信頼性に対する共同責任
Azure パブリック クラウド プラットフォームでは、信頼性は Microsoft とユーザーの間の共同責任です。 設計および展開するワークロードごとに異なるレベルの信頼性があるため、信頼性の観点から、これらのレベルごとに主な責任を持つユーザーを理解することが重要です。
この記事では、特に障害や災害に直面した場合の共同責任のしくみをより深く理解するために、回復性に対する共同責任 "モデル" について説明します。 このモデルを実際に使用してディザスター リカバリーを計画する方法の詳細については、「ディザスター リカバリー戦略を設計するための推奨事項」を参照してください。
信頼性に対する共同責任モデル
信頼性に対する共同責任モデルは、次の 3 つのレベルで構成されます。
- コア プラットフォームの信頼性。 Azure プラットフォームは、基になるインフラストラクチャ、サービス、プロセスを通じて、すべての顧客とすべてのサービスに基本レベルの信頼性を提供します。
- 回復性強化機能 Azure には、可用性ゾーンの使用、複数のリージョンへのデプロイ、バックアップ戦略の実装など、回復性を強化する一連の組み込み機能とサービスが用意されています。 Azure はこれらの機能を提供しますが、特定の要件に合わせてそれらを評価および構成するのはユーザーの責任です。 要件には、信頼性、コスト、パフォーマンス、規制基準への準拠が含まれます。
- アプリケーション。 他のレベルを効果的に使用するには、回復性を考慮してアプリケーションとワークロードを設計する必要があります。
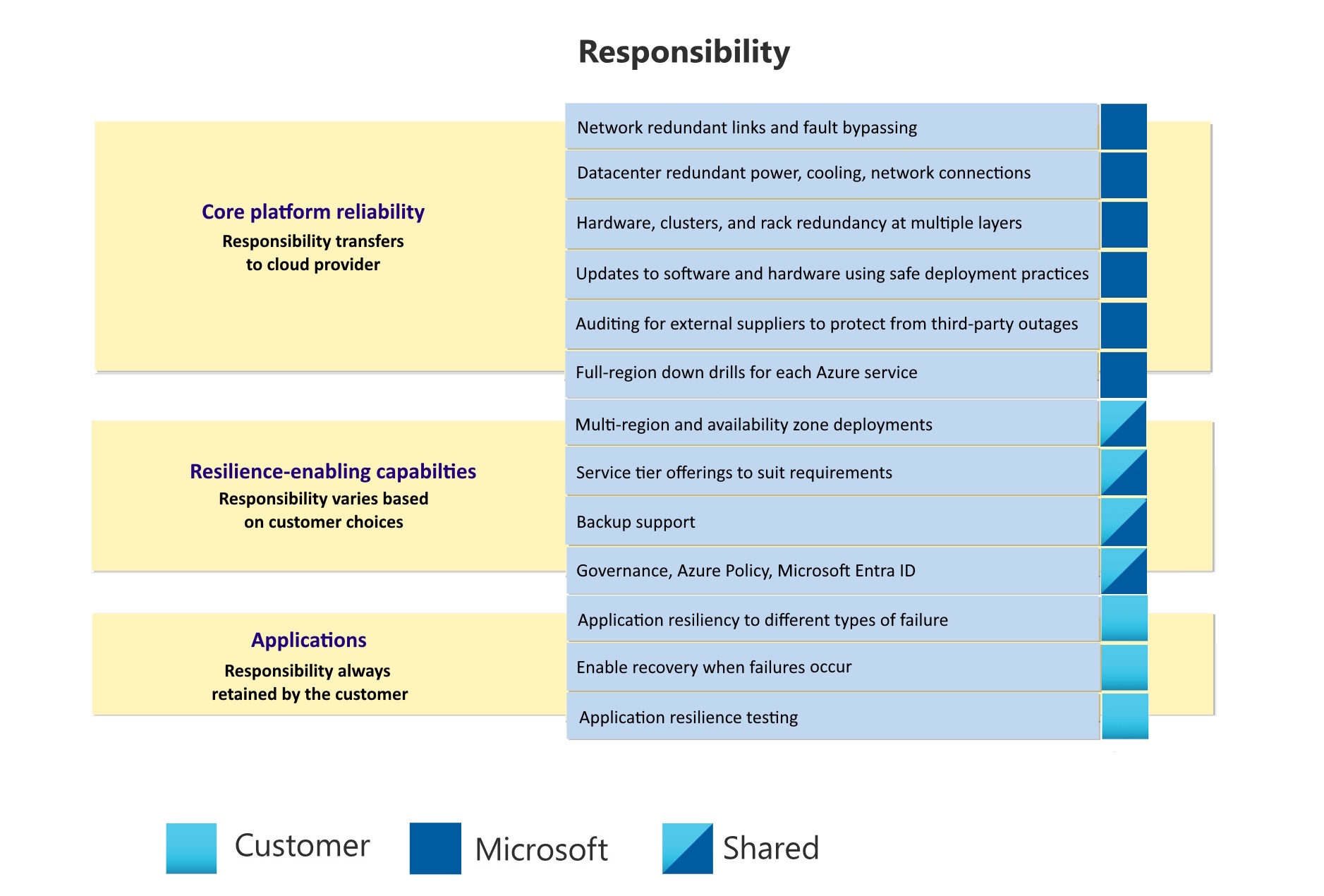
Microsoft は、コア プラットフォームの信頼性に対して単独で責任を負います。 Microsoft には、ユーザーが使用できる回復性強化機能を提供する責任もあります。 適切なコンポーネントを選択して使用する責任は、ユーザーにあります。
SaaS、PaaS、IaaS のどのサービス カテゴリを選択するかによって、どのような判断を下すかが決まります。 たとえば、SaaS サービスを使用する場合、通常は可用性ゾーンの使用をオプトインする必要はありません。 データ層に PaaS サービスを使用する場合は、バックアップの自動化された機能を利用できる可能性があります。 IaaS サービスを使用する場合は、通常、多くの信頼性機能を自分で計画して実装する必要があります。
Note
サービス カテゴリ (SaaS、PaaS、IaaS) は、サービスの広範なグループとして役立ちますが、使用する各サービスの責任を理解することが重要です。
責任ガイドは、信頼性の観点から各サービスの機能のしくみの概要を説明し、ニーズを満たすサービスを構成する方法に関する情報に基づいた意思決定を行うのに役立ちます。
また、ソリューションの設計と構成方法の決定に役立つアプリケーションとワークロードの設計、および信頼性の要件の定義もユーザーの責任です。
コア プラットフォームの信頼性
Microsoft クラウド プラットフォームは、サービスのデプロイと管理をサポートするための大量のインフラストラクチャ、ハードウェア、ソフトウェア、プロセスで構成されています。 各コンポーネントは、ハードウェアに対して複数の冗長性を備え、研究ベースのソフトウェア プロセスを使用した、高い回復性を実現するように設計されています。 これらのコンポーネントを組み合わせることで、コア プラットフォームの信頼性レベルが構成されます。 Microsoft が信頼性の高いプラットフォームを提供する方法の例を次に示します。
- ネットワークには冗長リンクがあり、障害のあるセグメントを動的にバイパスできます。
- 各リージョン内では、データセンターは低遅延ネットワークを介して接続されるため、さまざまなデータ レプリケーション アプローチが可能になります。
- データセンターの施設には、冗長な電源、冷却、ネットワーク接続があります。 これらは、セキュリティによる保護、監視、管理を行うオンサイト チームによって運営されています。
- クラスターやラックを含むハードウェアには、複数のレイヤーで冗長性があります。
- コンピューティング クラスター、ラック、ホストの更新は、制御されたプロセスに従います。 ホット パッチの適用などの手法を使用して、ホストへの影響を軽減または排除します。
- ソフトウェア プラットフォームの更新プログラムと構成の変更は、Microsoft の安全なデプロイ プラクティスに従って適用されます。
- Microsoft は、重要な外部サプライヤーを監査して、サードパーティの障害によって Azure サービスが中断されないようにしています。
- 各 Azure サービスには、詳細なディザスター リカバリー計画が必要です。 Microsoft では、運用環境と一致するリージョンで、リージョン全体のダウン時の訓練を行っています。
すべての Azure サービスは、これらのコア プラットフォームの信頼性機能と、Microsoft による継続的な改善の利点を活用しています。
回復性強化機能
Azure には、さまざまな回復性強化機能が用意されています。 Microsoft にはこれらの機能を提供する責任がありますが、ユーザーのニーズに適した機能を選択して使用することは完全にユーザーの責任です。 その機能の例をいくつか次に示します。
リージョン。 Azure には 60 を超えるリージョンがあり、1 つのソリューションで複数のリージョンを使用して geo 冗長性を実現し、データ所在地のニーズを満たし、ユーザーへの低遅延の通信をグローバルに実現できます。 リージョンの詳細については、「Azure リージョンとは?」を参照してください。
可用性ゾーン。 多くの Azure リージョンは可用性ゾーンをサポートしており、複数の独立したデータセンターのセットにワークロードを分散させることができます。 Azure サービスは、意図された目的に合った方法で可用性ゾーンをサポートします。通常は、ゾーン デプロイ (1 つのゾーンに固定) やゾーン冗長デプロイ (複数のゾーンに分散) をサポートします。 可用性ゾーンの詳細については、「可用性ゾーンとは」を参照してください。
サービス レベル。 サービスには、さまざまな要件に合うさまざまなオファリングと階層が用意されています。 たとえば、仮想マシンを作成するときに、低コストのオプションを提供する Standard ディスクと、より高いレベルの可用性を実現する Premium ディスクのいずれかを選択できます。
バックアップ。 データを格納する多くの Azure サービスではバックアップがサポートされています。バックアップは、自動、手動、またはその両方の場合があります。 バックアップを使用すると、障害だけでなく、データの破損やその他のデータ損失イベントからワークロードを保護できます。
ガバナンス。 Azure Policy、ロールベースのアクセス制御、Microsoft Entra ID の ID 保護機能などのプラットフォーム機能は、組織の要件を一貫して強制するように構成できます。 これらのアプローチにより、ワークロードのダウンタイムやその他の問題を引き起こすおそれのあるセキュリティ インシデントや偶発的な変更からワークロードを保護できます。
重要
各 Azure サービスの "サービス レベル アグリーメント" (SLA) を理解することが重要です。 SLA は、サービスの予想されるアップタイムと、SLA の対象となるために満たす必要がある条件に関する重要な情報を提供します。 各サービスの SLA については、「オンライン サービスのサービス レベル アグリーメント (SLA)」を参照してください。
アプリケーション
アプリケーションが障害に対して回復性があるように設計されていること、および信頼性に関するその他のベスト プラクティスに従っていることを確認するのは、ユーザーの責任です。 Azure Well-Architected フレームワークの柱を使用して、ワークロードの基本的なレベルでアーキテクチャの卓越性を推進します。 責任の柱は、さまざまな種類の障害に対してワークロードとアプリケーションに回復性を持たせる方法と、障害が発生したときに復旧できるようにする方法に焦点を当てています。
次のステップ
共有責任モデルは、信頼性を超えてソリューションの他の部分に適用されます。 セキュリティの共同責任モデルの詳細については、Microsoft トラスト センターを参照してください。