クイックスタート: Azure portal を使用してテキストと画像をベクトル化する
このクイックスタートは、Azure portal の [データのインポートとベクトル化] ウィザードを使って垂直統合を使い始めるのに役立ちます。 ウィザードでは、コンテンツをチャンクし、埋め込みモデルを呼び出して、インデックス作成中およびクエリ時にコンテンツをベクトル化します。
前提条件
Azure サブスクリプション。 無料で作成できます。
Azure AI と同じリージョン内にある Azure AI 検索サービス。 Basic レベル以上をお勧めします。
正常性プラン PDF サンプル ドキュメントでサポートされているデータ ソース。
ウィザードに関する知識。 詳細については、「Azure portal のデータのインポート ウィザード」を参照してください。
サポートされるデータ ソース
データのインポートとベクトル化ウィザードでは、さまざまな Azure データ ソースをサポートしていますが、このクイックスタートでは、ファイル全体を操作する以下のデータ ソースについてのみ手順を説明します。
Azure Storage (BLOB およびテーブル用)。 Azure Storage は標準パフォーマンス (汎用 v2) アカウントである必要があります。 アクセス層は、ホット、クール、コールドにすることができます。
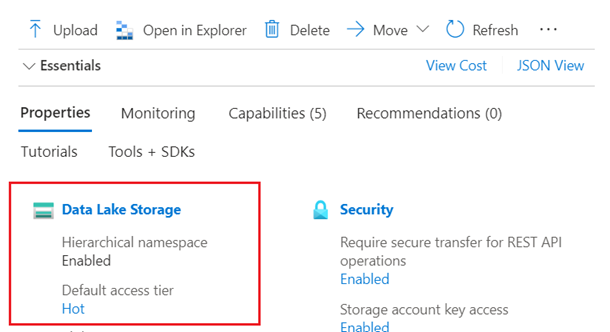
Azure Data Lake Storage (ADLS) Gen2 (階層型名前空間が有効になっている Azure ストレージ アカウント)。 [概要] ページの [プロパティ] タブを調べて、Data Lake Storage があることを確認できます。
サポートされている埋め込みモデル
Azure AI 検索と同じリージョン内にある Azure AI プラットフォーム上で埋め込みモデルを使用します。 デプロイの手順については、この記事で説明します。
| プロバイダー | サポートされているモデル |
|---|---|
| Azure OpenAI Service | text-embedding-ada-002 text-embedding-3-large text-embedding-3-small |
| Azure AI Foundry のモデル カタログ | テキストの場合: Cohere-embed-v3-english Cohere-embed-v3-multilingual 画像の場合: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
| Azure AI サービス マルチサービス アカウント | 選択したリージョンで利用可能な、画像とテキストのベクトル化のための Azure AI Vision マルチモーダル。 マルチサービス リソースをアタッチする方法によっては、マルチサービス アカウントを Azure AI 検索と同じリージョンにする必要が生じる場合があります。 |
Azure OpenAI Service を使用する場合は、エンドポイントに関連付けられたカスタム サブドメインが必要です。 カスタム サブドメインは、一意の名前 (たとえば、https://hereismyuniquename.cognitiveservices.azure.com) を含むエンドポイントです。 サービスが Azure portal を使用して作成された場合、このサブドメインはサービス セットアップの一部として自動的に生成されます。 Azure AI 検索統合で使用する前に、サービスにカスタム サブドメインが含まれていることを確認します。
Azure AI Foundry ポータルで作成された (埋め込みモデルにアクセスできる) Azure OpenAI Service リソースはサポートされていません。 Azure portal で作成された Azure OpenAI Service リソースのみが、Azure OpenAI 埋め込みスキル統合と互換性があります。
パブリック エンドポイントの要件
このクイックスタートでは、Azure portal ノードがアクセスできるように、上記のすべてのリソースでパブリック アクセスが有効になっている必要があります。 そうでないと、ウィザードは失敗します。 ウィザードの実行後、セキュリティのために統合コンポーネントでファイアウォールとプライベート エンドポイントを有効にすることができます。 詳細については、インポート ウィザードでの安全な接続に関するページを参照してください。
プライベート エンドポイントが既に存在しており、それらを無効にすることができない場合、代替手段は仮想マシン上でスクリプトまたはプログラムからそれぞれのエンドツーエンド フローを実行することです。 仮想マシンはプライベート エンドポイントと同じ仮想ネットワーク上にある必要があります。 垂直統合用の Python コード サンプルを次に示します。 同じ GitHub リポジトリ上に、他のプログラミング言語のサンプルも存在します。
アクセス許可
キー認証とフル アクセス接続文字列、または Microsoft Entra ID とロールの割り当てを使用できます。 他のリソースへの検索サービス接続には、ロールの割り当てを行うことをお勧めします。
Azure AI 検索で、ロールを有効にします。
マネージド ID を使用するように検索サービスを構成します。
データ ソース プラットフォームと埋め込みモデル プロバイダーで、検索サービスがデータとモデルにアクセスできるようにするロールの割り当てを作成します。 「サンプル データの準備」には、サポートされている各データ ソースにロールを設定するための手順を記載しています。
無料検索サービスは、Azure AI 検索へのロールベースの接続をサポートしていますが、Azure Storage または Azure AI Vision への送信接続でのマネージド ID はサポートしていません。 このレベルのサポートは、無料の検索サービスと他の Azure サービス間の接続でキーベースの認証を使用する必要があることを意味します。
セキュリティで保護された接続の場合:
- Basic レベル以上を使用する。
- マネージド ID を構成し、承認されたアクセスにロールを使用します。
Note
オプションが利用できないためにウィザードを進めることができない場合は (たとえば、データ ソースや埋め込みモデルを選択できない場合など)、ロールの割り当てを見直します。 エラー メッセージにはモデルまたはデプロイメントが存在しないことが示されますが、実際の原因は、検索サービスにそれらにアクセスするアクセス許可がないことです。
領域の確認
無料サービスで始める場合は、3 つのインデックス、データ ソース、スキルセット、インデクサーに制限されます。 基本では 15 個に制限されます。 十分な空き領域があることを確認してから開始してください。 このクイックスタートでは、各オブジェクトを 1 つずつ作成します。
サンプル データの準備
このセクションでは、このクイックスタートで使用するコンテンツについて説明します。
Azure アカウントを使用して Azure portal にサインインし、Azure Storage アカウントに移動します。
左側のペインの [データ ストレージ] で、[コンテナー] を選択します。
新しいコンテナーを作成し、このクイックスタートで使用する正常性プラン PDF ドキュメントをアップロードします。
左側のペインの [アクセスの制御] で、コンテナー上のストレージ BLOB データ閲覧者ロールを検索サービス ID に割り当てます。 または、[アクセス キー] ページからストレージ アカウントへの接続文字列を取得します。
必要に応じて、コンテナー内の削除と検索インデックスの削除を同期します。 次の手順では、削除検出用にインデクサーを構成できます。
ストレージ アカウントで論理的な削除を有効にします。
ネイティブの論理的な削除を使っている場合は、Azure Storage でさらに行う必要がある手順はありません。
そうでない場合は、削除対象としてマークされている BLOB を特定するためにインデクサーがスキャンできるカスタム メタデータを追加します。 カスタム プロパティにわかりやすい名前を付けます。 たとえば、プロパティに "IsDeleted" という名前を指定し、それを false に設定できます。 コンテナー内のすべての BLOB に対してこれを行います。 後で BLOB を削除するときは、このプロパティを true に変更します。 詳しくは、Azure Storage からインデックスを作成するときの変更と削除の検出に関する記事をご覧ください
埋め込みモデルを設定する
ウィザードでは、Azure OpenAI、Azure AI Vision、または Azure AI Foundry ポータルのモデル カタログにデプロイされた埋め込みモデルを使用できます。
ウィザードは、text-embedding-ada-002、text-embedding-3-large、text-embedding-3-small をサポートします。 内部的には、ウィザードは AzureOpenAIEmbedding スキルを呼び出して Azure OpenAI に接続します。
Azure アカウントを使用して Azure portal にサインインし、Azure OpenAI リソースに移動します。
アクセス許可を設定します。
左側のメニューで、[アクセスの制御] を選択します。
追加を選択し、ロール割り当ての追加を選択します。
[職務権限ロール] で、[Cognitive Services OpenAI ユーザー] を選択した後、[次へ] を選択します。
[メンバー] で、[マネージド ID] を選択した後、[メンバー] を選択します。
サブスクリプションとリソースの種類 (検索サービス) でフィルター処理を行った後、検索サービスのマネージド ID を選択します。
[レビューと割り当て] を選択します。
エンドポイントまたは API キーをコピーする必要がある場合は、[概要] ページで、[エンドポイントを表示するにはここをクリック] か [キーを管理するにはここをクリック] を選択します。 キーベースの認証で Azure OpenAI リソースを使用している場合は、これらの値をウィザードに貼り付けることができます。
[リソース管理] と [モデル デプロイ] で、[デプロイの管理] を選択して Azure AI Foundry を開きます。
text-embedding-ada-002またはサポートされている別の埋め込みモデルのデプロイ名をコピーします。 埋め込みモデルがない場合は、今すぐデプロイします。
ウィザードを起動する
Azure アカウントを使用して Azure portal にサインインし、Azure AI Search サービスに移動します。
[概要] ページで、[データのインポートとベクトル化] を選択します。

データへの接続
次の手順では、検索インデックスに使用するデータ ソースに接続します。
[データへの接続] で、[Azure Blob Storage] を選びます。
Azure サブスクリプションを指定します。
データを提供するストレージ アカウントとコンテナーを選択します。
削除の検出をサポートするかどうかを指定します。 その後のインデックス作成の実行では、検索インデックスが更新され、Azure Storage で論理的に削除された BLOB に基づく検索ドキュメントが削除されます。
- BLOB は、ネイティブ BLOB の論理的な削除またはカスタムデータを使用した論理的な削除のいずれかをサポートします。
- 以前に、Azure Storage で論理的な削除を有効にし、必要に応じて、インデックス作成で削除フラグとして認識できるカスタム メタデータ を追加してある必要があります。 これらの手順について詳しくは、「サンプル データの準備」をご覧ください。
- カスタム データを使用した論理的な削除用に BLOB を構成した場合は、このステップでメタデータ プロパティの名前と値の組を指定します。 "IsDeleted" をお勧めします。 BLOB で "IsDeleted" が true に設定されている場合、インデクサーは次の実行時に対応する検索ドキュメントを削除します。
ウィザードでは、Azure Storage での設定が有効かどうかはチェックされず、要件が満たされていない場合でもエラーはスローされません。 代わりに、削除の検出は機能せず、検索インデックスは時間と共に孤立したドキュメントを収集する可能性があります。
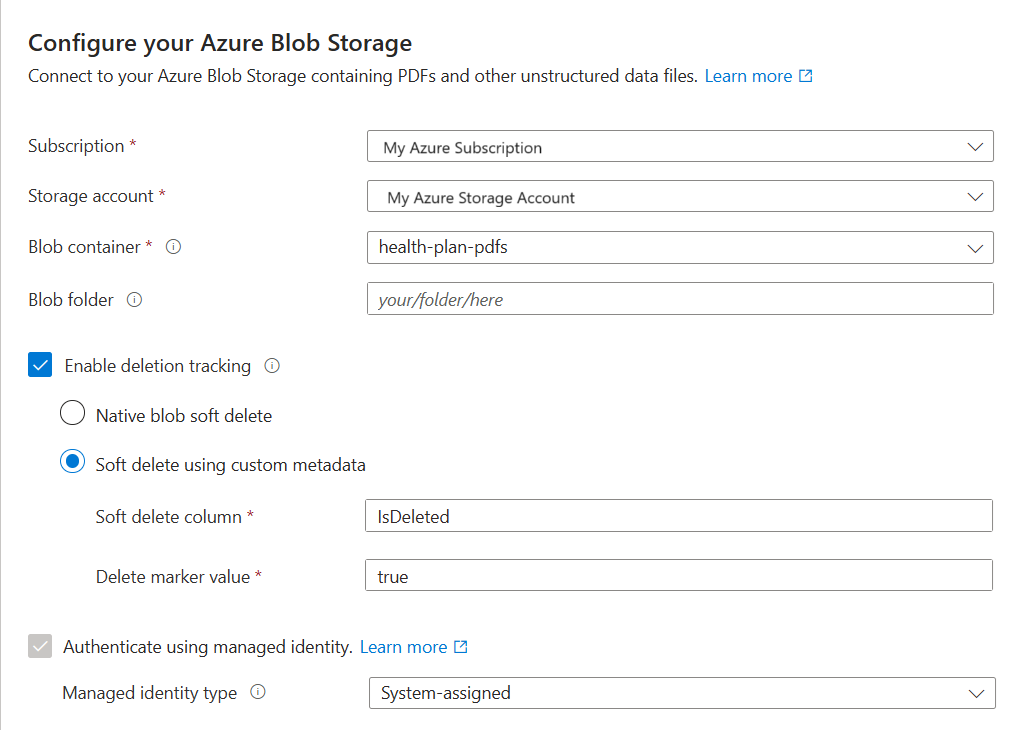
検索サービスをそのマネージド ID を使用して Azure Storage に接続するかどうかを指定します。
- システム マネージド ID またはユーザーマネージド ID を選択するよう求められます。
- この ID には、Azure Storage の [ストレージ BLOB データ閲覧者] ロールが必要です。
- この手順は省略しないでください。 ウィザードを Azure Storage に接続できない場合、インデックス作成中に接続エラーが発生します。
[次へ] を選択します。
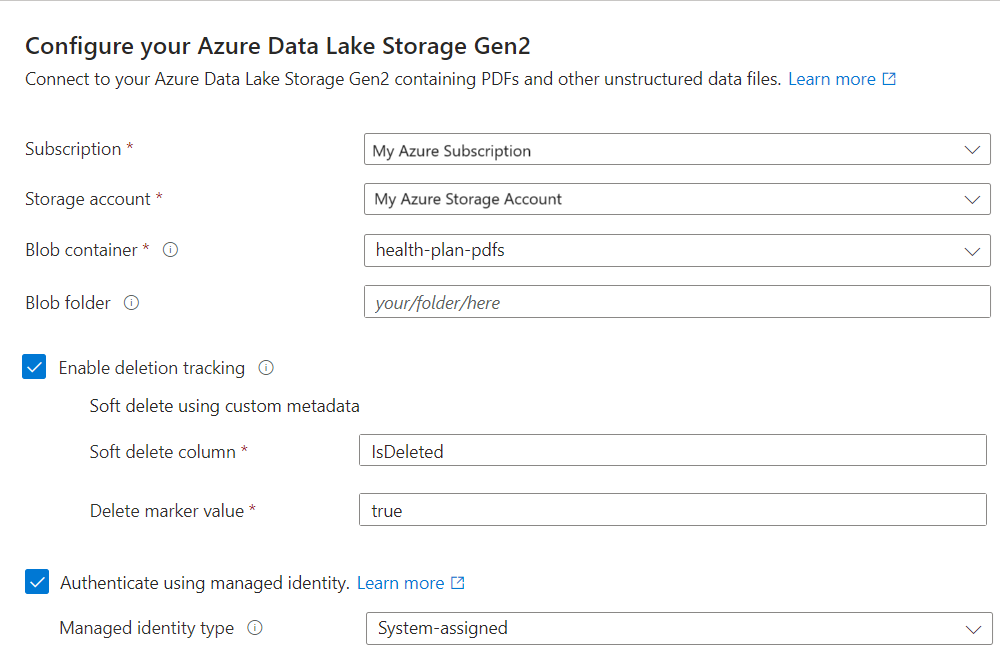
テキストをベクター化する
この手順では、チャンクされたデータをベクトル化するための埋め込みモデルを指定します。
チャンクは組み込みであり、構成はできません。 有効な設定は次のとおりです。
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
[テキストをベクター化する] ページで、埋め込みモデルのソースを選択します。
- Azure OpenAI
- Azure AI Foundry のモデル カタログ
- Azure AI Search と同じリージョンにある既存の Azure AI Vision マルチモーダル リソース。 同じリージョンに Azure AI サービス マルチサービス アカウントがない場合、このオプションは使用できません。
Azure サブスクリプションを選択します。
リソースに応じて以下のように選択を行います。
Azure OpenAI の場合は、text-embedding-ada-002、text-embedding-3-large、または text-embedding-3-small の既存のデプロイを選択します。
Azure AI Foundry カタログの場合は、Azure または Cohere 埋め込みモデルの既存のデプロイを選択します。
AI Vision マルチモーダル埋め込みの場合は、アカウントを選択します。
詳細については、この記事の前の方の「埋め込みモデルの設定」を参照してください。
検索サービスの認証に API キーを使用するか、マネージド ID を使用するかを指定します。
- ID は、Azure AI マルチサービス アカウントの Cognitive Services ユーザー ロールを持つ必要があります。
これらのリソースの使用による課金への影響を認めるチェックボックスを選択します。
[次へ] を選択します。
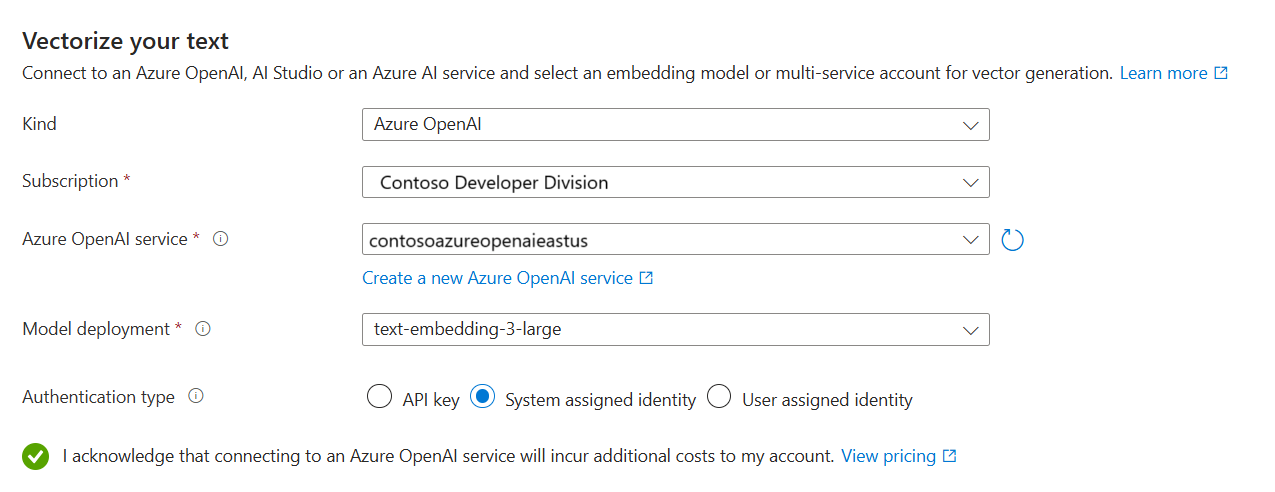
画像のベクトル化とエンリッチ
正常性プラン PDF には企業ロゴが含まれていますが、それ以外に画像はありません。 サンプル ドキュメントを使用している場合は、このステップをスキップできます。
ただし、有用な画像を含むコンテンツを扱う場合は、次の 2 つの方法で AI を適用できます。
カタログからサポートされている画像埋め込みモデルを使用するか、Azure AI Vision マルチモーダル埋め込み API を選んで画像をベクトル化します。
光学式文字認識 (OCR) を使用して、画像内のテキストを認識する。 このオプションは画像からテキストを読み取るための OCR スキルを呼び出します。
Azure AI 検索と Azure AI リソースは、同じリージョンに存在するか、キーレス課金接続用に構成されている必要があります。
[画像のベクトル化] ページで、ウィザードで作成する必要がある接続の種類を指定します。 画像のベクトル化では、ウィザードは Azure AI Foundry ポータルまたは Azure AI Vision 内の埋め込みモデルに接続できます。
サブスクリプションを指定します。
Azure AI Foundry モデル カタログの場合は、プロジェクトとデプロイを指定します。 詳細については、この記事の前の方の「埋め込みモデルの設定」を参照してください。
必要に応じて、バイナリ画像 (スキャンしたドキュメント ファイルなど) を使用したり、OCR を使用してテキストを認識したりできます。
これらのリソースの使用による課金への影響を認めるチェックボックスを選択します。
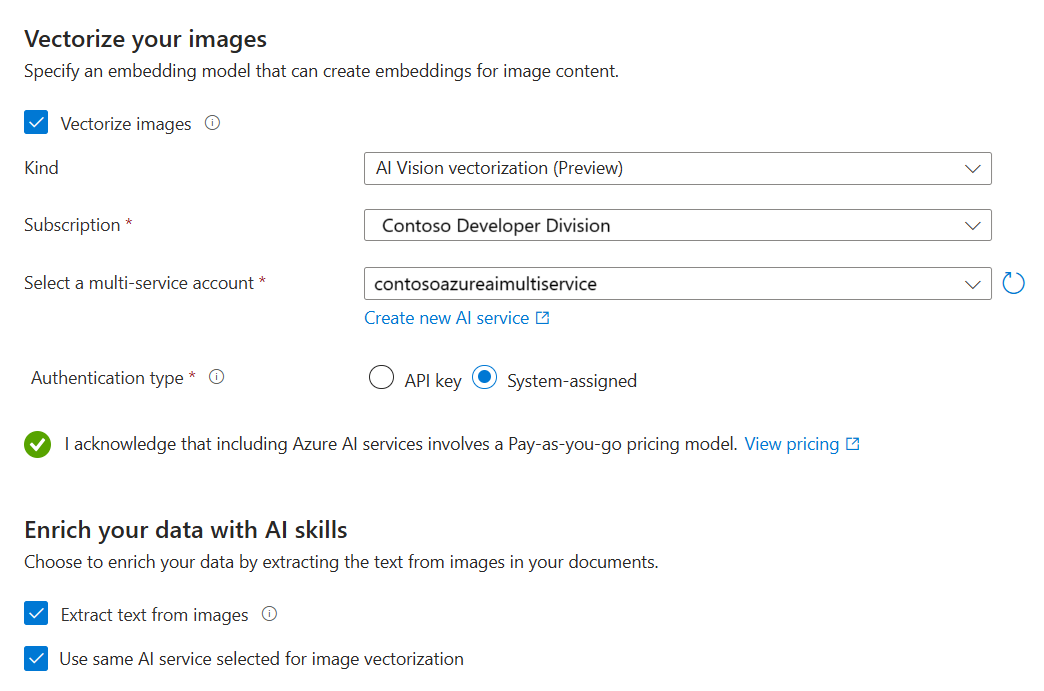
[次へ] を選択します。
セマンティック 優先度付けを追加する
[詳細設定] ページで、クエリ実行の終了時に結果を再ランク付けするためのセマンティック ランク付けをオプションで追加することができます。 再ランク付けによって、最も意味的な関連性が高いマッチが上位にきます。
新しいフィールドをマップする
この手順の重要なポイントは次のとおりです。
- インデックス スキーマは、チャンク データのベクトルおよび非ベクトル フィールドを提供します。
- フィールドを追加することはできますが、生成されたフィールドを削除または変更することはできません。
- ドキュメント解析モードでは、チャンク (チャンクごとに 1 つの検索ドキュメント) が作成されます。
[詳細設定] ページで、データ ソースがメタデータまたは最初のパスで取得されないフィールドを提供することを前提として、必要に応じて新しいフィールドを追加できます。 既定では、これらの属性を持つ次のフィールドがウィザードによって生成されます。
| フィールド | 適用対象 | 説明 |
|---|---|---|
| chunk_id | テキストと画像ベクトル | 生成された文字列フィールド。 検索可能、取得可能、並べ替え可能。 これはインデックスのドキュメント キーです。 |
| text_parent_id | テキスト ベクトル | 生成された文字列フィールド。 取得可能、フィルター可能。 チャンクの作成元である親ドキュメントを識別します。 |
| chunk | テキストと画像ベクトル | 文字列フィールド。 人間が判読できるバージョンのデータ チャンク。 検索可能で取得可能ですが、フィルター可能、ファセット可能、または並べ替え可能ではありません。 |
| タイトル | テキストと画像ベクトル | 文字列フィールド。 人間が判読できるドキュメント タイトルまたはページ タイトルまたはページ番号。 検索可能で取得可能ですが、フィルター可能、ファセット可能、または並べ替え可能ではありません。 |
| text_vector | テキスト ベクトル | Collection(Edm.single)。 チャンクのベクトル表現。 検索可能で取得可能ですが、フィルター可能、ファセット可能、または並べ替え可能ではありません。 |
生成されたフィールドやその属性は変更できませんが、データ ソースにある場合は、新しいフィールドを追加できます。 たとえば、Azure Blob Storage にはメタデータ フィールドのコレクションが用意されています。
[新規追加] を選択します。
使用可能なフィールドの一覧からソース フィールドを選択し、インデックスのフィールド名を指定し、既定のデータ型をそのまま使用するか、必要に応じてオーバーライドします。
メタデータ フィールドは検索可能ですが、取得可能、フィルター可能、ファセット可能、または並べ替え可能ではありません。
スキーマを元のバージョンに復元する場合は、[リセット] を選択します。
インデックス作成をスケジュールする
[詳細設定] ページで、必要に応じてインデクサーの [実行スケジュール] を指定できます。
- [詳細設定] ページが完了したら、[次へ] を選択します。
ウィザードを終了する
[構成の確認] ページで、ウィザードによって作成されるオブジェクトのプレフィックスを指定します。 共通のプレフィックスは、整理された状態を保つのに役立ちます。
[作成] を選択します
ウィザードによる構成が完了すると、以下のオブジェクトが作成されます。
データ ソース接続
ベクトル フィールド、ベクトライザー、ベクトル プロファイル、ベクトル アルゴリズムを含むインデックス。 ウィザードのワークフロー中に既定のインデックスを設計したり、変更したりすることはできません。 インデックスは 2024-05-01-preview REST API に適合しています。
チャンク用のテキスト分割スキルとベクトル化用の埋め込みスキルを含むスキルセット。 埋め込みスキルは、Azure OpenAI 用の AzureOpenAIEmbeddingModel スキルか、Azure AI Foundry モデル カタログ用の AML スキルのいずれかです。 スキルセットにはインデックス プロジェクションの構成もあり、データ ソースの 1 つのドキュメントから "子" インデックス内の対応するチャンクにデータをマップできます。
フィールド マッピングおよび出力フィールド マッピングを備えたインデクサー (該当する場合)。
結果をチェックする
検索エクスプローラーは、テキスト文字列を入力として受け取った後、ベクトル クエリの実行のためにテキストをベクトル化します。
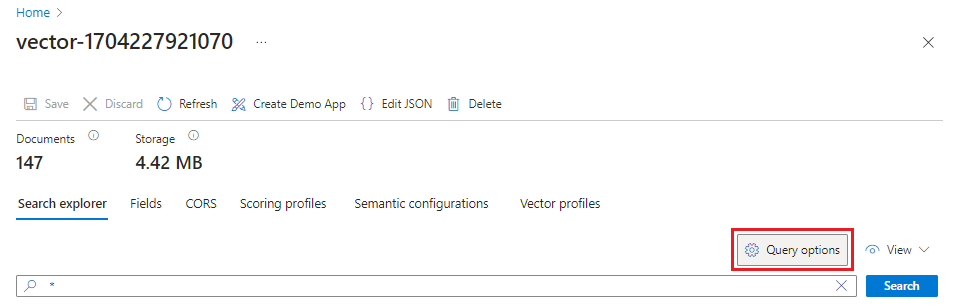
Azure portal で [検索管理]>[インデックス] に移動した後、作成したインデックスを選択します。
[クエリ オプション] を選び、検索結果のベクトル値を非表示にします。 この手順により、検索結果が読みやすくなります。
[ビュー] メニューで [JSON ビュー] を選択することで、
textベクトル クエリ パラメーターにベクトル クエリ用のテキストを入力できます。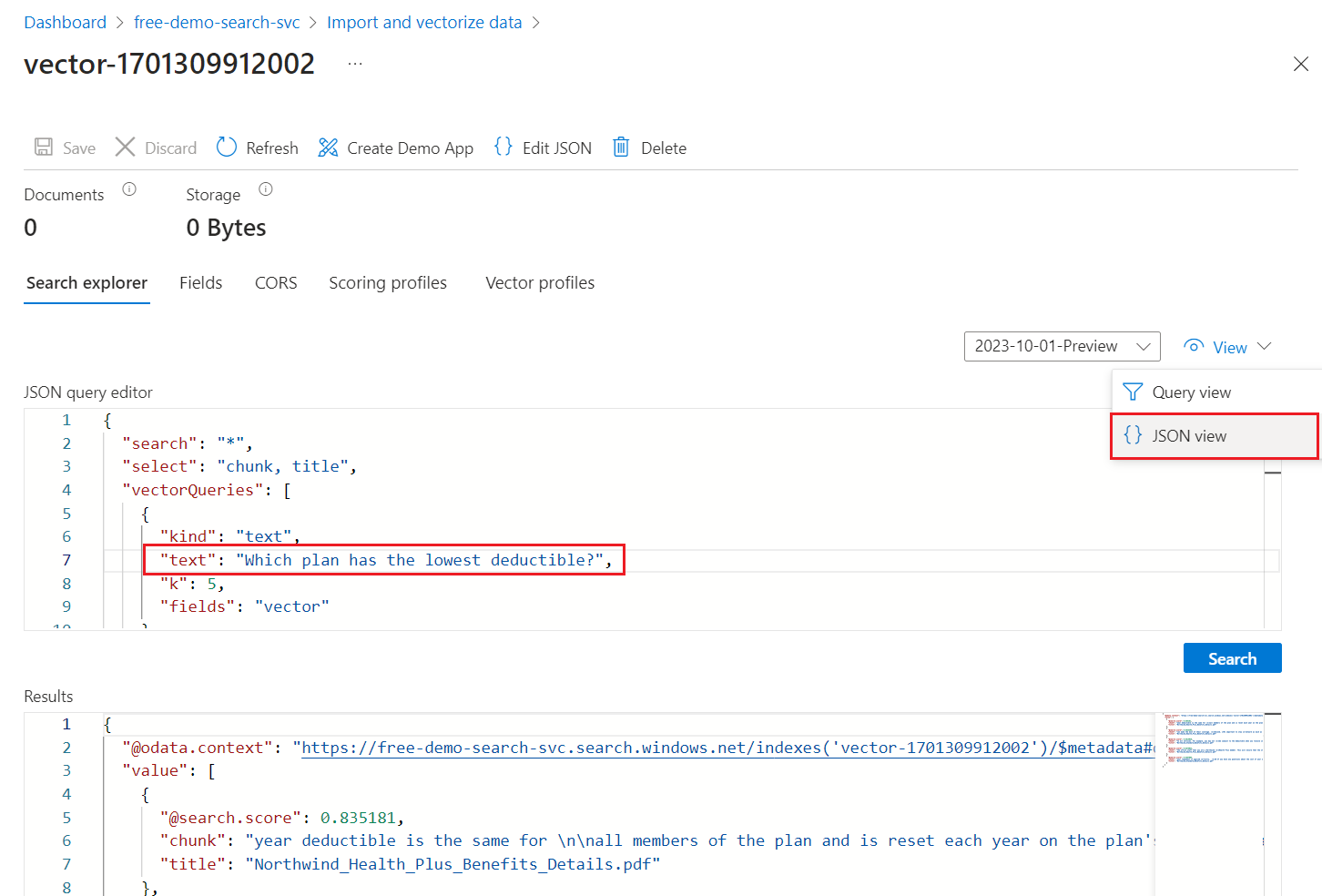
既定のクエリは空の検索 (
"*") ですが、一致する数を返すためのパラメーターが含まれています。 これは、テキスト クエリとベクトル クエリを並列で実行するハイブリッド クエリです。 セマンティック ランク付けが含まれます。selectステートメントを使用して結果に返すフィールドを指定します。{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }両方のアスタリスク (
*) プレースホルダーを、Which plan has the lowest deductible?などの正常性プランに関連する質問に置き換えます。{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }[検索] を選んでクエリを実行します。
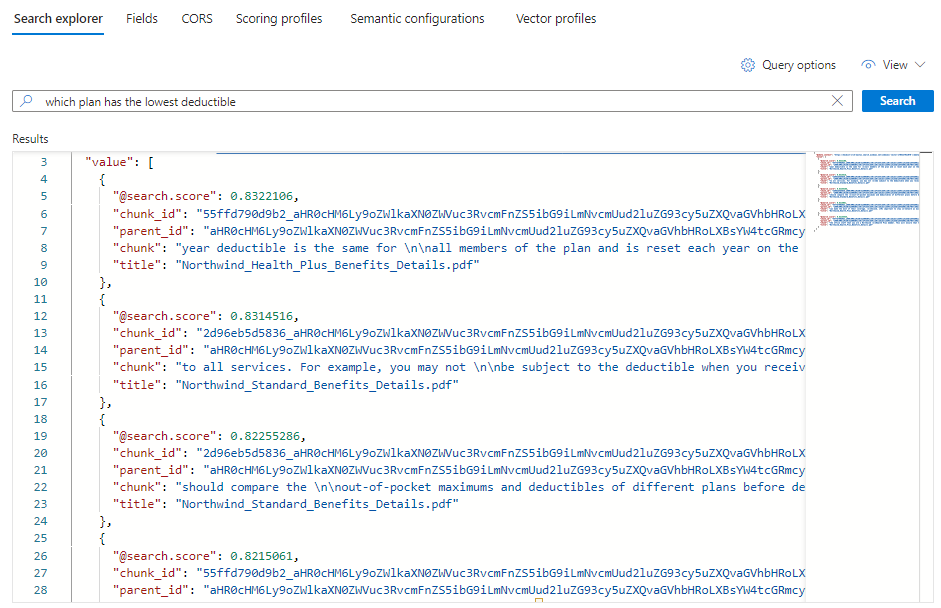
各ドキュメントは、元の PDF のチャンクです。
titleフィールドは、チャンクがどの PDF からのものであるかを示します。 各chunkはかなり長いです。 1 つをコピーしてテキスト エディターに貼り付けると、値全体を読み取ることができます。特定のドキュメントからのチャンクをすべて表示するには、以下のように特定の PDF 用の
title_parent_idフィールドのフィルターを追加します。 インデックスの [フィールド] タブを確認して、このフィールドがフィルター可能であることを確認できます。{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
クリーンアップ
Azure AI Search は課金対象のリソースです。 今後これが必要ない場合は、課金を防ぐためにサブスクリプションからこれを削除してください。
次のステップ
このクイックスタートでは、垂直統合に必要なすべてのオブジェクトを作成する [データのインポートとベクトル化] ウィザードを紹介しました。 各手順について詳しく確認するには、垂直統合サンプルを試してください。