです。
このファイルの冒頭で、@azure/search-documents ライブラリをインポートします。
import {
AzureKeyCredential,
ComplexField,
odata,
SearchClient,
SearchFieldArray,
SearchIndex,
SearchIndexClient,
SearchSuggester,
SimpleField
} from "@azure/search-documents";
その後、次のように dotenv パッケージに対して require を実行し、 .env ファイルからパラメーターを読み取る必要があります。
// Load the .env file if it exists
import dotenv from 'dotenv';
dotenv.config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
インポートと環境変数を用意できたところで、main 関数を定義する準備が整いました。
SDK 内の機能のほとんどは非同期のため、ここでは main 関数を async にします。 また、main 関数の下に main().catch() も追加します。エラーが発生した場合にキャッチしてログに記録するためです。
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
それが済んだら、インデックスを作成する準備は完了です。
インデックスの作成
hotels_quickstart_index.json というファイルを作成します。 このファイルは、次のステップで読み込むドキュメントで Azure AI Search がどのように機能するかを定義します。 各フィールドは name によって識別されます。それぞれ、指定された type を備えています。 各フィールドには、Azure AI Search がフィールドで検索、フィルター処理、並べ替え、ファセットを実行できるかどうかを指定する一連のインデックス属性もあります。 ほとんどのフィールドは単純なデータ型ですが、AddressType のように、自分のインデックスでリッチなデータ構造を作成できる複合型もあります。 サポートされているデータ型とインデックスの属性について詳しくは、インデックスの作成 (REST) に関するページを参照してください。
次の内容を hotels_quickstart_index.json に追加するか、ファイルをダウンロードします。
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
インデックスの定義が完了したら、main 関数でインデックスの定義にアクセスできるように、index.ts の冒頭で hotels_quickstart_index.json をインポートする必要があります。
// Importing the index definition and sample data
import indexDefinition from './hotels_quickstart_index.json';
interface HotelIndexDefinition {
name: string;
fields: SimpleField[] | ComplexField[];
suggesters: SearchSuggester[];
};
const hotelIndexDefinition: HotelIndexDefinition = indexDefinition as HotelIndexDefinition;
main 関数内で、 SearchIndexClientを作成します。これは、Azure AI Search のインデックスの作成と管理に使用されます。
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
次に、インデックスが既に存在する場合はそれを削除します。 この操作は、テストやデモのコードでは一般的な手法です。
これを行うには、インデックスの削除を試行する単純な関数を定義します。
async function deleteIndexIfExists(indexClient: SearchIndexClient, indexName: string): Promise<void> {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
関数を実行するには、インデックス定義からインデックス名を抽出し、indexClient と共に indexName を deleteIndexIfExists() 関数に渡します。
// Getting the name of the index from the index definition
const indexName: string = hotelIndexDefinition.name;
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
その後、createIndex() メソッドを使用してインデックスを作成する準備が整います。
console.log('Creating index...');
let index = await indexClient.createIndex(hotelIndexDefinition);
console.log(`Index named ${index.name} has been created.`);
サンプルを実行する
この時点で、サンプルをビルドして実行する準備ができました。 ターミナル ウィンドウを使用して、次のコマンドを実行し、tsc でソースをビルドし、その後、node でソースを実行します。
tsc
node index.ts
ソース コードをダウンロードしていても、必須のパッケージをまだインストールしていない場合は、最初に npm install を実行します。
プログラムにより実行されているアクションを示す一連のメッセージが表示されます。
Azure portal で、自分の検索サービスの [概要] を開きます。 [インデックス] タブを選択します。次の例のように表示されます。
次の手順では、インデックスにデータを追加します。
ドキュメントを読み込む
Azure AI Search では、ドキュメントはインデックス作成への入力とクエリからの出力の両方であるデータ構造です。 このようなデータをインデックスにプッシュするか、インデクサーを使用することができます。 ここでは、プログラムでドキュメントをインデックスにプッシュします。
ドキュメント入力には、データベース内の行、Blob Storage 内の BLOB、またはこの例のようなディスク上の JSON ドキュメントがあります。 hotels.json をダウンロードするか、次の内容を使って独自の hotels.json ファイルを作成できます。
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
indexDefinition で行ったのと同様に、main 関数でデータにアクセスできるように、index.ts の冒頭で hotels.json をインポートする必要もあります。
import hotelData from './hotels.json';
interface Hotel {
HotelId: string;
HotelName: string;
Description: string;
Description_fr: string;
Category: string;
Tags: string[];
ParkingIncluded: string | boolean;
LastRenovationDate: string;
Rating: number;
Address: {
StreetAddress: string;
City: string;
StateProvince: string;
PostalCode: string;
};
};
const hotels: Hotel[] = hotelData["value"];
データに検索インデックスを付けるために、次は SearchClient を作成する必要があります。 SearchIndexClient はインデックスの作成と管理に使用され、SearchClient はドキュメントのアップロードとインデックスのクエリに使用されます。
SearchClient は 2 とおりの方法で作成できます。 1 つには、ゼロから SearchClient を作成する方法があります。
const searchClient = new SearchClient<Hotel>(endpoint, indexName, new AzureKeyCredential(apiKey));
または、SearchIndexClient の getSearchClient() メソッドを使用して SearchClient を作成することもできます。
const searchClient = indexClient.getSearchClient<Hotel>(indexName);
クライアントが定義できたところで、ドキュメントを検索インデックスにアップロードします。 ここでは mergeOrUploadDocuments() メソッドを使用します。これにより、ドキュメントをアップロードしたり、同じキーのドキュメントが既に存在する場合に既存のドキュメントとマージしたりします。 次に、少なくとも最初のドキュメントが存在していることを確認し、操作が成功したことを確認します。
console.log("Uploading documents...");
const indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotels);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
tsc && node index.ts でプログラムを再度実行します。 手順 1 で表示されたのとは若干異なるメッセージが表示されるはずです。 今回はインデックスが存在して "いる" ので、その削除に関するメッセージが表示されます。そしてその後に、アプリによって新しいインデックスが作成され、そこにデータがポストされます。
次の手順でクエリを実行する前に、プログラムを 1 秒間待機させる関数を定義します。 これは、インデックスの作成を確実に完了し、クエリ用のインデックスでドキュメントを利用できるようにするために、ただテストやデモの目的で行います。
function sleep(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
プログラムを 1 秒間待機させるには、sleep 関数を呼び出します。
sleep(1000);
インデックスを検索する
インデックスを作成し、ドキュメントをアップロードしたところで、クエリをインデックスに送信する準備が整いました。 このセクションでは、5 つの異なるクエリを検索インデックスに送信して、利用可能なさまざまなクエリ機能について説明します。
クエリは sendQueries() 関数で記述されます。それを、次のとおり main 関数で呼び出します。
await sendQueries(searchClient);
クエリは searchClient の search() メソッドを使用して送信されます。 1 つ目のパラメーターは検索テキストで、2 つ目のパラメーターは検索オプションを指定します。
最初のクエリでは * を検索します。これはすべてを検索することと同じで、インデックス内のフィールドのうち 3 つが選択されます。 不要なデータをプルするとクエリでの待ち時間が長くなる可能性があるため、必要なフィールドのみ select することをお勧めします。
このクエリでは、searchOptions の includeTotalCount が true に設定されています。これにより、一致した結果の数が検出されて返されます。
async function sendQueries(
searchClient: SearchClient<Hotel>
): Promise<void> {
// Query 1
console.log('Query #1 - search everything:');
const selectFields: SearchFieldArray<Hotel> = [
"HotelId",
"HotelName",
"Rating",
];
const searchOptions1 = {
includeTotalCount: true,
select: selectFields
};
let searchResults = await searchClient.search("*", searchOptions1);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
以下で説明する残りのクエリも sendQueries() 関数に追加する必要があります。 ここでは読みやすいようにそれらを区切ってあります。
次のクエリでは、検索用語 "wifi" を指定します。また、状態が 'FL' と一致する結果のみが返されるようにフィルターも含めます。 さらに結果はホテルの Rating の順に並べられます。
console.log('Query #2 - search with filter, orderBy, and select:');
let state = 'FL';
const searchOptions2 = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: selectFields
};
searchResults = await searchClient.search("wifi", searchOptions2);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
次に、searchFields パラメーターを使用して検索が単一の検索可能なフィールドに制限されます。 この方法は、特定のフィールドとの一致にのみ関心があることがわかっている場合にクエリを効率化できる優れたオプションです。
console.log('Query #3 - limit searchFields:');
const searchOptions3 = {
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("Sublime Palace", searchOptions3);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
クエリによく含められるもう 1 つのオプションは、facets です。 ファセットを使用すると、UI の結果からユーザーが自身で絞り込みを行うことができます。 ファセットの結果は、結果ウィンドウのチェック ボックスに変えることができます。
console.log('Query #4 - limit searchFields and use facets:');
const searchOptions4 = {
facets: ["Category"],
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("*", searchOptions4);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
最後のクエリでは、searchClient の getDocument() メソッドを使用します。 これにより、そのキーでドキュメントを効率的に取得できます。
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument('3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
サンプルを再実行する
tsc && node index.ts を使用してプログラムをビルドして実行します。 今回は、これまでの手順に加えてクエリが送信され、結果がコンソールに書き込まれます。
独自のサブスクリプションを使用している場合は、プロジェクトの最後に、作成したリソースがまだ必要かどうかを確認してください。 リソースを実行したままにすると、お金がかかる場合があります。 リソースを個別に削除するか、リソース グループを削除してリソースのセット全体を削除することができます。
無料サービスを使っている場合は、3 つのインデックス、インデクサー、およびデータソースに制限されることに注意してください。 Azure portal で個別の項目を削除して、制限を超えないようにすることができます。
このクイックスタートでは、インデックスの作成、それとドキュメントの読み込み、およびクエリの実行を行うという一連のタスクに取り組みました。 さまざまな段階で、読みやすく、理解しやすいように、手短な方法として、コードを簡略化しました。 基本的な概念を理解したら、Web アプリで Azure AI Search API を呼び出すチュートリアルをお試しください。