MLflow を使用して実験とモデルを追跡する
追跡は、実験に関する関連情報を保存するプロセスです。 この記事では、MLflow を使用して Azure Machine Learning ワークスペースで実験と実行を追跡する方法について説明します。
MLflow API で使用できる一部のメソッドは、Azure Machine Learning に接続したときに使用できない場合があります。 サポートされている操作とサポートされていない操作の詳細については、「実行と実験のクエリを実行するためのサポートマトリックス」をご覧ください。 「MLflow と Azure Machine Learning」という記事からは、Azure Machine Learning でサポートされている MLflow 機能の詳細もわかります。
Note
- Azure Databricks で実行されている実験を追跡するには、「MLflow と Azure Machine Learning を使用して Azure Databricks ML の実験を追跡する」をご覧ください。
- Azure Synapse Analytics で実行されている実験の追跡する方法については、「MLflow と Azure Machine Learning を使用して Azure Synapse Analytics ML の実験を追跡する」をご覧ください。
前提条件
無料または有料版の Azure Machine Learning を使用する Azure サブスクリプションを所有していること。
Azure CLI と Python のコマンドを実行するには、Azure CLI v2 と Azure Machine Learning SDK v2 for Python をインストールします。 Azure CLI の
ml拡張機能は、Azure Machine Learning CLI コマンドを初めて実行したときに自動的にインストールされます。
MLflow SDK
mlflowパッケージと MLflow 用の Azure Machine Learningazureml-mlflowプラグインを次のようにインストールします。pip install mlflow azureml-mlflowヒント
SQL ストレージ、サーバー、UI、またはデータ サイエンスの依存関係のない軽量 MLflow パッケージであるパッケージ
mlflow-skinnyを使用できます。 このパッケージは、デプロイを含む一連の機能をインポートせずに、MLflow の追跡とログ記録の機能を主に必要とするユーザーに推奨されます。Azure Machine Learning ワークスペースを作成します。 ワークスペースを作成するには、「開始する必要があるリソースを作成する」を参照してください。 ワークスペース内で MLflow 操作を実行するために必要なアクセス許可を確認します。
リモート追跡 (つまり、Azure Machine Learning の外部で実行されている実験の追跡) を実行する場合は、Azure Machine Learning ワークスペースの追跡 URI を指すように MLflow を構成します。 MLflow をワークスペースに接続する方法の詳細については、「Azure Machine Learning 用に MLflow を構成する」を参照してください。
実験を構成する
MLflow により実験と実行の情報が整理されます。 実行は Azure Machine Learning ではジョブと呼ばれています。 既定では、実行は「既定」という名前の自動的に作成される実験にログされますが、追跡する実験を構成できます。
Jupyter Notebook などで対話形式でトレーニングする場合は、MLflow コマンド mlflow.set_experiment() を使用します。 たとえば、次のコード スニペットで実験を構成します。
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
実行の構成
Azure Machine Learning により、MLflow で実行と呼ばれているものの中でトレーニング ジョブが追跡されます。 実行を使用して、ジョブが実行するすべての処理をキャプチャします。
対話形式で作業するとき、アクティブな実行を必要とする情報をログすると、すぐに MLflow によってトレーニング ルーチンの追跡が開始されます。 たとえば、MLflow の自動ログ機能が有効になっている場合、メトリックまたはパラメーターをログするか、トレーニング周期を開始したときに MLflow の追跡が開始します。
ただし、実験の合計時間を [期間] フィールドにキャプチャする場合は特に、通常は、実行を明示的に開始すると便利です。 実行を明示的に開始するには、mlflow.start_run() を使用 します。
実行を手動で開始するかどうかに関係なく、最終的には実行を停止する必要があります。MLflow は実験の実行が完了したことを認識し、実行の状態を 完了としてマークできるようにします。 実行を停止するには、mlflow.end_run() を使用します。
次のコードでは、手動で実行を開始し、ノートブックの末尾でそれを終了します。
mlflow.start_run()
# Your code
mlflow.end_run()
実行の終了を忘れないよう、手動で実行を開始することをお勧めします。 実行の終了を忘れないようにするため、コンテキスト マネージャー パラダイムを使用できます。
with mlflow.start_run() as run:
# Your code
mlflow.start_run() で新しい実行を開始するときは、run_name パラメーターを指定すると便利な場合があります。このパラメーターは、Azure Machine Learning のユーザー インターフェイスで実行の名前に変換されます。 この習慣は、実行をもっと簡単に識別するうえで役立ちます。
with mlflow.start_run(run_name="hello-world-example") as run:
# Your code
MLflow Autologging を有効化
手動で MLflow を使用してメトリックス、パラメーター、ファイルをログできます。MLflow の自動ログ機能に依存することもできます。 MLflow でサポートされている各機械学習フレームワークにより、自動的に追跡する内容が決定されます。
自動ログ記録を有効にするには、トレーニング コードの前に次のコードを挿入します。
mlflow.autolog()
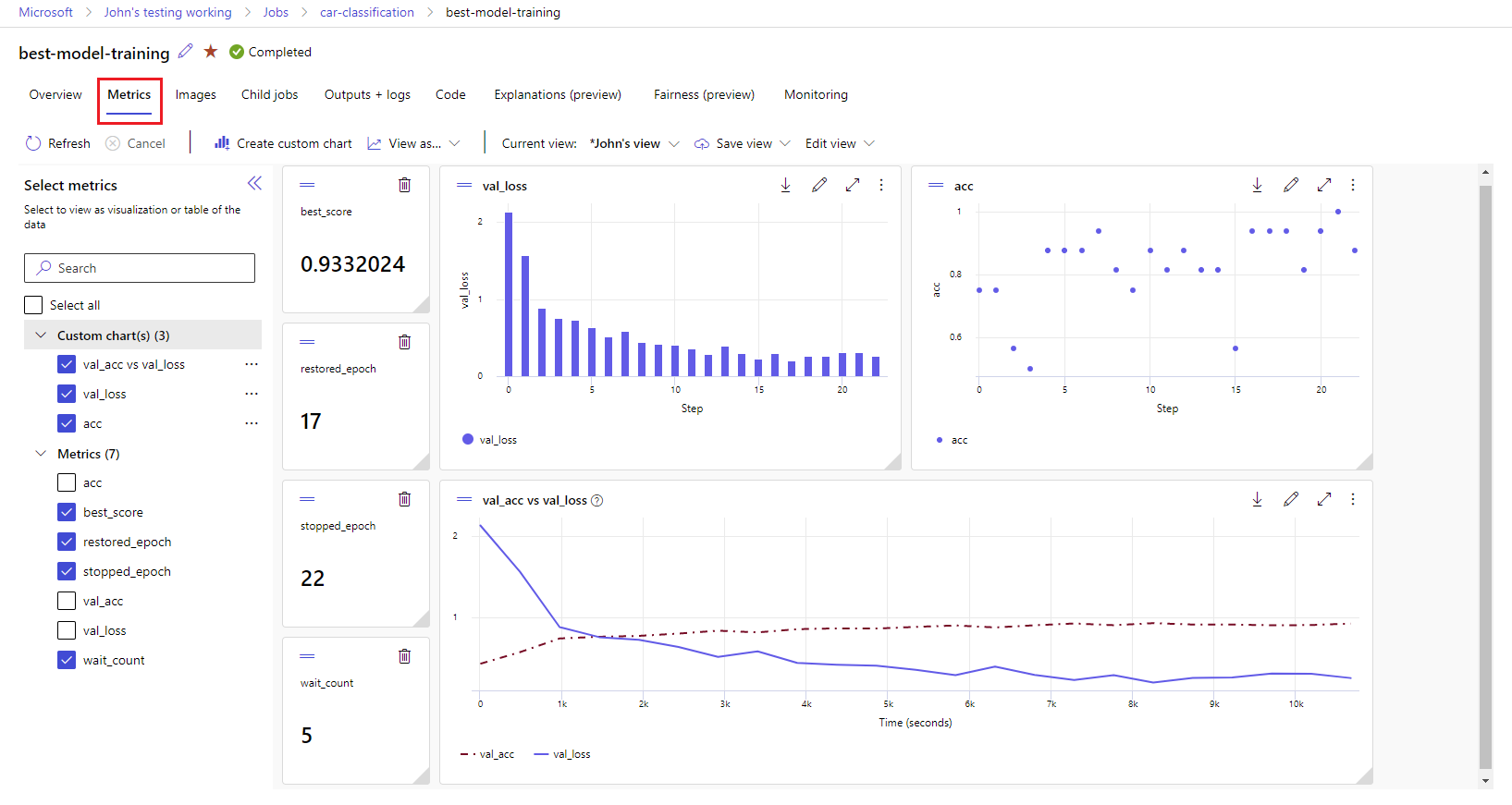
ワークスペースでのメトリックと成果物の表示
MLflow ログ記録のメトリックと成果物は、お使いのワークスペースで追跡されます。 Azure Machine Learning スタジオで表示およびアクセスしたり、MLflow SDK を介してプログラムでアクセスしたりできます。
スタジオでメトリックと成果物を表示する方法。
ワークスペースの [ジョブ] ページで、実験名を選択します。
実験の詳細ページで、[メトリック] タブを選択します。
右側にグラフをレンダリングするには、ログされたメトリックを選択します。 スムージングを適用する、色を変更する、複数のメトリックを 1 つのグラフにプロットするという方法でグラフをカスタマイズすることができます。 レイアウトのサイズを変更したり、配置を変えたりすることもできます。
目的のビューを作成したら、後で使用できるように保存し、直接リンクを使用してチームメイトと共有します。

MLflow SDK を介してメトリック、パラメーター、成果物にプログラムでアクセスまたはクエリを実行するには、mlflow.get_run() を使用します。
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
ヒント
前の例では、特定のメトリックの最後の値のみが返されます。 特定のメトリックのすべての値を取得するには、mlflow.get_metric_history メソッドを使用します。 メトリックの値の取得の詳細については、「実行からパラメーターとメトリックを取得する」をご覧ください。
ファイルやモデルなど、ログした成果物をダウンロードするには、mlflow.artifacts.download_artifacts() を使用します。
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
MLflow を使用して Azure Machine Learning の実験と実行から情報を取得して比較する方法については、「MLflow を使った実験と実行のクエリと比較」をご覧ください。