Azure Blob Storage のコンテンツを検索する
Azure Blob Storage に格納されているさまざまなコンテンツ タイプを検索することは解決困難な問題となることがありますが、Azure AI Search では、コンテンツ レイヤーでの深い統合が提供され、検索インデックスで照会可能なテキスト情報が抽出され、推論されます。
この記事では、BLOB からコンテンツとメタデータを抽出し、それを Azure AI Search の検索インデックスに送信するための基本的なワークフローについて説明します。 結果のインデックスには、フルテキスト検索またはベクトル検索を使用してクエリを実行できます。 必要に応じて、非検索シナリオのために、処理した BLOB コンテンツをナレッジ ストアに送信できます。
Note
ワークフローとコンポジションについて既によく理解している場合、 次の手順は BLOB インデクサーの構成です。
BLOB データに対して検索を追加する意味
Azure AI 検索はスタンドアロン検索サービスであり、クラウド内でホストされているプライベート検索可能なコンテンツを含むユーザー定義のインデックスに対して、インデックス作成とクエリ ワークロードをサポートします。 検索可能なコンテンツとクエリ エンジンをクラウド内に併置することは、パフォーマンス上必要であり、これにより、ユーザーが検索クエリに期待する速度で結果を返すことができます。
Azure AI 検索はインデックス層で Azure Blob Storage と統合されます。これにより、ご利用の BLOB コンテンツは、逆インデックスや、自由形式のテキスト クエリ、ベクトル クエリ、フィルター式をサポートするその他のクエリ構造体に、インデックスが作成された検索ドキュメントとしてインポートされます。 ご利用の BLOB コンテンツは検索インデックスに対してインデックスが作成されるため、Azure AI Search 内のすべてのクエリ機能を使用して、BLOB コンテンツ内の情報を見つけることができます。
Azure Blob Storage 内の単一コンテナーにある BLOB が入力となります。 BLOB は、ほぼ任意の種類のテキスト データとすることができます。 ご利用の BLOB に画像が含まれている場合は、AI エンリッチメントを追加して、画像からテキストと特徴を作成および抽出することができます。
出力は常に Azure AI Search インデックスであり、これはクライアント アプリケーションでの高速テキスト検索、取得、および探索に使用されます。 中間にあるのは、インデックス作成のパイプライン アーキテクチャそのものです。 パイプラインは、この記事で詳しく説明する "インデクサー" 機能に基づいています。
インデックスが作成され設定されると、それはご利用の BLOB コンテナーとは独立した存在となりますが、変更が生じたドキュメントに基づいてインデックス作成操作を再実行することでインデックスを更新することができます。 変更を検出するには、個々の BLOB に関するタイムスタンプ情報が使用されます。 更新メカニズムとしては、スケジュールされた実行またはオンデマンドのインデックス作成のいずれかを選択できます。
BLOB 検索ソリューションで使用されるリソース
Azure AI Search、Azure Blob Storage、およびクライアントが必要です。 Azure AI Search は、通常、アプリケーション コードによってクエリ API 要求を発行して応答を処理するソリューション内のいくつかのコンポーネントの 1 つです。 また、インデックス作成を処理するアプリケーション コードを記述することもできますが、概念実証のテストと即席のタスクには、Azure portal を検索クライアントとして使用するのが一般的です。
Blob Storage 内には、ソース コンテンツを提供するコンテナーが必要です。 ファイルの含有と除外の条件を設定し、Azure AI Search で BLOB のどの部分にインデックスを作成するかを指定できます。
ご自分のストレージ アカウント ポータル ページで直接開始できます。
左側ナビゲーション ページ内の [データ管理] の下で、[Azure AI 検索] を選択して検索サービスを選択または作成します。
ウィザードの手順に従って、BLOB から検索可能なコンテンツを抽出し、必要に応じて作成します。 ワークフローは、データのインポート ウィザードです。 このワークフローでは、ご利用の Azure AI 検索サービス上に、インデクサー、データ ソース、インデックス、オプション スキルセットが作成されます。
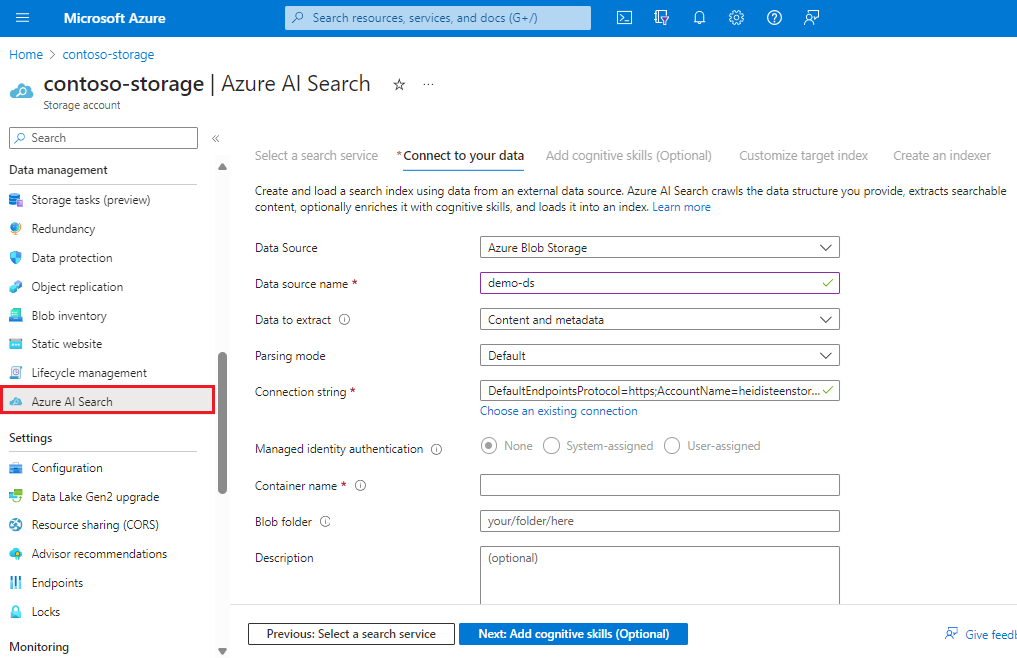
検索ポータル ページの Search エクスプローラーを使用して、コンテンツのクエリを実行します。
ウィザードは開始するのに最適な場所ですが、自分で BLOB インデクサーを構成する場合、より柔軟なオプションを使用することができます。 REST クライアントを使用できます。 「チュートリアル: 半構造化されたデータ (JSON BLOB) のインデックス作成と検索」では、REST API を呼び出す手順について説明しています。
BLOB のインデックスを付ける方法
既定では、JSON や CSV などの構造化コンテンツを持つ BLOB を含め、ほとんどの BLOB はインデックス内で 1 つの検索ドキュメントとしてインデックスが作成されます。 ただし、JSON または CSV ドキュメントに内部構造 (区切り記号) がある場合は、解析モードを割り当てて、行または要素ごとに個別の検索ドキュメントを生成できます。
複合または埋め込みドキュメント (ZIP アーカイブ、添付ファイルが含まれている Outlook メールが埋め込まれた Word 文書、添付ファイル付き .MSG ファイルなど) も、1 つのドキュメントとして、インデックスが作成されます。 例えば、.MSG ファイルの添付ファイルから抽出されたすべての画像が normalized_images フィールドに返されます。 画像がある場合は、そのコンテンツからさらに検索ユーティリティを取得するために AI エンリッチメントを追加することを検討してください。
ドキュメントのテキスト コンテンツが、"content" という名前の文字列フィールドに抽出されます。 標準およびユーザー定義のメタデータを抽出することもできます。
Note
Azure AI Search によって抽出されるテキストの量には、価格レベルに応じてインデクサーの制限が適用されます。 ドキュメントが切り捨てられると、インデクサーの状態の応答に警告が含められます。
コンテンツの抽出に BLOB インデクサーを使用する
インデクサーは、Azure AI Search のデータソースに対応したサブサービスであり、データのサンプリング、データとメタデータの読み取りと取得、および後続のインポートに備えたネイティブ形式から JSON ドキュメントへのデータのシリアル化、などを行うための内部ロジックを備えています。
Azure Storage 内の BLOB は、BLOB インデクサー を使用してインデックス付けされます。 このインデクサーは、Azure Storage 内での Azure AI 検索コマンド、データのインポート ウィザード、REST API、または .NET SDK を使用して呼び出すことができます。 コード内でこのインデクサーを使用するには、種類を設定してから、Azure Storage アカウントおよび BLOB コンテナーを含む接続情報を指定します。 ご利用の BLOB のサブセットを作成するには、パラメーターとして渡すことができる仮想ディレクトリを作成するか、ファイルの種類の拡張子に基づいてフィルター処理を行います。
インデクサーでは、"ドキュメント解析" を行い、BLOB を開いてコンテンツが検査されます。 データソースに接続したら、それがパイプラインでの最初のステップとなります。 BLOB データの場合は、ここで、PDF、Office ドキュメント、その他のコンテンツの種類が検出されます。 テキストの抽出によるドキュメント解析は課金の対象外です。 ご利用の BLOB に画像コンテンツが含まれている場合、AI エンリッチメントを追加しない限り、画像は無視されます。 標準のインデックス作成は、テキスト コンテンツのみに適用されます。
Azure BLOB インデクサーでは、構成パラメーターが用意されているほか、基になるデータに十分な情報が提供されている場合は、変更の追跡がサポートされます。 コア機能の詳細については、「Azure Blob Storage のデータにインデックスを作成する」を参照してください。
サポートされているアクセス層
Blob Storage のアクセス層には、ホット、クール、コールド、アーカイブがあります。 インデクサーでは、ホット、クール、コールドのアクセス層で BLOB を取得できます。
サポートされているコンテンツの種類
コンテナーに対して BLOB インデクサーを実行すれば、次のコンテンツの種類からテキストとメタデータを 1 回のクエリで抽出することができます。
- CSV (CSV BLOB のインデックス作成に関する記事を参照)
- EML
- EPUB
- GZ
- HTML
- JSON (JSON BLOB のインデックス作成に関する記事を参照)
- KML (地理的表現の XML)
- Microsoft Office 形式: DOCX/DOC/DOCM、XLSX/XLS/XLSM、PPTX/PPT/PPTM、MSG (Outlook 電子メール)、XML (2003 と 2006 両方の WORD XML)
- オープン ドキュメント形式: ODT、ODS、ODP
- プレーンテキスト ファイル (「プレーン テキストのインデックス作成」も参照)
- RTF
- XML
- 郵便番号
インデックスが作成される BLOB の制御
インデックスを作成する BLOB とスキップする BLOB は、BLOB のファイルの種類によって、または BLOB 自体にプロパティを設定してインデクサーに BLOB をスキップさせることによって制御できます。
特定のファイル拡張子を含めるには、"indexedFileNameExtensions" をファイル拡張子 (先頭のドットを含む) のコンマ区切りリストに設定します。 特定のファイル拡張子を除外するには、"excludedFileNameExtensions" をスキップする拡張子に設定します。 同じファイル拡張子が両方のリストにある場合、それはインデックス作成から除外されます。
PUT /indexers/[indexer name]?api-version=2024-07-01
{
"parameters" : {
"configuration" : {
"indexedFileNameExtensions" : ".pdf, .docx",
"excludedFileNameExtensions" : ".png, .jpeg"
}
}
}
"スキップ" メタデータを BLOB に追加する
インデクサーの構成パラメーターは、コンテナーまたはフォルダー内のすべての BLOB に適用されます。 ときには、"個々の BLOB" のインデックスの作成方法を制御することが必要です。
次のメタデータのプロパティと値を BLOB ストレージ内の BLOB に追加します。 インデクサーでこのプロパティが検出されると、インデックス作成の実行時に BLOB またはそのコンテンツがスキップされます。
| プロパティ名 | プロパティ値 | 説明 |
|---|---|---|
| "AzureSearch_Skip" | "true" |
BLOB を完全にスキップするように BLOB インデクサーに指示します。 メタデータとコンテンツのどちらの抽出も行われません。 特定の BLOB で何度もエラーが発生し、インデックス作成プロセスが中断されるときに利用できます。 |
| "AzureSearch_SkipContent" | "true" |
これは、特定の BLOB を対象とする、上述の "dataToExtract" : "allMetadata" 設定と同じです。 |
BLOB メタデータのインデックス作成
任意のコンテンツの種類を含む BLOB の並べ替えを容易にする一般的なシナリオは、各 BLOB でカスタム メタデータとシステム プロパティの両方のインデックスを作成することです。 そうすることで、検索サービス内のインデックスに格納されているドキュメントの種類に関係なく、すべての BLOB の情報のインデックスが作成されます。 新しいインデックスを使用すれば、すべての BLOB ストレージ コンテンツの並べ替え、フィルター処理、およびファセット処理を行うことができます。
Note
BLOB インデックス タグは、BLOB ストレージ サービスによってネイティブにインデックスが付けられ、クエリのために公開されます。 ご利用の BLOB のキー/値の属性にインデックス作成とフィルタリングの機能が必要な場合は、メタデータの代わりに BLOB インデックス タグを使用する必要があります。
BLOB インデックスの詳細については、「BLOB インデックスを使用して Azure Blob Storage でデータを管理および検索する」を参照してください。
検索インデックス内の BLOB コンテンツを検索する
インデクサーの出力は検索インデックスです。これは、クライアント アプリでフリー テキストとフィルター処理されたクエリを使用して対話型探索を行う場合に使用されます。 コンテンツの探索と検証を初めて行う場合は、Azure portal 内の検索エクスプローラーを使用したドキュメントの構造の確認から始めることをお勧めします。 Search エクスプローラーでは、次のものを使用できます。
より永続的な解決策は、クエリ入力を収集し、クライアント アプリケーションでの検索結果として応答を提示することです。 ASP.NET Core (MVC) アプリケーションへの検索の追加に関する記事の C# チュートリアルでは、検索アプリケーションを構築する方法について説明します。