クエリの実行および MLflow を使用して実験と実行を比較する
Azure Machine Learning での実験とジョブ (あるいは実行) は、MLflow を使用してクエリを行うことができます。 トレーニング ジョブの内部で発生することを管理するために特定の SDK をインストールする必要はありません。クラウド固有の依存関係がなくなるので、ローカル実行とクラウド間の移行がよりシームレスになります。 この記事では、Python で Azure Machine Learning と MLflow SDK を使用して、ワークスペースで実験と実行に対してクエリを実行して比較する方法について説明します。
MLflow では、次のことができます。
- ワークスペースで実験の作成、クエリの実行、削除、検索を行います。
- ワークスペースで実行に対してクエリの実行、削除、検索を行う。
- 実行からメトリック、パラメーター、成果物、モデルを追跡および取得します。
オープンソース MLflow と Azure Machine Learning に接続した場合の MLflow の詳細な比較については、Azure Machine Learning での実行と実験のクエリに関するサポート マトリックスの記事を参照してください。
Note
Azure Machine Learning Python SDK v2 では、ネイティブのログまたはトラッキング機能は提供されていません。 これは、ログ記録だけでなく、ログに記録されたメトリックのクエリにも適用されます。 代わりに、MLflow を使用して実験と実行を管理してください。 この記事では、MLflow を使用して Azure Machine Learning で実験と実行を管理する方法について説明します。
MLflow REST API を使用して、実験と実行のクエリおよび検索を行うこともできます。 使用方法の例については、「Azure Machine Learning での MLflow REST の使用」を参照してください。
前提条件
MLflow SDK
mlflowパッケージと MLflow 用の Azure Machine Learningazureml-mlflowプラグインを次のようにインストールします。pip install mlflow azureml-mlflowヒント
SQL ストレージ、サーバー、UI、またはデータ サイエンスの依存関係のない軽量 MLflow パッケージであるパッケージ
mlflow-skinnyを使用できます。 このパッケージは、デプロイを含む一連の機能をインポートせずに、MLflow の追跡とログ記録の機能を主に必要とするユーザーに推奨されます。Azure Machine Learning ワークスペースを作成します。 ワークスペースを作成するには、「開始する必要があるリソースを作成する」を参照してください。 ワークスペース内で MLflow 操作を実行するために必要なアクセス許可を確認します。
リモート追跡 (つまり、Azure Machine Learning の外部で実行されている実験の追跡) を実行する場合は、Azure Machine Learning ワークスペースの追跡 URI を指すように MLflow を構成します。 MLflow をワークスペースに接続する方法の詳細については、「Azure Machine Learning 用に MLflow を構成する」を参照してください。
実験のクエリと検索を実行する
MLflow を使用して、ワークスペース内の実験を検索します。 次の例を参照してください。
アクティブなすべての実験を取得するには:
mlflow.search_experiments()Note
レガシ バージョンの MLflow (<2.0) では、代わりにメソッド
mlflow.list_experiments()を使用します。アーカイブを含むすべての実験を取得するには:
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)名前で特定の実験を取得するには:
mlflow.get_experiment_by_name(experiment_name)ID で特定の実験を取得するには:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
実験を検索する
search_experiments() メソッド (mlflow 2.0 以降で使用可能) を使用すると、filter_string を使用して条件に一致する実験を検索できます。
ID に基づいて複数の実験を取得するには:
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )特定の時刻の後に作成されたすべての実験を取得するには:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")特定のタグを持つすべての実験を取得するには:
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
クエリと検索の実行
MLflow を使用すると、任意の実験内で実行を検索できます (同時に複数の実験を含む)。 メソッド mlflow.search_runs() は検索したい実験を示す引数 experiment_ids と experiment_name を受け取ります。 ワークスペース内のすべての実験を検索したい場合は次のように search_all_experiments=True を指定することもできます。
実験名で:
mlflow.search_runs(experiment_names=[ "my_experiment" ])実験 ID で:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])ワークスペース内のすべての実験を検索するには:
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
必要に応じて複数の実験間で実行を検索できるように、experiment_ids では実験の配列の提供がサポートされていることに注意してください。 これは、同じモデルの実行が異なる実験 (異なるユーザーや異なるプロジェクト イテレーションなど) でログ記録されているときにそれらを比較したい場合に役立つ可能性があります。
重要
experiment_ids、experiment_names、または search_all_experiments が指定されていない場合、MLflow は既定で現在アクティブな実験内で検索を行います。 mlflow.set_experiment() を使用してアクティブな実験を設定できます。
既定では、MLflow から Pandas Dataframe 形式でデータが返されます。これにより、実行の分析を詳細に処理するときに便利です。 返されるデータには、次の列が含まれます。
- 実行に関する基本情報
- 列の名前を持つパラメーター
params.<parameter-name>。 - 列の名前を持つメトリック (それぞれ最後にログに記録された値)
metrics.<metric-name>。
クエリの実行時にはすべてのメトリックとパラメーターも返されます。 ただし、複数の値 (損失曲線、PR 曲線など) を含むメトリックの場合は、メトリックの最後の値のみが返されます。 特定のメトリックのすべての値を取得する場合は、mlflow.get_metric_history メソッドを使用します。 例については、「実行からのパラメーターとメトリックの取得」を参照してください。
実行の順序付け
既定では、実験の順序は start_time による降順です。これは、実験が Azure Machine Learning でキューに入った時刻です。 ただし、この既定値はパラメーター order_by を使用して変更できます。
start_timeなどの属性による実行の順序付け:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])実行の順序付けと結果の制限。 次の例では、実験の最後の 1 回の実行が返されます。
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])属性
durationで実行を並べ替えるには:mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])ヒント
attributes.durationは MLflow OSS には存在しませんが、便宜上 Azure Machine Learning で提供されています。メトリックの値で実行を並べ替えるには:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)警告
パラメーター
order_byにmetrics.*、params.*、またはtags.*が含まれる式でのorder_byの使用は、現時点ではサポートされていません。 代わりに、この例に示すように、Pandas のsort_valuesメソッドを使用してください。
実行をフィルター処理する
パラメーター filter_string を使用して、ハイパーパラメーターで特定の組み合わせを持つ実行を検索することもできます。 実行のパラメーターにアクセスするには params、実行中に記録されたメトリックにアクセスするには metrics、実行情報の詳細にアクセスするには attributes を使用します。 MLflow では、AND キーワードで結合された式がサポートされています (構文では OR はサポートされていません)。
パラメーターの値に基づいて検索を実行するには:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")警告
parametersのフィルター処理では、演算子=、like、!=のみがサポートされています。メトリックの値に基づいて検索を実行するには:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")特定のタグを持つ実行を検索するには:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")特定のユーザーによって作成された実行を検索するには:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")失敗した実行を検索します。 使用可能な値については、「状態での実行のフィルター処理」を参照してください。
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")特定の時刻より後に作成された実行を検索するには:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")ヒント
キー
attributesの場合、値は常に文字列であるため引用符で囲んでエンコードする必要があります。1 時間を超える実行を検索します。
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")ヒント
attributes.durationは MLflow OSS には存在しませんが、便宜上 Azure Machine Learning で提供されています。特定のセット内の ID を持つ実行を検索します。
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
状態別に実行をフィルター処理
状態で実行をフィルター処理する場合、MLflow は、実行のさまざまな起こりうる状態の命名に Azure Machine Learning とは異なる規則を使用します。 指定可能な値を次の表に示します。
| Azure Machine Learning ジョブの状態 | MLFlow の attributes.status |
意味 |
|---|---|---|
| 開始前 | Scheduled |
ジョブまたは実行が Azure Machine Learning によって受信されました。 |
| キュー | Scheduled |
ジョブまたは実行は実行するようにスケジュールされていますが、まだ開始されていません。 |
| 準備 | Scheduled |
ジョブまたは実行はまだ開始されていませんが、その実行にコンピューティングが割り当てられ、環境とその入力を準備しています。 |
| 実行中 | Running |
ジョブまたは実行は現在アクティブな実行中です。 |
| 完了済み | Finished |
ジョブまたは実行がエラーなしで完了しました。 |
| Failed | Failed |
ジョブまたは実行がエラーありで完了しました。 |
| 取り消し済み | Killed |
ジョブまたは実行がユーザーによって取り消されたか、システムによって終了されました。 |
例:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
メトリック、パラメーター、成果物、モデルを取得する
メソッド search_runs は、既定では、制限された量の情報を含む Pandas Dataframe を返します。 必要に応じて Python オブジェクトを取得することができ、それらの詳細を取得するのに役立つ場合があります。 出力が返される方法を制御するには、output_format パラメーターを使用します。
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
その後、info メンバーから詳細にアクセスできます。 次のサンプルは、run_id の取得方法を示しています。
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
実行からパラメーターとメトリックを取得する
output_format="list" を使用して実行が返されると、キー data を使用して簡単にパラメーターにアクセスできます。
last_run.data.params
次のように同じ方法で、メトリックのクエリを実行できます。
last_run.data.metrics
複数の値 (損失曲線、PR 曲線など) を含むメトリックの場合は、メトリックの最後にログ記録された値のみが返されます。 特定のメトリックのすべての値を取得する場合は、mlflow.get_metric_history メソッドを使用します。 次のように、このメソッドでは、MlflowClient を使用する必要があります。
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
実行から成果物を取得する
MLflow は、実行によってログされたあらゆる成果物のクエリを実行できます。 成果物に実行オブジェクト自体を使用してアクセスすることはできません。代わりに、次のように MLflow クライアントを使用する必要があります。
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
上記のメソッドでは、実行で記録されたすべての成果物がリストされますが、それらは成果物ストア (Azure Machine Learning ストレージ) に保存されたままになります。 それらのいずれかをダウンロードするには、次のようにメソッド download_artifact を使用します。
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
注意
レガシ バージョンの MLflow (<2.0) の場合は、代わりにメソッド MlflowClient.download_artifacts() を使います。
実行からモデルを取得する
モデルは、実行でログに記録し、そこから直接取得することもできます。 モデルを取得するには、格納先の成果物へのパスを知っている必要があります。 MLflow モデルは常にフォルダーであるため、メソッド list_artifacts を使用してモデルを表す成果物を検索できます。 モデルをダウンロードする場合は、次のように download_artifact メソッドを使用して、モデルが格納されているパスを指定します。
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
その後、フレーバー固有の名前空間で一般的な関数 load_model を使用して、ダウンロードした成果物からモデルを読み込み戻すことができます。 xgboost の使用例を次に示します。
model = mlflow.xgboost.load_model(model_local_path)
MLflow では、両方の操作を一度に実行し、モデルを 1 つの命令でダウンロードして読み込むこともできます。 MLflow によってモデルが一時フォルダーにダウンロードされ、そこから読み込まれます。 メソッド load_model は、URI 形式を使って、どこからモデルを取得する必要があるかを示します。 実行からモデルを読み込む場合、URI 構造体は次のようになります。
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
ヒント
モデル レジストリに登録されているモデルに対してクエリの実行や読み込みを行うには、「MLflow を使用して Azure Machine Learning でモデル レジストリを管理する」を参照してください。
子 (入れ子になった) 実行を取得する
MLflow では、子 (入れ子になった) 実行の概念がサポートされています。 これらの実行は、メインのトレーニング プロセスとは別に追跡する必要があるトレーニング ルーチンをスピンオフする必要がある場合に便利です。 ハイパーパラメーターの調整最適化プロセスまたは Azure Machine Learning パイプラインは、複数の子実行が生成されるジョブの一般的な例です。 親実行の実行 ID を含むプロパティ タグ mlflow.parentRunId を使用して、特定の実行のすべての子実行をクエリできます。
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
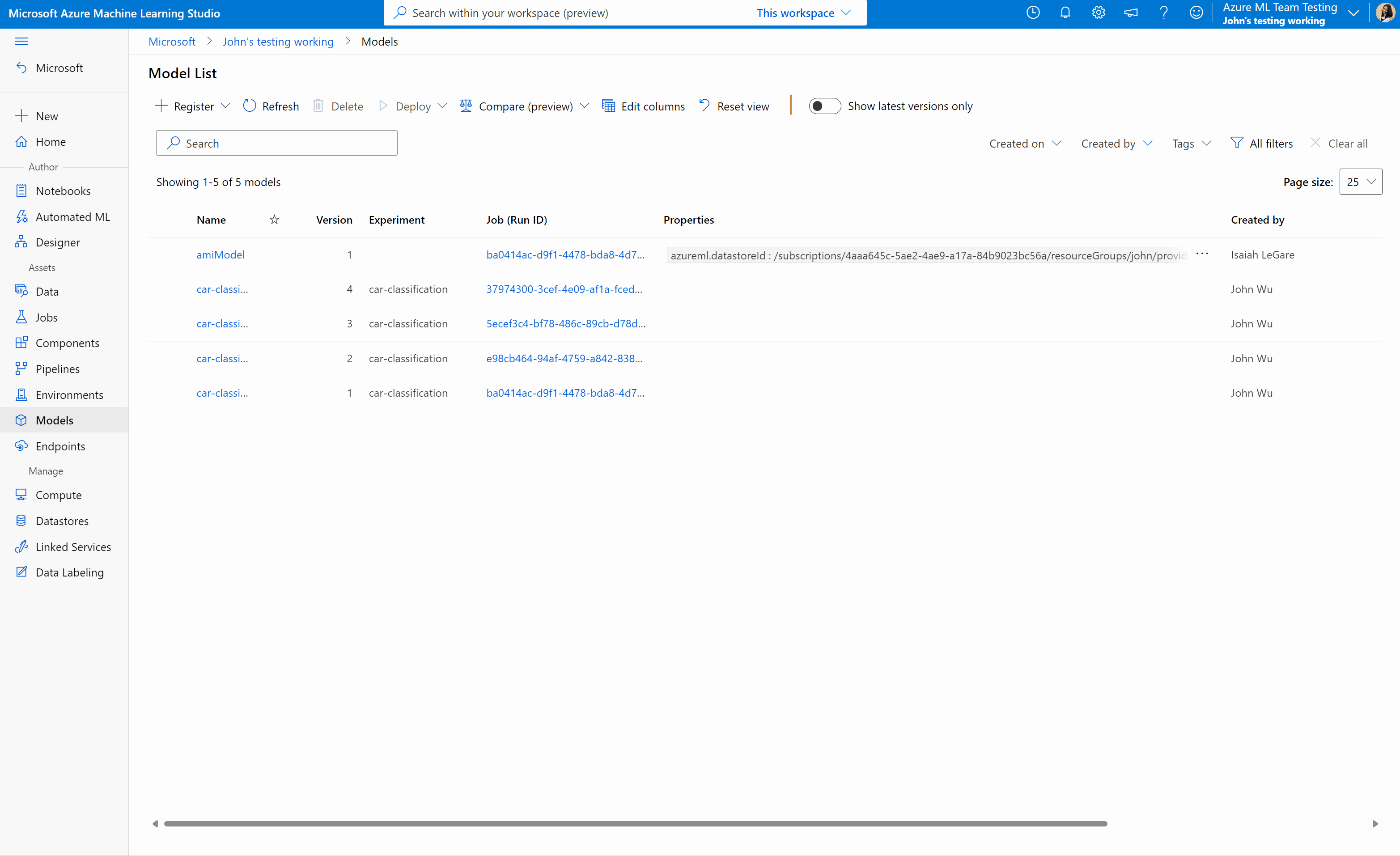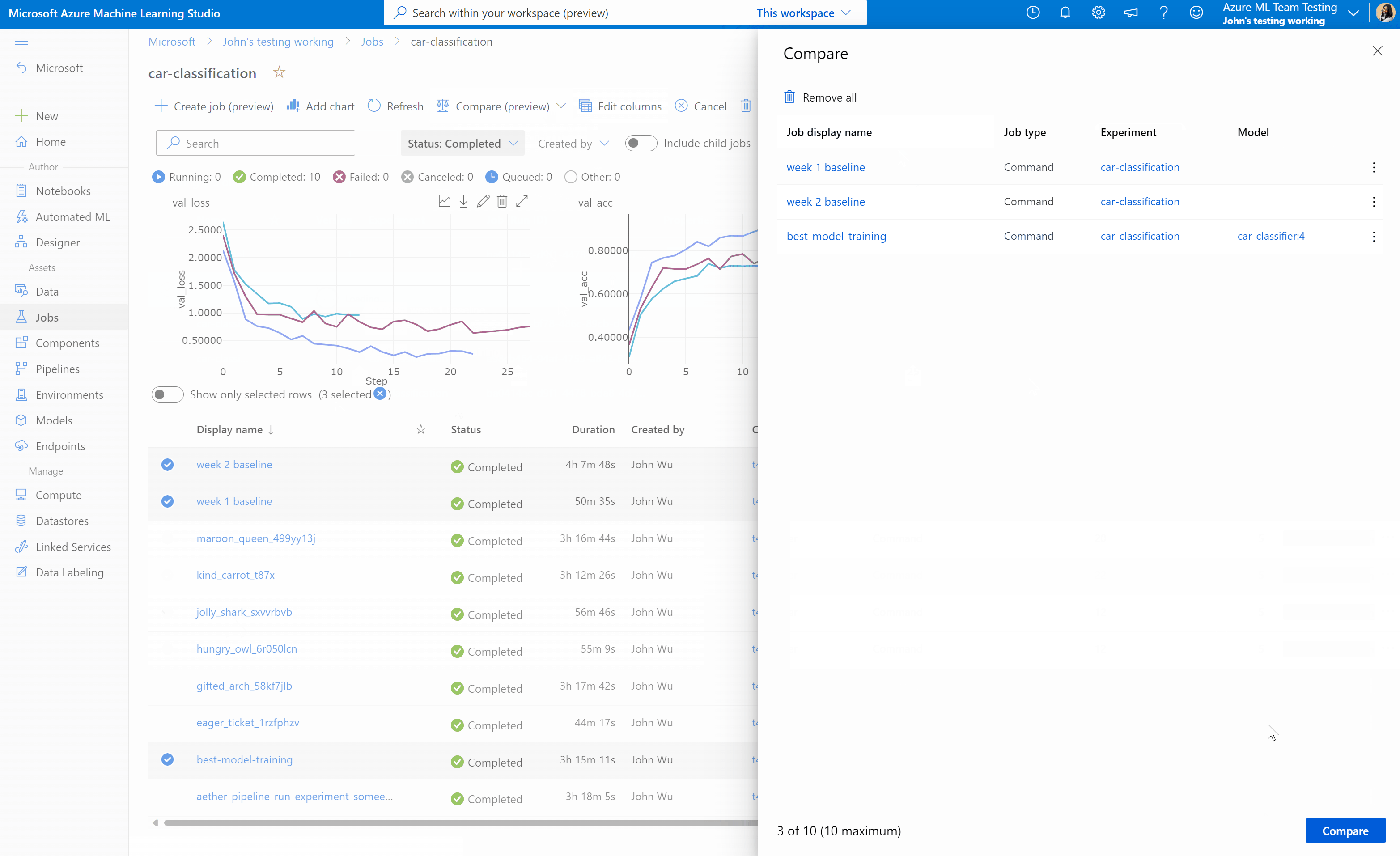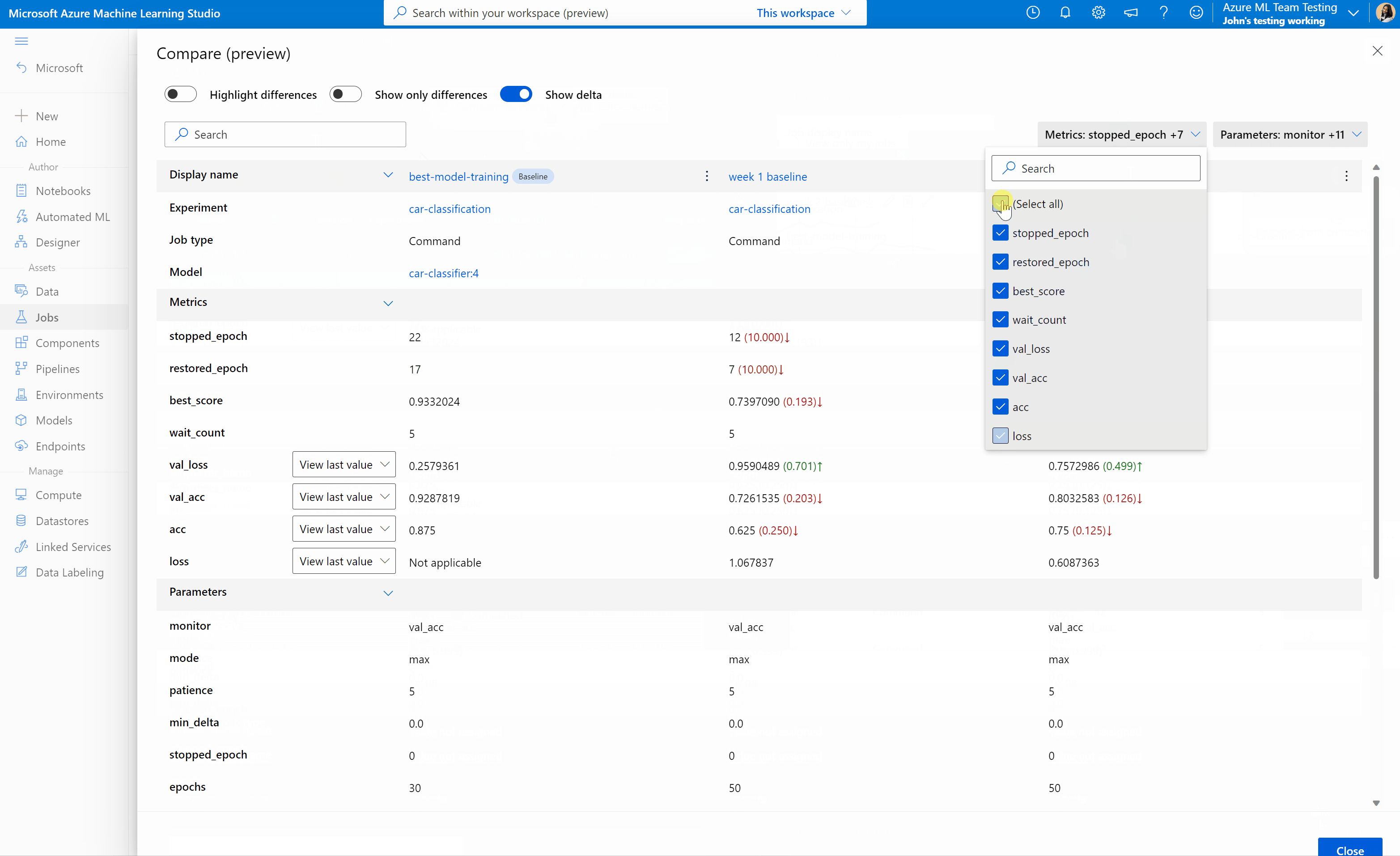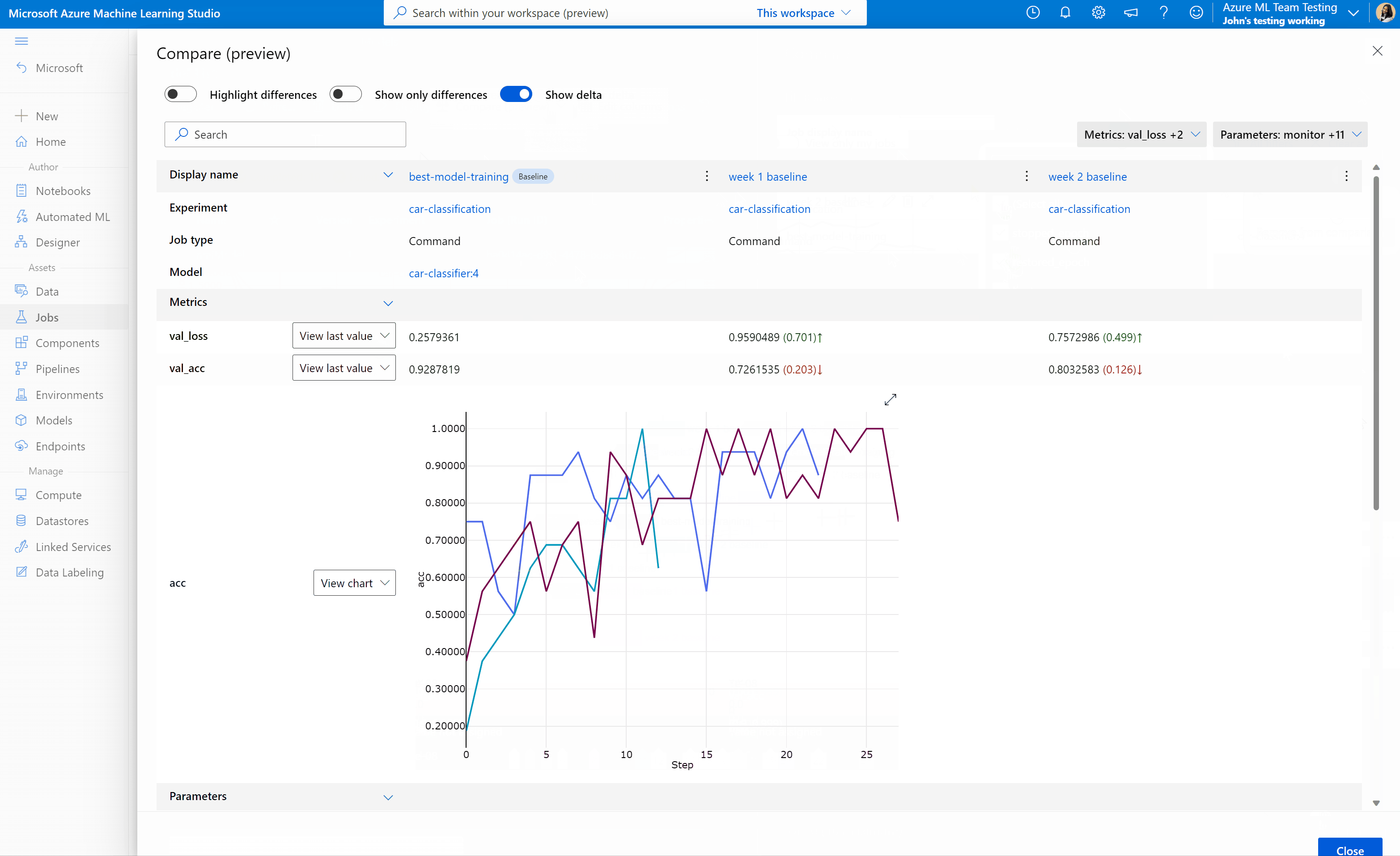
Azure Machine Learning スタジオでのジョブとモデルの比較 (プレビュー)
Azure Machine Learning スタジオでジョブとモデルの品質を比較して評価するには、プレビュー パネルを使用してこの機能を有効にします。 有効にすると、選択したジョブやモデルの間でパラメーター、メトリック、タグを比較できます。
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 プレビュー バージョンはサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
Azure Machine Learning ノートブックでの MLflow は、この記事で提示した概念を示し、さらに詳しく説明します。
- MLflow を使用して分類子をトレーニングおよび追跡する: MLflow を使用して実験を追跡し、モデルをログに記録し、複数のフレーバーをパイプラインに結合する方法を示します。
- MLflow を使用して実験と実行を管理する: MLflow を使用して Azure Machine Learning から実験、実行、メトリック、パラメーター、成果物のクエリを実行する方法を示します。
実行と実験のクエリを実行するためのサポート マトリックス
MLflow SDK では、実行を取得するためのいくつかのメソッドが公開されています。これには、返される内容と方法を制御するオプションが含まれます。 次の表を使用して、Azure Machine Learning に接続したときに MLflow で現在サポートされているメソッドを確認します。
| 機能 | MLflow でサポート | Azure Machine Learning でサポートされている |
|---|---|---|
| 属性による実行の順序付け | ✓ | ✓ |
| メトリックによる実行の順序付け | ✓ | 1 |
| パラメーターによる実行の順序付け | ✓ | 1 |
| タグによる実行の順序付け | ✓ | 1 |
| 属性による実行のフィルター処理 | ✓ | ✓ |
| メトリックによる実行のフィルター処理 | ✓ | ✓ |
| 特殊文字 (エスケープ) を使用したメトリックによる実行のフィルター処理 | ✓ | |
| パラメーターによる実行のフィルター処理 | ✓ | ✓ |
| タグによる実行のフィルター処理 | ✓ | ✓ |
=、!=、>、>=、<、<= を含む数値比較子 (メトリック) を使用した実行のフィルター処理 |
✓ | ✓ |
文字列比較子 (パラメーター、タグ、属性) を使用した実行のフィルター処理: = と != |
✓ | ✓2 |
文字列比較子 (パラメーター、タグ、属性) を使用した実行のフィルター処理: LIKE/ILIKE |
✓ | ✓ |
比較子 AND を使用した実行のフィルター処理 |
✓ | ✓ |
比較子 OR を使用した実行のフィルター処理 |
||
| 実験の名前の変更 | ✓ |
注意
- 1 Azure Machine Learning で同じ機能を実現する方法の手順と例については、「実験の並べ替え」セクションを確認してください。
- 2 タグに対する
!=はサポートされていません。