チュートリアル: Azure Storage から入れ子になった JSON BLOB のインデックスを REST を使用して作成する
Azure AI Search は、半構造化データの読み取り方法を解しているインデクサーを使用して、Azure Blob Storage に格納されている JSON のドキュメントや配列のインデックスを作成することができます。 半構造化データには、データ内のコンテンツを区別するタグやマーキングが含まれます。 これは、全体にインデックスを付ける必要がある非構造化データと、フィールドごとにインデックス付け可能でリレーショナル データベース スキーマなどのデータ モデルに準拠した正式な構造化データの違いを分割するものです。
このチュートリアルでは、入れ子になった JSON 配列のインデックスを作成する方法について説明します。 REST クライアントと Search REST API を使用して次のタスクを実行します。
- サンプル データを設定し、
azureblobデータ ソースを構成する - 検索可能なコンテンツを格納する Azure AI Search インデックスを作成する
- インデクサーを作成して実行してコンテナーを読み取り、検索可能なコンテンツを抽出する
- 作成したインデックスを検索する
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
Azure AI 検索. 現在のサブスクリプションで、既存の Azure AI 検索サービスを見つけるか、または作成します。
Note
このチュートリアルには無料のサービスを使用できます。 無料の検索サービスでは、3 つのインデックス、3 つのインデクサー、3 つのデータ ソースという制限があります。 このチュートリアルでは、それぞれ 1 つずつ作成します。 開始する前に、ご利用のサービスに新しいリソースを受け入れる余地があることを確認してください。
ファイルのダウンロード
サンプル データ リポジトリの zip ファイルをダウンロードし、内容を抽出します。 方法については、こちらをご覧ください。
サンプル データは、JSON 配列と 1,521 個の入れ子になった JSON 要素を含む単一の JSON ファイルです。 サンプル データのオリジナルは、Kaggle の NY フィルハーモニックの公演の歴史です。 Free レベルのストレージ制限に収まるように、1 つの JSON ファイルを選択しました。
ファイル内の最初の入れ子になった JSON を次に示します。 ファイルの残りの部分には、コンサート公演の他の 1,520 のインスタンスが含まれています。
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
サンプル データを Azure Storage にアップロードする
Azure Storage で新しいコンテナーを作成し、ny-philharmonic-free という名前を付けてください。
Azure AI 検索で接続を作成できるように、ストレージ接続文字列を取得します。
左側で、[アクセス キー] を選びます。
キー 1 またはキー 2 の接続文字列をコピーします。 接続文字列は、次の例のような URL です:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
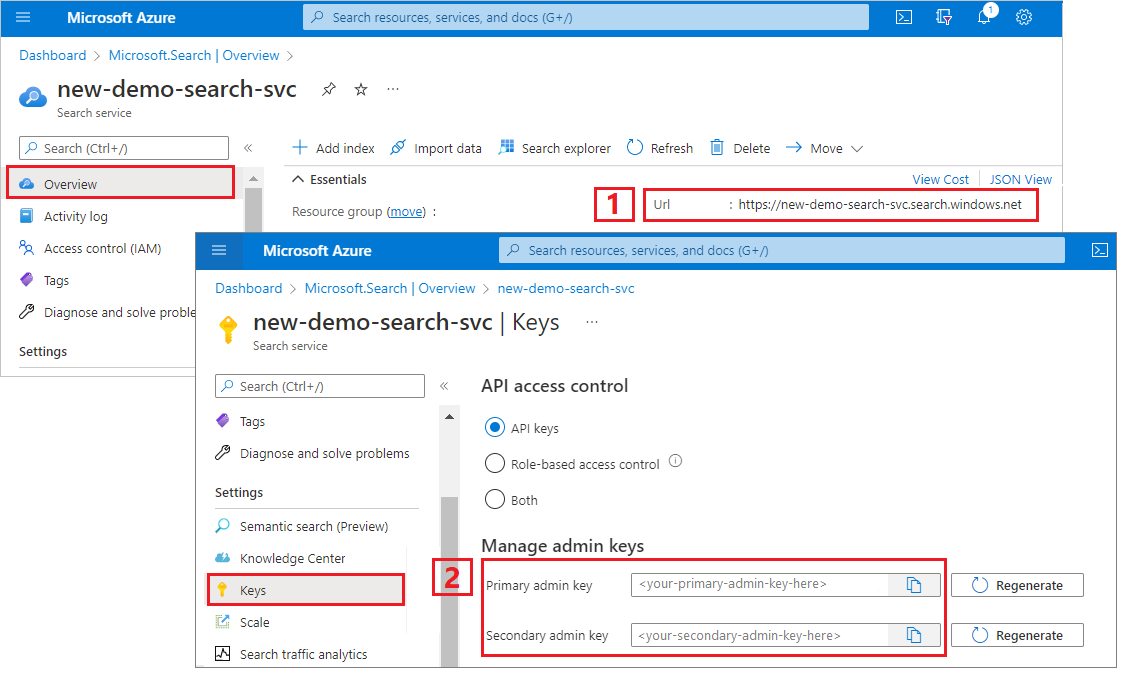
検索サービスの URL と API キーをコピーする
このチュートリアルでは、Azure AI 検索への接続にエンドポイントと API キーが必要です。 これらの値は Azure portal から取得できます。
Azure portal にサインインし、検索サービスの [概要] ページに移動して URL をコピーします。 たとえば、エンドポイントは
https://mydemo.search.windows.netのようになります。[設定]>[キー] で管理者キーをコピーします。 管理者キーは、オブジェクトの追加、変更、削除で使用します。 2 つの交換可能な管理者キーがあります。 どちらかをコピーします。
REST ファイルを設定する
Visual Studio Code を起動して、新しいファイルを作成します
要求で使用される変数の値を指定します。
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREファイル拡張子
.restまたは.httpを使用してファイルを保存します。
REST クライアントに関するヘルプが必要な場合は、「クイック スタート: REST を使用したテキスト検索」を参照してください。
データ ソースを作成する
データ ソースの作成 (REST) では、インデックスを付けるデータを指定するデータ ソース接続を作成します。
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
要求を送信します。 応答は次のようになります。
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
インデックスを作成する
インデックスの作成 (REST) では、検索サービスに検索インデックスを作成します。 インデックスでは、すべてのパラメーターとその属性を指定します。
入れ子になった JSON の場合、インデックス フィールドはソース フィールドと同じである必要があります。 現在、Azure AI 検索では、入れ子になった JSON へのフィールド マッピングはサポートされていません。 このため、フィールド名とデータ型は完全に一致する必要があります。 次のインデックスは、生コンテンツの JSON 要素に合わせて配置されます。
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
重要なポイント:
フィールド マッピングを使用して、フィールド名またはデータ型の違いを調整することはできません。 このインデックス スキーマは、生のコンテンツをミラーリングするように設計されています。
入れ子になった JSON は、
Collection(Edm.ComplextType)としてモデル化されます。 生コンテンツでは、季節ごとに複数のコンサートがあり、各コンサートに複数の作品があります。 この構造体に対応するには、複合型のコレクションを使用します。生コンテンツでは、
DateとTimeは文字列であるため、インデックス内の対応するデータ型も文字列になります。
インデクサーの作成と実行
インデクサーの作成では、検索サービスにインデクサーを作成します。 インデクサーではデータ ソースに接続し、インデックス データを読み込み、データ更新を自動化するスケジュールを必要に応じて提供します。
インデクサーの構成には、jsonArray 解析モードと documentRoot が含まれます。
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
重要なポイント:
生コンテンツ ファイルには、1,526 個の入れ子になった JSON 構造を持つ JSON 配列 (
"programs") が含まれています。parsingModeをjsonArrayに設定して、各 BLOB に JSON 配列が含まれていることをインデクサーに通知します。 入れ子になった JSON は 1 レベル下から開始されるため、documentRootを/programsに設定します。インデクサーは数分間実行されます。 インデクサーの実行が完了するまで待ってから、クエリを実行してください。
クエリを実行する
最初のドキュメントが読み込まれたらすぐに、検索を始めることができます。
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
要求を送信します。 これは、指定のないフルテキスト検索クエリです。インデックスで取得可能としてマークされたすべてのフィールドがドキュメント数と共に返されます。 応答は次のようになります。
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
文字列で検索する search パラメーターを追加します。 結果を数フィールドに限定するため、select パラメーターを追加します。 検索をさらに絞り込むには、filter を追加してください。
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
応答で 2 つのドキュメントが返されます。
フィルター処理のため、論理演算子 (and、or、not) と比較演算子 (eq、ne、gt、lt、ge、le) を使用することもできます。 文字列比較では大文字と小文字が区別されます。 詳細と例については、クエリを作成する方法に関するページを参照してください。
Note
$filter パラメーターは、インデックスの作成時にフィルター可能としてマークされたフィールドでのみ使用できます。
リセットして再実行する
インデクサーをリセットして実行履歴をクリアすると、完全な再実行が可能になります。 次の GET 要求はリセット用であり、その後に再実行されます。
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースを個別に削除するか、リソース グループを削除してリソースのセット全体を削除することができます。
Azure portal を使って、インデックス、インデクサー、データ ソースを削除できます。
次のステップ
Azure Blob のインデックス作成の基礎を理解したら、Azure Storage 内の JSON BLOB に使用されるインデクサーの構成について詳しく見てみましょう。