Azure portal で Azure AI Search スキルセットをデバッグする
ポータル ベースのデバッグ セッションを開始して、エラーの特定と解決、変更の検証を行い、Azure AI 検索サービスの既存のスキルセットに変更をプッシュします。
デバッグ セッションは、キャッシュされたインデクサーとスキルセットの実行であり、1 つのドキュメントが対象になります。これを使用して、スキルセットの変更を対話的に編集およびテストできます。 デバッグが完了したら、スキルセットへの変更を保存できます。
デバッグ セッションのしくみの背景情報については、「Azure AI Search のデバッグ セッション」を参照してください。 サンプル ドキュメントを使ってデバッグ ワークフローを練習するには、「チュートリアル: デバッグ セッションを使用してスキルセットをデバッグする」を参照してください。
前提条件
Azure AI 検索サービス、任意のリージョンまたはレベル。
セッション状態の保存に使われる Azure Storage アカウント。
データ ソース、スキルセット、インデクサー、インデックスを含む、既存のエンリッチメント パイプライン。
セキュリティとアクセス許可
デバッグ セッションを Azure Storage に保存するには、Search Service ID に、Azure Storage に対するストレージ BLOB データ共同作成者のアクセス許可が必要です。 それ以外の場合は、Azure Storage へのデバッグ セッション接続にフル アクセス接続文字列を選択することを計画します。
Azure Storage アカウントがファイアウォールの内側にある場合は、検索サービスのアクセスを許可するようにそれを構成します。
制限事項
デバッグ セッションは、一般提供されているすべてのインデクサー データ ソースとほとんどのプレビュー データ ソースで機能しますが、次の例外があります。
SharePoint Online インデクサー。
Azure Cosmos DB for MongoDB インデクサー。
Azure Cosmos DB for NoSQL では、インデックス中に行が失敗し、対応するメタデータがない場合、デバッグ セッションで正しい行が選択されない可能性があります。
Azure Cosmos DB の SQL API の場合、パーティション分割されたコレクションが以前にパーティション分割されていなかった場合、デバッグ セッションではドキュメントが見つかりません。
カスタム スキルの場合、Azure Storage へのデバッグ セッション接続では、ユーザー割り当てマネージド ID はサポートされていません。 前提条件に記載されているように、システム マネージド ID を使用するか、キーを含むフル アクセス接続文字列を指定することができます。 詳細については、「マネージド ID を使用して他の Azure リソースに検索サービスを接続する」を参照してください。
デバッグ セッションを作成する
Azure portal にサインインし、ご利用の検索サービスを探します。
左側のメニューで、[検索管理]>[デバッグ セッション] を選択します。
上部のアクション バーで、[デバッグ セッションを追加] を選択します。

[デバッグセッション名] に、デバッグセッションに関連するスキルセット、インデクサー、およびデータソースを思い出すのに役立つ名前を入力します。
[Indexer template](インデクサー テンプレート) で、デバッグするスキルセットを駆動するインデクサーを選択します。 セッションを開始するために、インデクサーとスキルセットの両方のコピーが使われます。
[Document to debug](デバッグするドキュメント) で、インデックスの最初のドキュメントを選択するか、特定のドキュメントを選択します。 データ ソースに応じて特定のドキュメントを選択すると、URI または行 ID を指定するように求められます。
特定のドキュメントが BLOB の場合は、BLOB URI を指定します。 URI は、Azure portal の BLOB プロパティ ページで見つけることができます。
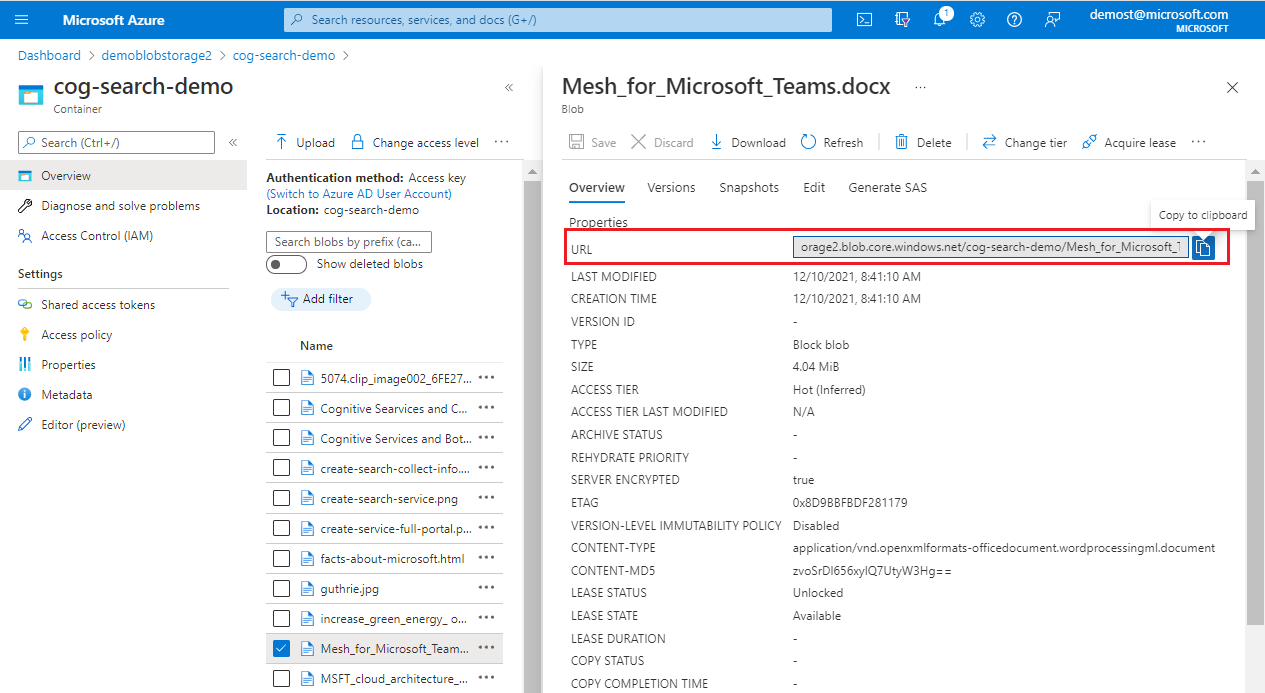
[ストレージ アカウント] で、デバッグ セッションをキャッシュするための汎用ストレージ アカウントを選択します。
以前に検索サービス システムのマネージド ID にストレージ BLOB データ共同作成者アクセス許可を割り当てた場合は、[マネージド ID を使用して認証する] を選択します。 このチェック ボックスをオンにしない場合、Search Service はフル アクセス接続文字列を使用して接続します。
[保存] を選択します。
- Azure AI Search は、ms-az-cognitive-search-debugsession という名前の BLOB コンテナーを Azure Storage に作成します。
- そのコンテナー内に、セッション名に指定した名前を使用してフォルダーが作成されます。
- デバッグ セッションが開始されます。


デバッグ セッションは、選んだドキュメントに対してインデクサーとスキルセットを実行することから始まります。 ドキュメントのコンテンツとメタデータは、セッション内で表示、使用できるようになります。
デバッグ セッションは、実行中に取り消すことができます。 [キャンセル] ボタンをクリックすると、結果の一部を分析できるようになります。
デバッグ セッションは、追加の処理を通過するため、インデクサーよりも実行に時間がかかることが予想されます。
エラーと警告から始める
Azure portal のインデクサーの実行履歴では、すべてのドキュメントに関するすべてのエラーと警告の一覧を確認できます。 デバッグ セッションでは、エラーと警告は 1 つのドキュメントに限定されます。 このリストを参照して変更を加えたら、リストに戻って問題が解決したかどうかを確認します。
デバッグ セッションは、インデックス全体の 1 つのドキュメントに基づいていることに注意してください。 入力または出力が誤っていると思われる場合、問題はそのドキュメントに固有のものである可能性があります。 別のドキュメントを選択すると、エラーと警告が 1 つのドキュメントにわたるものであるか、あるドキュメントに固有であるかを確認できます。
問題の一覧を確認するには、[エラー] または [警告] を選択します。
![ページの上部にある [エラー] ボタンと [警告] ボタンのスクリーンショット。](media/cognitive-search-debug/debug-session-errors-warnings.png#lightbox)
ベスト プラクティスとして、出力に移る前に入力に関する問題を解決してください。
変更によってエラーが解決したかどうかを確認するには、次の手順を実行します。
[スキルの詳細] ウィンドウの [保存] を選び、変更内容を保存します。
セッション ウィンドウで [実行] を選び、変更した定義を使ってスキルセットの実行を呼び出します。
[エラー] または [警告] に戻り、数が減ったかどうかを確認します。
エンリッチされたコンテンツまたは生成されたコンテンツを確認する
AI エンリッチメント パイプラインを使うと、ソース ドキュメントから情報と構造を抽出または推論し、そのプロセスでエンリッチ ド ドキュメントを作成することができます。 エンリッチされたドキュメントは、まずドキュメント解析時に作成され、ルート ノード (/document) に加えて、メタデータやドキュメント キーから直接解除されたデータ ソースなどのコンテンツのノードが設定されます。 その他のノードはスキルの実行時にスキルによって作成され、スキルの出力ごとにエンリッチメント ツリーに新しいノードが追加されます。
スキルセットが作成または使用するすべてのコンテンツは、式エバリュエーターに表示されます。 リンクをポイントすると、エンリッチされたドキュメント ツリー内の各入力値または出力値を表示できます。 各スキルの入力または出力を確認するには、次の手順を実行します。
デバッグ セッションで、青い矢印を展開すると状況に応じたの詳細が表示されます。 既定では、詳細はエンリッチメントされたドキュメント データ構造です。 ただし、スキルまたはマッピングを選択すると、そのオブジェクトに関する詳細が表示されます。
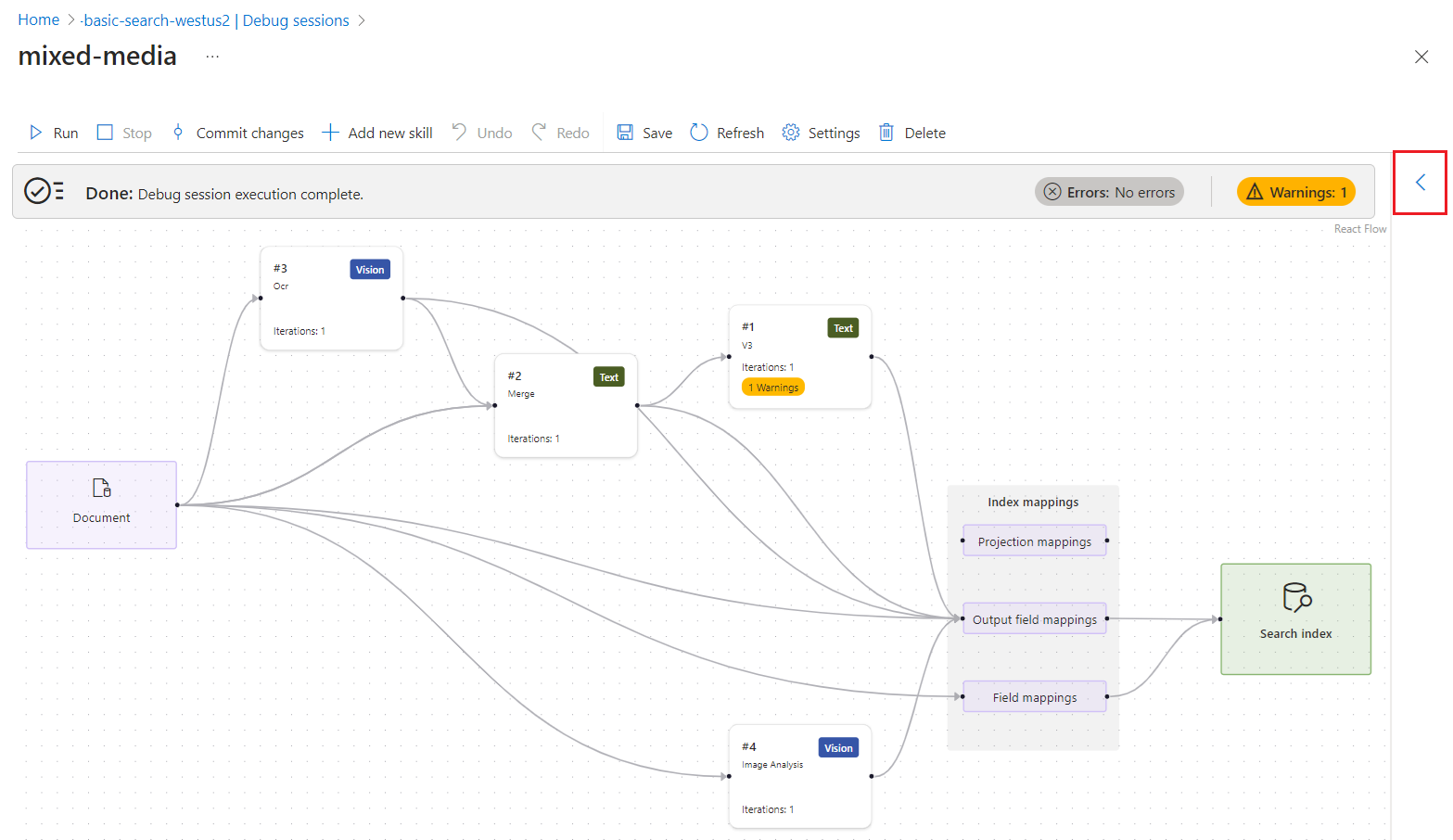
スキルを選びます。

スキル処理をさらに詳しく見るには、リンクをたどります。 たとえば、次のスクリーンショットは、テキスト分割スキルの最初のイテレーションの出力を示しています。




インデックス マッピングを確認する
スキルが出力を生成しても、検索インデックスが空の場合は、フィールドマッピングを確認します。 フィールドマッピングは、パイプラインから検索インデックスにコンテンツを移動する方法を指定します。

マッピング オプションのいずれかを選択し、詳細ビューを展開してソースとターゲットの定義を確認します。
プロジェクション マッピングは、データのインポートとベクトル化ウィザードで作成したスキルなど、垂直統合を行うスキルセットにあります。 これらのマッピングで、親子 (チャンク) フィールド マッピングと、チャンクされたコンテンツのみに対してセカンダリ インデックスが作成するかどうかを決定します。
出力フィールド マッピングはインデクサーにあり、スキルセットが組み込みまたはカスタム スキルを呼び出す際に使用します。 これらのマッピングを使用してエンリッチメント ツリー内のノードから検索インデックス内のフィールドへのデータ パスを設定します。 パスの詳細については、「エンリッチメント ノードパスの構文」を参照してください。
フィールド マッピングはインデクサー定義にあり、データ ソース内の生コンテンツとインデックス内のフィールドからのデータ パスを確立します。 フィールド マッピングを使用して、エンコードとデコードの手順も追加できます。
この例では、プロジェクション マッピングの詳細を示します。 JSON を編集すると、マッピングの問題を修正できます。
![[出力フィールドのマッピング] ノードと詳細のスクリーンショット。](media/cognitive-search-debug/debug-session-projection-mapping.png#lightbox)
スキル定義を編集する
フィールドのマッピングが正しい場合は、個々のスキルの構成とコンテンツを確認します。 スキルによる出力の生成に失敗する場合は、プロパティまたはパラメーターが不足している可能性があります。これは、エラーと検証メッセージで判断できます。
コンテキストや入力式が無効な場合など、他の問題は解決が難しいことがあります。エラーによって何が問題かはわかりますが、修正方法はわからないからです。 コンテキストと入力構文については、Azure AI Search スキルセットでのエンリッチメントの参照に関する記事を参照してください。 個々のメッセージについては、インデクサーの一般的なエラーと警告のトラブルシューティングに関するページを参照してください。
スキルに関する情報を取得するには、次の手順を実行します。
作業画面でスキルを選択します。 右側に [スキルの詳細] ウィンドウが開きます。
[スキル設定] でスキル定義を編集します。 JSON を直接編集できます。
エンリッチメント ツリーのノードを参照するためのパス構文を確認します。 最も一般的な入力パスの一部を次に示します。
- テキストのチャンクの場合は
/document/content。 このノードは、BLOB のコンテンツ プロパティから設定されます。 - テキスト マージ スキルを含むスキルセット内のテキストのチャンクの場合は
/document/merged_content。 - 画像から認識または推論されたテキストの場合は
/document/normalized_images/*。
- テキストのチャンクの場合は
カスタム スキルをローカルでデバッグする
カスタム スキルは、コードが外部で実行されるため、デバッグ セッションを使用してデバッグできません。このため、カスタム スキルは、デバッグが難しい場合があります。 このセクションでは、カスタム Web API スキルをローカルでデバッグする方法、デバッグ セッション、Visual Studio Code と ngrok または Tunnelmole について説明します。 この手法は、Azure Functions で実行されるカスタム スキルや、ローカルで実行される他の Web フレームワーク (FastAPI など) で動作します。
パブリック URL の取得
このセクションでは、カスタム スキルへのパブリック URL を取得するための 2 つの方法について説明します。
Tunnelmole を使用する
Tunnelmole は、トンネルを介してローカル コンピューターに要求を転送するパブリック URL を作成できるオープン ソースのトンネリング ツールです。
Tunnelmole をインストールします。
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: npm を使用してインストールします。 または、NodeJS がインストールされていない場合は、Windows 用プリコンパイル済み.exe ファイルをダウンロードし、PATH 内のどこかに配置します。
- npm:
次のコマンドを実行して、新しいトンネルを作成します。
tmole 7071応答は次のようになります。
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071前の例では、
https://m5hdpb-ip-49-183-170-144.tunnelmole.netはローカル コンピューター上のポート7071に転送されます。これは、Azure 関数が公開されている既定のポートです。
ngrok を使用する
ngrok は、トンネリングまたは転送 URL を作成できる一般的なクローズド ソースのクロスプラットフォーム アプリケーションであり、インターネット要求をローカル コンピューターに到達できるようにします。 ngrok を使用して、検索サービスのエンリッチメント パイプラインからの要求をご自分のコンピューターに転送し、ローカル デバッグを許可します。
ngrok をインストールします。
ターミナルを開き、ngrok 実行可能ファイルを含むフォルダーに移動します。
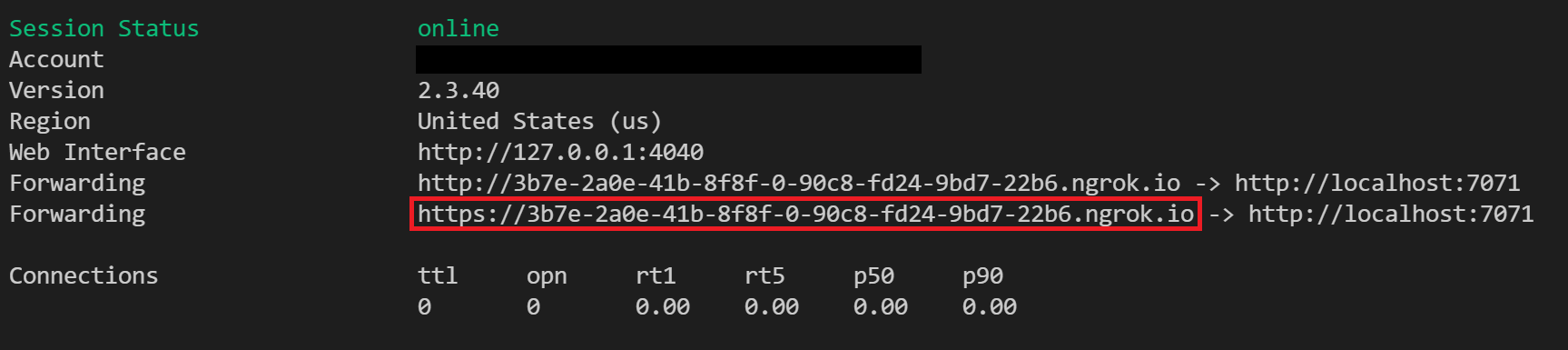
次のコマンドを使用して ngrok を実行して、新しいトンネルを作成します。
ngrok http 7071Note
既定では、Azure 関数は 7071 で公開されます。 その他のツールや構成では、別のポートを指定する必要がある場合があります。
ngrok が起動したら、次の手順のためにパブリック転送 URL をコピーして保存します。 転送 URL はランダムに生成されます。
Azure Portal での構成
カスタム スキルのパブリック URL を取得したら、デバッグ セッション内でカスタム Web API スキル URI を変更して Tunnelmole または ngrok 転送 URL を呼び出します。 Azure Function を使用してスキルセット コードを実行する場合は、"/api/FunctionName" を必ず追加してください。
スキル定義は、[スキルの詳細] ウィンドウの [スキル設定] セクションで編集できます。
コードのテスト
この時点で、デバッグ セッションからの新しい要求は、ローカルの Azure 関数に送信されるようになります。 Visual Studio Code のブレークポイントを使用して、コードをデバッグしたり、ステップバイステップで実行したりすることができます。
次のステップ
デバッグ セッション ビジュアル エディターのレイアウトと機能を理解したら、次はチュートリアルで実践してみましょう。