C# チュートリアル: スキルセットを使用して Azure AI 検索で検索可能なコンテンツを生成する
このチュートリアルでは、インデックス作成中にコンテンツの抽出と変換のための AI エンリッチメント パイプライン を作成する Azure SDK for .NET の使用方法について説明します。
スキルセットは生コンテンツに AI 処理を追加し、そのコンテンツをより統一して検索できるようにします。 スキルセットのしくみを把握したら、画像分析から自然言語処理、外部から提供するカスタマイズされた処理まで、幅広い変換をサポートできます。
このチュートリアルでは、次のことを行う方法について説明します:
- エンリッチメント パイプラインでオブジェクトを定義する。
- スキルセットを構築する。 OCR、言語検出、エンティティ認識、キー フレーズ抽出を呼び出します。
- パイプラインを実行する。 検索インデックスを作成して読み込みます。
- フルテキスト検索を使用して結果を確認する。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
概要
このチュートリアルでは、C# と Azure.Search.Documents クライアント ライブラリを使用して、データ ソース、インデックス、インデクサー、およびスキルセットを作成します。
インデクサーは、Azure Storage 上の BLOB コンテナー内のサンプル データ (非構造化テキストとイメージ) のコンテンツ抽出から始めて、パイプライン内の各ステップを実行します。
コンテンツが抽出されると、スキルセットは Microsoft の組み込みスキルを実行して情報を検索および抽出します。 これらのステップには、画像の光学式文字認識 (OCR)、テキストの言語検出、キーフレーズの抽出、エンティティ認識 (組織) が含まれます。 スキルセットによって作成された新しい情報は、インデックス内のフィールドに送信されます。 インデックスが作成されると、クエリ、ファセット、およびフィルター内のフィールドを使用できるようになります。
必須コンポーネント
Note
このチュートリアルには無料の検索サービスを使用できます。 Free レベルでは、インデックス、インデクサー、データ ソースがそれぞれ 3 つに限定されています。 このチュートリアルでは、それぞれ 1 つずつ作成します。 開始する前に、ご利用のサービスに新しいリソースを受け入れる余地があることを確認してください。
ファイルのダウンロード
サンプル データ リポジトリの zip ファイルをダウンロードし、内容を抽出します。 方法については、こちらをご覧ください。
サンプル データを Azure Storage にアップロードする
Azure Storage で新しいコンテナーを作成し、cog-search-demo という名前を付けます。
Azure AI 検索で接続を作成できるように、ストレージ接続文字列を取得します。
左側で、[アクセス キー] を選びます。
キー 1 またはキー 2 の接続文字列をコピーします。 接続文字列は、次の例のような URL です:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Azure AI サービス
組み込みの AI エンリッチメントは、自然言語と画像の処理のための言語サービスや Azure AI Vision などの Azure AI サービスによってサポートされています。 このチュートリアルのような小規模なワークロードでは、インデクサーごとに 20 トランザクションの無料割り当てを使用できます。 大規模なワークロードの場合は、Azure AI サービスのマルチリージョン リソースを従量課金制の価格のスキルセットにアタッチします。
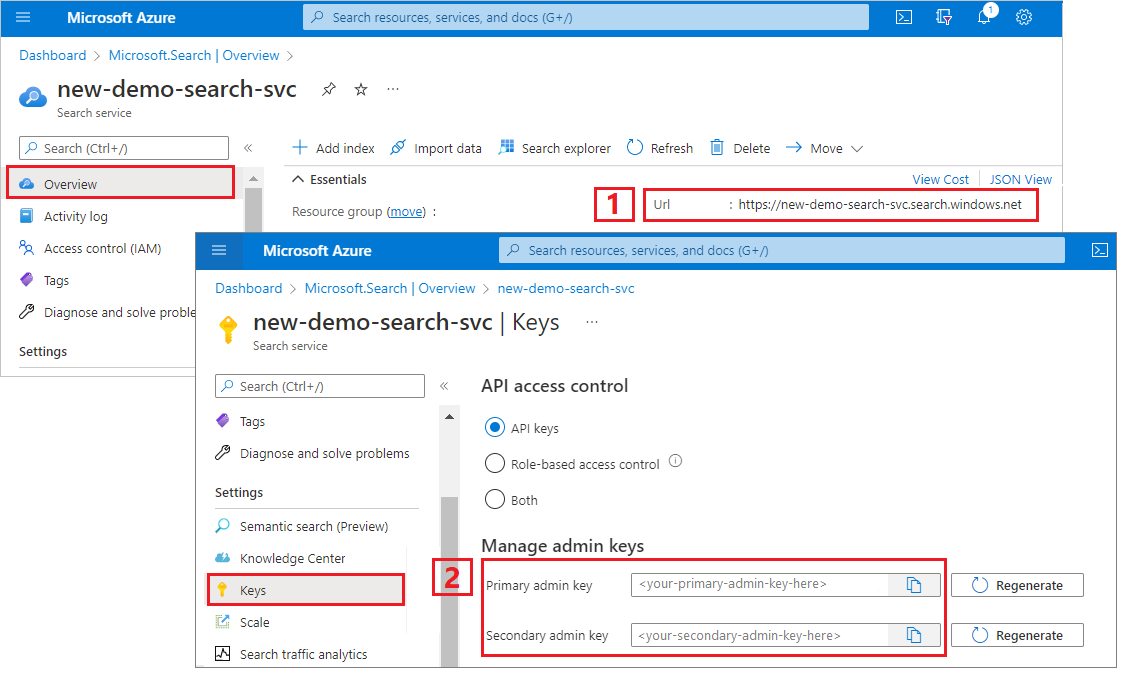
検索サービスの URL と API キーをコピーする
このチュートリアルでは、Azure AI 検索への接続にエンドポイントと API キーが必要です。 これらの値は Azure portal から取得できます。
Azure portal にサインインし、検索サービスの [概要] ページに移動して URL をコピーします。 たとえば、エンドポイントは
https://mydemo.search.windows.netのようになります。[設定]>[キー] で管理者キーをコピーします。 管理者キーは、オブジェクトの追加、変更、削除で使用します。 2 つの交換可能な管理者キーがあります。 どちらかをコピーします。
環境を設定する
まず Visual Studio を開き、.NET Core 上で実行する新しいコンソール アプリ プロジェクトを作成します。
Azure.Search.Documents をインストールする
Azure AI Search .NET SDK はクライアント ライブラリで構成されており、これにより、HTTP と JSON の詳細を扱わなくても、インデックス、データ ソース、インデクサー、スキルセットの管理や、ドキュメントのアップロードと管理やクエリの実行を行うことができます。 このクライアント ライブラリは、NuGet パッケージとして配布されます。
このプロジェクトでは、Azure.Search.Documents のバージョン 11 以降および Microsoft.Extensions.Configuration の最新バージョンをインストールします。
Visual Studio で、[ツール]>[NuGet パッケージ マネージャー]>[ソリューションの NuGet パッケージの管理] を選択します。
Azure.Search.Document を参照します。
最新バージョンを選択し、[インストール] を選択します。
前の手順を繰り返して、Microsoft.Extensions.Configuration と Microsoft.Extensions.Configuration.Json をインストールします。
サービス接続情報の追加
ソリューション エクスプローラーでプロジェクトを右クリックし、 [追加]>[新しい項目] を選択します。
ファイルに
appsettings.jsonという名前を付けて、 [追加] を選択します。このファイルを出力ディレクトリに追加します。
appsettings.jsonを右クリックし、 [プロパティ] を選択します。- [出力ディレクトリにコピー] の値を [新しい場合はコピーする] に変更します。
次の JSON を新しい JSON ファイルにコピーします。
{ "SearchServiceUri": "<YourSearchServiceUri>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "SearchServiceQueryApiKey": "<YourSearchServiceQueryApiKey>", "AzureAIServicesKey": "<YourMultiRegionAzureAIServicesKey>", "AzureBlobConnectionString": "<YourAzureBlobConnectionString>" }
検索サービスと BLOB ストレージ アカウントの情報を追加します。 ご存じのように、この情報は、前のセクションで示したサービス プロビジョニング手順から入手することができます。
SearchServiceUri では、完全な URL を入力します。
名前空間の追加
Program.cs に次の名前空間を追加します。
using Azure;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Microsoft.Extensions.Configuration;
using System;
using System.Collections.Generic;
using System.Linq;
namespace EnrichwithAI
クライアントの作成
Main の下に SearchIndexClient と SearchIndexerClient のインスタンスを作成します。
public static void Main(string[] args)
{
// Create service client
IConfigurationBuilder builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceUri = configuration["SearchServiceUri"];
string adminApiKey = configuration["SearchServiceAdminApiKey"];
string azureAiServicesKey = configuration["AzureAIServicesKey"];
SearchIndexClient indexClient = new SearchIndexClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
SearchIndexerClient indexerClient = new SearchIndexerClient(new Uri(searchServiceUri), new AzureKeyCredential(adminApiKey));
}
注意
クライアントは検索サービスに接続します。 開いている接続の数が多くなりすぎないように、可能であれば、アプリケーションで 1 つのインスタンスを共有するようにしてください。 そのメソッドはスレッドセーフなので、このような共有が可能です。
障害時にプログラムを終了するための関数を追加する
このチュートリアルは、インデックス作成パイプラインの各ステップを読者にわかりやすく伝えることを意図しています。 データ ソース、スキルセット、インデックス、またはインデクサーの作成に支障が生じるような重大な問題が発生した場合、プログラムは問題を伝え、対応を促すために、エラー メッセージを出力して終了します。
プログラムの終了を余儀なくされるようなシナリオには、ExitProgram を Main に追加することで対応します。
private static void ExitProgram(string message)
{
Console.WriteLine("{0}", message);
Console.WriteLine("Press any key to exit the program...");
Console.ReadKey();
Environment.Exit(0);
}
パイプラインを作成する
Azure AI Search では、AI 処理はインデックス作成 (またはデータ インジェスト) 中に行われます。 チュートリアルのこの部分では、データ ソース、インデックス定義、スキルセット、インデクサーという 4 つのオブジェクトを作成します。
手順 1:データ ソースを作成する
SearchIndexerClient には、SearchIndexerDataSourceConnection オブジェクトに設定できる DataSourceName プロパティがあります。 このオブジェクトは、Azure AI Search データ ソースの作成、一覧表示、更新、または削除に必要なすべてのメソッドを提供します。
indexerClient.CreateOrUpdateDataSourceConnection(dataSource) を呼び出して新しい SearchIndexerDataSourceConnection を作成します。 次のコードでは、AzureBlob 型のデータ ソースが作成されます。
private static SearchIndexerDataSourceConnection CreateOrUpdateDataSource(SearchIndexerClient indexerClient, IConfigurationRoot configuration)
{
SearchIndexerDataSourceConnection dataSource = new SearchIndexerDataSourceConnection(
name: "demodata",
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["AzureBlobConnectionString"],
container: new SearchIndexerDataContainer("cog-search-demo"))
{
Description = "Demo files to demonstrate Azure AI Search capabilities."
};
// The data source does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateDataSourceConnection(dataSource);
}
catch (Exception ex)
{
Console.WriteLine("Failed to create or update the data source\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a data source");
}
return dataSource;
}
要求が成功すると、作成されたデータ ソースがメソッドから返されます。 無効なパラメーターなど、要求に問題がある場合、メソッドは例外をスローします。
先ほど追加した CreateOrUpdateDataSource 関数を呼び出す行を Main に追加します。
// Create or Update the data source
Console.WriteLine("Creating or updating the data source...");
SearchIndexerDataSourceConnection dataSource = CreateOrUpdateDataSource(indexerClient, configuration);
ソリューションをビルドして実行します。 これは最初の要求のため、Azure portal を調べて、データ ソースが Azure AI Search で作成されたことを確認します。 検索サービスの概要ページで、[データ ソース] の一覧に新しい項目があることを確認します。 Portal のページが更新されるまで数分かかる場合があります。
![ポータルの [データ ソース] タイル](media/cognitive-search-tutorial-blob/data-source-tile.png "ポータルの [データ ソース] タイル")
手順 2:スキルセットを作成する
このセクションでは、データに適用するエンリッチメント ステップのセットを定義します。 各エンリッチメント ステップは "スキル" と呼ばれ、エンリッチメント ステップのセットは "スキルセット" と呼ばれます。 このチュートリアルでは、スキルセット用に次のビルトイン スキルを使用します。
光学式文字認識。画像ファイルに印字された手書きテキストを認識します。
テキスト マージャー。フィールドのコレクションからのテキストを、1 つの "マージされたコンテンツ" フィールドに統合します。
言語検出。コンテンツの言語を識別します。
エンティティの認識。BLOB コンテナーのコンテンツから組織の名前を抽出します。
テキスト分割。キー フレーズ抽出スキルとエンティティ認識スキルを呼び出す前に、大きいコンテンツを小さいチャンクに分割します。 キー フレーズ抽出およびエンティティ認識では、50,000 字以内の入力を受け取ります。 いくつかのサンプル ファイルは、分割してこの制限内に収める必要があります。
キー フレーズ抽出。上位のキー フレーズを抜き出します。
初期処理中、Azure AI Search によって各ドキュメントが解析され、さまざまなファイル形式からコンテンツが抽出されます。 ソース ファイルで発生するテキストは、ドキュメントごとに 1 つずつ、生成された content フィールドに配置されます。 そのため、"/document/content" として入力を設定し、このテキストを使用します。 画像コンテンツは、スキルセットで /document/normalized_images/* として指定された、生成された normalized_images フィールドに配置されます。
出力はインデックスにマップすることができ、ダウンストリーム スキルへの入力として、または言語コードと同様に両方として使用されます。 インデックスでは、言語コードはフィルター処理に役立ちます。 入力としての言語コードは、テキスト分析スキルによって、単語区切りに基づく言語学的規則を通知するために使用されます。
スキルセットの基礎の詳細については、スキルセットを定義する方法に関するページをご覧ください。
OCR スキル
OcrSkill は画像からテキストを抽出します。 このスキルは、normalized-images フィールドが存在していることを前提としています。 このフィールドを生成するために、このチュートリアルの後半で、"generateNormalizedImages" に対するインデクサー定義で "imageAction" 構成を設定します。
private static OcrSkill CreateOcrSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("image")
{
Source = "/document/normalized_images/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("text")
{
TargetName = "text"
});
OcrSkill ocrSkill = new OcrSkill(inputMappings, outputMappings)
{
Description = "Extract text (plain and structured) from image",
Context = "/document/normalized_images/*",
DefaultLanguageCode = OcrSkillLanguage.En,
ShouldDetectOrientation = true
};
return ocrSkill;
}
マージ スキル
このセクションでは、ドキュメント コンテンツ フィールドを、OCR スキルで生成されたテキストとマージする MergeSkill を作成します。
private static MergeSkill CreateMergeSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/content"
});
inputMappings.Add(new InputFieldMappingEntry("itemsToInsert")
{
Source = "/document/normalized_images/*/text"
});
inputMappings.Add(new InputFieldMappingEntry("offsets")
{
Source = "/document/normalized_images/*/contentOffset"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("mergedText")
{
TargetName = "merged_text"
});
MergeSkill mergeSkill = new MergeSkill(inputMappings, outputMappings)
{
Description = "Create merged_text which includes all the textual representation of each image inserted at the right location in the content field.",
Context = "/document",
InsertPreTag = " ",
InsertPostTag = " "
};
return mergeSkill;
}
言語検出スキル
LanguageDetectionSkill は、入力テキストの言語を検出し、要求で送信されたドキュメントごとに 1 つの言語コードを報告します。 言語検出スキルの出力を、テキスト分割スキルに対する入力の一部として使用します。
private static LanguageDetectionSkill CreateLanguageDetectionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("languageCode")
{
TargetName = "languageCode"
});
LanguageDetectionSkill languageDetectionSkill = new LanguageDetectionSkill(inputMappings, outputMappings)
{
Description = "Detect the language used in the document",
Context = "/document"
};
return languageDetectionSkill;
}
テキスト分割スキル
下記の SplitSkill は、ページごとにテキストを分割し、String.Length で測定してページ サイズを 4,000 文字に制限します。 このアルゴリズムは、テキストを最大でサイズが maximumPageLength のチャンクに分割しようとします。 この場合、アルゴリズムはできる限り文の境界で文を区切ろうとするため、チャンクのサイズは maximumPageLength よりも少し小さくなることがあります。
private static SplitSkill CreateSplitSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/merged_text"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("textItems")
{
TargetName = "pages",
});
SplitSkill splitSkill = new SplitSkill(inputMappings, outputMappings)
{
Description = "Split content into pages",
Context = "/document",
TextSplitMode = TextSplitMode.Pages,
MaximumPageLength = 4000,
DefaultLanguageCode = SplitSkillLanguage.En
};
return splitSkill;
}
エンティティ認識スキル
この EntityRecognitionSkill インスタンスは、カテゴリの種類 organization を認識するように設定されています。 EntityRecognitionSkill は、カテゴリの種類 person と location も認識できます。
"context" フィールドが、アスタリスク付きで "/document/pages/*" に設定されていることに注目してください。これは、エンリッチメント ステップが "/document/pages" の下にある各ページごとに呼び出されることを意味します。
private static EntityRecognitionSkill CreateEntityRecognitionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("organizations")
{
TargetName = "organizations"
});
EntityRecognitionSkill entityRecognitionSkill = new EntityRecognitionSkill(inputMappings, outputMappings)
{
Description = "Recognize organizations",
Context = "/document/pages/*",
DefaultLanguageCode = EntityRecognitionSkillLanguage.En
};
entityRecognitionSkill.Categories.Add(EntityCategory.Organization);
return entityRecognitionSkill;
}
キー フレーズ抽出スキル
先ほど作成した EntityRecognitionSkill インスタンスと同様に、KeyPhraseExtractionSkill もドキュメントのページごとに呼び出されます。
private static KeyPhraseExtractionSkill CreateKeyPhraseExtractionSkill()
{
List<InputFieldMappingEntry> inputMappings = new List<InputFieldMappingEntry>();
inputMappings.Add(new InputFieldMappingEntry("text")
{
Source = "/document/pages/*"
});
inputMappings.Add(new InputFieldMappingEntry("languageCode")
{
Source = "/document/languageCode"
});
List<OutputFieldMappingEntry> outputMappings = new List<OutputFieldMappingEntry>();
outputMappings.Add(new OutputFieldMappingEntry("keyPhrases")
{
TargetName = "keyPhrases"
});
KeyPhraseExtractionSkill keyPhraseExtractionSkill = new KeyPhraseExtractionSkill(inputMappings, outputMappings)
{
Description = "Extract the key phrases",
Context = "/document/pages/*",
DefaultLanguageCode = KeyPhraseExtractionSkillLanguage.En
};
return keyPhraseExtractionSkill;
}
スキルセットを構築および作成する
作成したスキルを使用して SearchIndexerSkillset を構築します。
private static SearchIndexerSkillset CreateOrUpdateDemoSkillSet(SearchIndexerClient indexerClient, IList<SearchIndexerSkill> skills,string azureAiServicesKey)
{
SearchIndexerSkillset skillset = new SearchIndexerSkillset("demoskillset", skills)
{
// Azure AI services was formerly known as Cognitive Services.
// The APIs still use the old name, so we need to create a CognitiveServicesAccountKey object.
Description = "Demo skillset",
CognitiveServicesAccount = new CognitiveServicesAccountKey(azureAiServicesKey)
};
// Create the skillset in your search service.
// The skillset does not need to be deleted if it was already created
// since we are using the CreateOrUpdate method
try
{
indexerClient.CreateOrUpdateSkillset(skillset);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the skillset\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without a skillset");
}
return skillset;
}
次の行を Main に追加します。
// Create the skills
Console.WriteLine("Creating the skills...");
OcrSkill ocrSkill = CreateOcrSkill();
MergeSkill mergeSkill = CreateMergeSkill();
EntityRecognitionSkill entityRecognitionSkill = CreateEntityRecognitionSkill();
LanguageDetectionSkill languageDetectionSkill = CreateLanguageDetectionSkill();
SplitSkill splitSkill = CreateSplitSkill();
KeyPhraseExtractionSkill keyPhraseExtractionSkill = CreateKeyPhraseExtractionSkill();
// Create the skillset
Console.WriteLine("Creating or updating the skillset...");
List<SearchIndexerSkill> skills = new List<SearchIndexerSkill>();
skills.Add(ocrSkill);
skills.Add(mergeSkill);
skills.Add(languageDetectionSkill);
skills.Add(splitSkill);
skills.Add(entityRecognitionSkill);
skills.Add(keyPhraseExtractionSkill);
SearchIndexerSkillset skillset = CreateOrUpdateDemoSkillSet(indexerClient, skills, azureAiServicesKey);
手順 3:インデックスを作成する
このセクションでは、検索可能なインデックス、および各フィールドの検索属性に含めるフィールドを指定することによって、インデックス スキーマを定義します。 フィールドには型があり、フィールドの使用方法 (検索可能、並べ替え可能など) を決定する属性を取ることができます。 インデックス内のフィールド名は、ソース内のフィールド名と完全に一致する必要はありません。 後のほうの手順では、インデクサーにフィールド マッピングを追加して、ソースとターゲットのフィールドを接続します。 この手順で、検索アプリケーションに関連するフィールドの名前付け規則を使用してインデックスを定義します。
この演習では、次のフィールドとフィールドの型を使用します。
| フィールド名 | フィールドの型 |
|---|---|
id |
Edm.String |
content |
Edm.String |
languageCode |
Edm.String |
keyPhrases |
List<Edm.String> |
organizations |
List<Edm.String> |
DemoIndex クラスを作成する
このインデックスのフィールドはモデル クラスを使用して定義されます。 モデル クラスの各プロパティには、対応するインデックス フィールドの検索に関連した動作を決定する属性があります。
モデル クラスを新しい C# ファイルに追加します。 プロジェクトを右クリックして [追加]>[新しい項目...] を選択し、[クラス] を選択し、ファイルに DemoIndex.cs という名前を付けて、[追加] を選択します。
Azure.Search.Documents.Indexes および System.Text.Json.Serialization 名前空間の種類を使用することを指定します。
以下のモデル クラス定義を DemoIndex.cs に追加し、インデックスを作成するのと同じ名前空間に含めます。
using Azure.Search.Documents.Indexes;
using System.Text.Json.Serialization;
namespace EnrichwithAI
{
// The SerializePropertyNamesAsCamelCase is currently unsupported as of this writing.
// Replace it with JsonPropertyName
public class DemoIndex
{
[SearchableField(IsSortable = true, IsKey = true)]
[JsonPropertyName("id")]
public string Id { get; set; }
[SearchableField]
[JsonPropertyName("content")]
public string Content { get; set; }
[SearchableField]
[JsonPropertyName("languageCode")]
public string LanguageCode { get; set; }
[SearchableField]
[JsonPropertyName("keyPhrases")]
public string[] KeyPhrases { get; set; }
[SearchableField]
[JsonPropertyName("organizations")]
public string[] Organizations { get; set; }
}
}
モデル クラスの定義が完了したので、Program.csに戻ると、インデックス定義を非常に簡単に作成できます。 このインデックスの名前は demoindex になります。 その名前のインデックスが既に存在する場合、そのインデックスは削除されます。
private static SearchIndex CreateDemoIndex(SearchIndexClient indexClient)
{
FieldBuilder builder = new FieldBuilder();
var index = new SearchIndex("demoindex")
{
Fields = builder.Build(typeof(DemoIndex))
};
try
{
indexClient.GetIndex(index.Name);
indexClient.DeleteIndex(index.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified index not exist, 404 will be thrown.
}
try
{
indexClient.CreateIndex(index);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the index\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without an index");
}
return index;
}
テスト中に、インデックスの作成を複数回試みていることがわかります。 このため、作成を試行する前に、作成しようとするインデックスが既に存在していないかを確認してください。
次の行を Main に追加します。
// Create the index
Console.WriteLine("Creating the index...");
SearchIndex demoIndex = CreateDemoIndex(indexClient);
参照のあいまいさを解消するために、次の using ステートメントを追加します。
using Index = Azure.Search.Documents.Indexes.Models;
インデックスの概念の詳細については、インデックスの作成 (REST API) に関するページを参照してください。
手順 4:インデクサーの作成と実行
ここまでで、データ ソース、スキルセット、およびインデックスを作成しました。 これら 3 つのコンポーネントが、各要素を複数フェーズにわたる 1 つの操作にまとめて入れるインデクサーの一部になります。 これらをまとめてインデクサーに結び付けるには、フィールド マッピングを定義する必要があります。
スキルセットの前に fieldMappings が処理されて、データ ソースのソース フィールドがインデックス内のターゲット フィールドにマッピングされます。 フィールド名と型が両側で共通していれば、マッピングは必要ありません。
outputFieldMappings は、スキルセットの後に処理されます。sourceFieldNames がドキュメント解析またはエンリッチメントによって作成されるまでは、存在しない sourceFieldNames が参照されます。 targetFieldName は、インデックス内のフィールドです。
入力を出力につなぐことに加え、フィールドのマッピングを使用して、データ構造をフラット化することもできます。 詳細については、「強化されたフィールドを検索可能なインデックスにマップする方法」を参照してください。
private static SearchIndexer CreateDemoIndexer(SearchIndexerClient indexerClient, SearchIndexerDataSourceConnection dataSource, SearchIndexerSkillset skillSet, SearchIndex index)
{
IndexingParameters indexingParameters = new IndexingParameters()
{
MaxFailedItems = -1,
MaxFailedItemsPerBatch = -1,
};
indexingParameters.Configuration.Add("dataToExtract", "contentAndMetadata");
indexingParameters.Configuration.Add("imageAction", "generateNormalizedImages");
SearchIndexer indexer = new SearchIndexer("demoindexer", dataSource.Name, index.Name)
{
Description = "Demo Indexer",
SkillsetName = skillSet.Name,
Parameters = indexingParameters
};
FieldMappingFunction mappingFunction = new FieldMappingFunction("base64Encode");
mappingFunction.Parameters.Add("useHttpServerUtilityUrlTokenEncode", true);
indexer.FieldMappings.Add(new FieldMapping("metadata_storage_path")
{
TargetFieldName = "id",
MappingFunction = mappingFunction
});
indexer.FieldMappings.Add(new FieldMapping("content")
{
TargetFieldName = "content"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/organizations/*")
{
TargetFieldName = "organizations"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/pages/*/keyPhrases/*")
{
TargetFieldName = "keyPhrases"
});
indexer.OutputFieldMappings.Add(new FieldMapping("/document/languageCode")
{
TargetFieldName = "languageCode"
});
try
{
indexerClient.GetIndexer(indexer.Name);
indexerClient.DeleteIndexer(indexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
//if the specified indexer not exist, 404 will be thrown.
}
try
{
indexerClient.CreateIndexer(indexer);
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to create the indexer\n Exception message: {0}\n", ex.Message);
ExitProgram("Cannot continue without creating an indexer");
}
return indexer;
}
次の行を Main に追加します。
// Create the indexer, map fields, and execute transformations
Console.WriteLine("Creating the indexer and executing the pipeline...");
SearchIndexer demoIndexer = CreateDemoIndexer(indexerClient, dataSource, skillset, demoIndex);
インデクサーの処理が完了するまでに時間がかかることが予想されます。 データ セットが小さい場合でも、分析スキルは計算を集中的に行います。 画像分析などの一部のスキルは、実行時間の長いスキルです。
ヒント
インデクサーを作成すると、パイプラインが呼び出されます。 データ、入力と出力のマッピング、または操作の順序に及ぶ問題がある場合は、この段階で現れます。
インデクサーの作成について
コードで "maxFailedItems" を -1 に設定します。これにより、インデックス作成エンジンに、データのインポート中のエラーを無視するよう指示します。 デモのデータ ソースにはドキュメントがほとんどないため、これは便利です。 大きいデータ ソースの場合は、この値を 0 より大きい値に設定します。
また、"dataToExtract" が "contentAndMetadata" に設定されていることに気が付きます。 このステートメントは、さまざまなファイル形式と、各ファイルに関連するメタデータからコンテンツを、自動的に抽出するようにインデクサーに指示します。
コンテンツが抽出されるときに、imageAction を設定して、データ ソース内にある画像からテキストを抽出することができます。 "generateNormalizedImages" 構成に設定された "imageAction" は、OCR スキルおよびテキスト マージ スキルと組み合わされて、イメージからテキスト (たとえば、一時停止の道路標識から "stop" という単語) を抽出し、それをコンテンツ フィールドの一部として埋め込むよう、インデクサーに指示します。 この動作は、ドキュメントに埋め込まれているイメージ (PDF 内のイメージを考えてください) と、データ ソース内にあるイメージ (たとえば、JPG ファイル) の両方に適用されます。
インデックス作成の監視
インデクサーを定義すると、要求を送信するときに自動的に実行されます。 定義したスキルによっては、インデックス作成に予想よりも時間がかかる場合があります。 インデクサーがまだ実行中かどうかを確認するには、GetStatus メソッドを使用します。
private static void CheckIndexerOverallStatus(SearchIndexerClient indexerClient, SearchIndexer indexer)
{
try
{
var demoIndexerExecutionInfo = indexerClient.GetIndexerStatus(indexer.Name);
switch (demoIndexerExecutionInfo.Value.Status)
{
case IndexerStatus.Error:
ExitProgram("Indexer has error status. Check the Azure Portal to further understand the error.");
break;
case IndexerStatus.Running:
Console.WriteLine("Indexer is running");
break;
case IndexerStatus.Unknown:
Console.WriteLine("Indexer status is unknown");
break;
default:
Console.WriteLine("No indexer information");
break;
}
}
catch (RequestFailedException ex)
{
Console.WriteLine("Failed to get indexer overall status\n Exception message: {0}\n", ex.Message);
}
}
demoIndexerExecutionInfo は、インデクサーの現在の状態と実行履歴を表します。
警告は、一部のソース ファイルとスキルの組み合わせではよく見られ、必ずしも問題を示すわけではありません。 このチュートリアルでは、警告は無害です (たとえば、JPEG ファイルからのテキスト入力がない)。
次の行を Main に追加します。
// Check indexer overall status
Console.WriteLine("Check the indexer overall status...");
CheckIndexerOverallStatus(indexerClient, demoIndexer);
検索する
Azure AI Search チュートリアルのコンソール アプリでは、通常、結果を返すクエリを実行する前に 2 秒の遅延が追加されますが、エンリッチメントの完了には数分かかるため、ここではコンソール アプリを終了し、代わりに別の方法を使用します。
最も簡単なオプションは、ポータルの Search エクスプローラーです。 最初に、すべてのドキュメントを返す空のクエリを実行することも、パイプラインによって作成された新しいフィールド コンテンツを返す、より絞り込んだ検索を実行することもできます。
Azure portal の検索の概要ページで、 [インデックス] を選択します。
一覧で
demoindexを見つけます。 14 個のドキュメントが含まれています。 ドキュメントの数が 0 の場合は、インデクサーが実行中のままであるか、ページがまだ更新されていません。[
demoindex] を選択します。 Search エクスプローラーは最初のタブです。最初のドキュメントが読み込まれるとすぐに、コンテンツは検索可能になります。 コンテンツが存在することを確認するには、 [検索] をクリックして、クエリを指定せずに実行します。 このクエリにより、現在インデックスが作成されているすべてのドキュメントが返され、インデックスの内容がわかります。
次に、結果を管理しやすくするために、次の文字列を貼り付けます:
search=*&$select=id, languageCode, organizations
リセットして再実行する
開発の初期の実験的な段階では、設計反復のための最も実用的なアプローチは、Azure AI Search からオブジェクトを削除してリビルドできるようにすることです。 リソース名は一意です。 オブジェクトを削除すると、同じ名前を使用して再作成することができます。
このチュートリアルのサンプル コードでは、コードを再実行できるよう、既存のオブジェクトをチェックしてそれらを削除しています。 ポータルを使用して、インデックス、インデクサー、データ ソース、スキルセットを削除することもできます。
重要なポイント
このチュートリアルでは、構成要素 (データ ソース、スキルセット、インデックス、およびインデクサー) の作成によってエンリッチされたインデックス作成パイプラインを作成するための、基本的な手順を示しました。
組み込みのスキルについては、スキルセットの定義と、入力と出力を介したスキルの連結のしくみと共に説明しました。 また、Azure AI Search サービスでエンリッチされた値をパイプラインから検索可能なインデックス内にルーティングするには、インデクサーの定義に outputFieldMappings が必要であることも学習しました。
最後に、結果をテストし、今後の反復のためにシステムをリセットする方法について学習しました。 インデックスに対するクエリを発行すると、エンリッチされたインデックス作成パイプラインによって作成された出力が返されることを学習しました。 また、インデクサーの状態を確認する方法と、パイプラインを再実行する前に削除すべきオブジェクトについても学習しました。
リソースをクリーンアップする
所有するサブスクリプションを使用している場合は、プロジェクトの終了時に、不要になったリソースを削除することをお勧めします。 リソースを実行したままにすると、お金がかかる場合があります。 リソースは個別に削除することも、リソース グループを削除してリソースのセット全体を削除することもできます。
ポータルの左側のナビゲーション ウィンドウにある [すべてのリソース] または [リソース グループ] リンクを使って、リソースを検索および管理できます。
次のステップ
AI エンリッチメント パイプラインのオブジェクトをすべて理解したら、スキルセットの定義と個々のスキルについて詳しく見てみましょう。