Azure Machine Learning を使用して Keras モデルを大規模にトレーニングする
適用対象:  Python SDK azure-ai-ml v2 (現行)
Python SDK azure-ai-ml v2 (現行)
この記事では、Azure Machine Learning Python SDK v2 を使用して、Keras トレーニング スクリプトを実行する方法について説明します。
この記事のコード例では、Azure Machine Learning を使用して、TensorFlow バックエンドを使用して構築された Keras モデルのトレーニング、登録、デプロイを行います。 このモデルは、TensorFlow 上で実行される Keras Python ライブラリを使用して構築されたディープ ニューラル ネットワーク (DNN) であり、一般的な MIST データセットからの手書きの数字を分類します。
Keras は、開発を簡素化するために他の一般的な DNN フレームワーク上で動作できる高レベルのニューラル ネットワーク API です。 Azure Machine Learning では、エラスティック クラウド コンピューティング リソースを使用して、トレーニング ジョブを迅速にスケールアウトできます。 また、トレーニング実行、バージョン モデル、デプロイ モデル、その他多くを追跡することもできます。
Keras モデルを最初から開発しているか、または既存のモデルをクラウドに導入しているかにかかわらず、Azure Machine Learning は運用環境対応のモデルを構築するのに役立ちます。
注意
スタンドアロンの Keras パッケージではなく、TensorFlow に組み込まれた Keras API の tf.keras を使用している場合は、代わりに TensorFlow モデルのトレーニングに関する記事をご覧ください。
前提条件
この記事を利用するには、次の操作を行う必要があります。
- Azure サブスクリプションにアクセスします。 アカウントがまだない場合は、無料のアカウントを作成してください。
- この記事のコードは、Azure Machine Learning コンピューティング インスタンスまたは独自の Jupyter Notebook のいずれかで実行します。
- Azure Machine Learning コンピューティング インスタンス - ダウンロードやインストールは必要ありません
- 「作業を開始するために必要なリソースを作成する」の手順を完了して、SDK とサンプル リポジトリが事前に読み込まれた専用のノートブック サーバーを作成します。
- ノートブック サーバー上のディープ ラーニングの samples フォルダーで、v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-keras の順にディレクトリを移動して、完成した展開済みノートブックを見つけます。
- Jupyter Notebook サーバー
- Azure Machine Learning コンピューティング インスタンス - ダウンロードやインストールは必要ありません
- トレーニング スクリプト keras_mnist.py と utils.py をダウンロードします。
このガイドの完成した Jupyter Notebook バージョンは、GitHub サンプル ページにもあります。
この記事のコードを実行して GPU クラスターを作成する前に、ワークスペースのクォータの引き上げを要求する必要があります。
ジョブをセットアップする
このセクションでは、必要な Python パッケージを読み込み、ワークスペースに接続し、コマンド ジョブを実行するコンピューティング リソースを作成し、ジョブを実行する環境を作成することで、トレーニング用のジョブを設定します。
ワークスペースに接続する
まず、Azure Machine Learning ワークスペースに接続する必要があります。 Azure Machine Learning ワークスペースは、サービス用の最上位のリソースです。 Azure Machine Learning を使用するときに作成する、すべての成果物を操作するための一元的な場所が提供されます。
ここでは、DefaultAzureCredential を使ってワークスペースへのアクセスを取得しています。 この資格情報を使うと、ほとんどの Azure SDK 認証シナリオに対応できます。
DefaultAzureCredential でうまくいかない場合は、他に使用可能な資格情報について、azure-identity reference documentation または Set up authentication を参照してください。
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()ブラウザーを使用してサインインと認証を行う場合は、次のコードのコメントを解除し、代わりに使用する必要があります。
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
次に、サブスクリプション ID、リソース グループ名、ワークスペース名を指定して、ワークスペースへのハンドルを取得します。 これらのパラメーターを見つけるには、次の手順を実行します。
- Azure Machine Learning スタジオ ツール バーの右上隅にあるワークスペース名を探します。
- ワークスペース名を選択して、リソース グループとサブスクリプション ID を表示します。
- リソース グループとサブスクリプション ID の値をコードにコピーします。
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)このスクリプトの実行結果は、他のリソースとジョブを管理するために使用するワークスペース ハンドルになります。
Note
MLClientを作成しても、クライアントはワークスペースに接続されません。 クライアントの初期化は遅延型なので、初めて呼び出す必要が生じるときまで待機します。 この記事では、これはコンピューティングの作成時に発生します。
ジョブを実行するコンピューティング リソースを作成する
Azure Machine Learning には、ジョブを実行するためのコンピューティング リソースが必要です。 このリソースには、Linux または Windows OS の単一または複数ノードのマシン、または Spark などの特定のコンピューティング ファブリックを指定できます。
次のスクリプト例では、Linux compute cluster をプロビジョニングします。 VM のサイズと価格の完全な一覧については、Azure Machine Learning pricing ページを参照してください。 この例には GPU クラスターが必要なので、STANDARD_NC6 モデルを選択して Azure Machine Learning コンピューティングを作成してみましょう。
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)ジョブ環境を作成する
Azure Machine Learning ジョブを実行するには、環境が必要です。 Azure Machine Learning 環境では、コンピューティング リソースで機械学習トレーニング スクリプトを実行するために必要な依存関係 (ソフトウェア ランタイムやライブラリなど) がカプセル化されます。 この環境は、ローカル コンピューター上の Python 環境に似ています。
Azure Machine Learning では、キュレーションされた (または既製の) 環境を使うか、Docker イメージまたは Conda 構成を使ってカスタム環境を作成できます。 この記事では、Conda の YAML ファイルを使って、ジョブ用のカスタム Conda 環境を作ります。
カスタム環境を作成する
カスタム環境を作るには、YAML ファイルで Conda の依存関係を定義します。 まず、ファイルを格納するためのディレクトリを作ります。 この例では、そのディレクトリの名前を dependencies にします。
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)次に、依存関係ディレクトリにファイルを作成します。 この例では、そのファイルの名前を conda.yml にします。
%%writefile {dependencies_dir}/conda.yaml
name: keras-env
channels:
- conda-forge
dependencies:
- python=3.8
- pip=21.2.4
- pip:
- protobuf~=3.20
- numpy==1.22
- tensorflow-gpu==2.2.0
- keras<=2.3.1
- matplotlib
- azureml-mlflow==1.42.0この仕様には、ジョブで使ういくつかの通常のパッケージ (numpy や pip など) が含まれています。
次に、YAML ファイルを使ってこのカスタム環境を作成し、ワークスペースに登録します。 環境は、実行時に Docker コンテナーにパッケージ化されます。
from azure.ai.ml.entities import Environment
custom_env_name = "keras-env"
job_env = Environment(
name=custom_env_name,
description="Custom environment for keras image classification",
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
job_env = ml_client.environments.create_or_update(job_env)
print(
f"Environment with name {job_env.name} is registered to workspace, the environment version is {job_env.version}"
)環境の作成と使用の詳細については、「Azure Machine Learning でソフトウェア環境を作成して使用する」をご覧ください。
トレーニング ジョブを構成して送信する
このセクションでは、まずトレーニング用のデータを紹介します。 次に、提供したトレーニング スクリプトを使用して、トレーニング ジョブを実行する方法について説明します。 トレーニング スクリプトを実行するためのコマンドを構成して、トレーニング ジョブをビルドする方法について説明します。 次に、トレーニング ジョブを送信して Azure Machine Learning で実行します。
トレーニング データを取得する
修正された国立標準技術研究所 (MNIST) データベースの手書き数字のデータを使用します。 このデータは、Yan LeCun の Web サイトから取得され、Azure ストレージ アカウントに格納されます。
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"MNIST データセットの詳細については、Yan LeCun の Web サイトを参照してください。
トレーニング スクリプトを準備する
この記事では、トレーニング スクリプト keras_mnist.py を提供しました。 実際には、コードを変更しなくても、あらゆるカスタム トレーニング スクリプトをそのまま Azure Machine Learning で実行できるはずです。
提供されているトレーニング スクリプトは次の処理を実行します。
- データの前処理を処理し、データをテスト データとトレーニング データに分割する
- データを使用してモデルをトレーニングする
- 出力モデルを返す。
パイプラインの実行中は、MLFlow を使用してパラメーターとメトリックをログに記録します。 MLFlow 追跡を有効にする方法については、「MLflow を使用して ML の実験とモデルを追跡する」を参照してください。
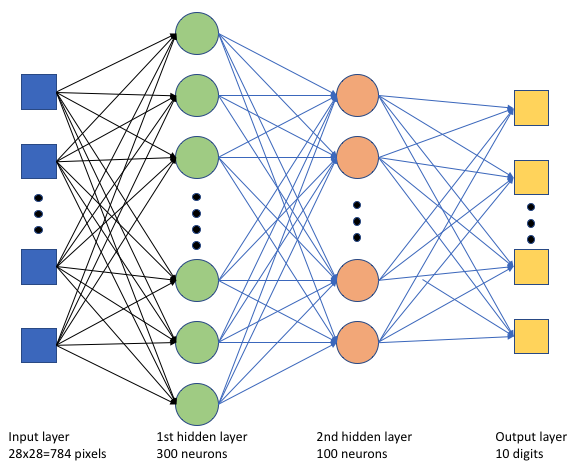
トレーニング スクリプト keras_mnist.pyでは、単純なディープ ニューラル ネットワーク (DNN) を作成します。 この DNN には次の情報があります。
- 28 * 28 = 784 ニューロンを持つ入力層。 各ニューロンは画像ピクセルを表します。
- 2 つの隠れ層。 最初の隠れ層には 300 個のニューロンがあり、2 番目の隠れ層には 100 個のニューロンがあります。
- 10 ニューロンを持つ出力層。 各ニューロンは、0 から 9 の対象となるラベルを表します。
トレーニング ジョブを作成する
ジョブの実行に必要なすべての資産が揃ったので、次は Azure Machine Learning Python SDK v2 を使ってジョブを作成します。 この例では、command を作成します。
Azure Machine Learning command は、クラウドでトレーニング コードを実行するために必要なすべての詳細を指定するリソースです。 これらの詳細には、入力と出力、使用するハードウェアの種類、インストールするソフトウェア、コードの実行方法が含まれます。 command には、1 つのコマンドを実行するための情報が含まれています。
コマンドを構成する
汎用 command を使用してトレーニング スクリプトを実行し、目的のタスクを実行します。 トレーニング ジョブの構成の詳細を指定する Command オブジェクトを作成します。
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=50,
first_layer_neurons=300,
second_layer_neurons=100,
learning_rate=0.001,
),
compute=gpu_compute_target,
environment=f"{job_env.name}:{job_env.version}",
code="./src/",
command="python keras_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="keras-dnn-image-classify",
display_name="keras-classify-mnist-digit-images-with-dnn",
)このコマンドの入力には、データの場所、バッチ サイズ、1 番目と 2 番目のレイヤーのニューロンの数、学習率が含まれます。 Web パスが入力として直接渡されていることに注意してください。
パラメーター値については次のとおりです。
- このコマンドを実行するために作成したコンピューティング クラスター
gpu_compute_target = "gpu-cluster"を指定します。 - Azure Machine Learning ジョブを実行するために作成したカスタム環境
keras-envを指定します。 - コマンド ライン アクション自体を構成します。この場合、コマンドは
python keras_mnist.pyです。 コマンドの入力と出力には${{ ... }}表記法を使用してアクセスできます。 - 表示名や実験名などのメタデータを構成する。ここで、実験は特定のプロジェクトで行われるすべてのイテレーションのコンテナーです。 同じ実験名で送信されたすべてのジョブは、Azure Machine Learning スタジオ上ではすべて隣り合わせに表示されます。
- このコマンドを実行するために作成したコンピューティング クラスター
この例では、
UserIdentityを使用してコマンドを実行します。 ユーザー ID を使用すると、コマンドは ID を使用してジョブを実行し、BLOB からデータにアクセスすることを意味します。
ジョブを送信する
次に、Azure Machine Learning で実行するジョブを送信します。 今回は ml_client.jobs に対して create_or_update を使います。
ml_client.jobs.create_or_update(job)完了すると、ジョブは (トレーニングの結果として) モデルをワークスペースに登録し、Azure Machine Learning スタジオでジョブを表示するためのリンクを出力します。
警告
Azure Machine Learning では、ソース ディレクトリ全体をコピーすることで、トレーニング スクリプトが実行されます。 アップロードしたくない機密データがある場合は、.ignore ファイルを使用するか、ソース ディレクトリに含めないようにします。
ジョブ実行中の動作
ジョブの実行は、以下の段階を経て実施されます。
準備:Docker イメージは、定義されている環境に従って作成されます。 イメージはワークスペースのコンテナー レジストリにアップロードされ、後で実行するためにキャッシュされます。 ログもジョブ履歴にストリーミングされ、表示して進行状況を監視できます。 キュレーションされた環境が指定されている場合は、そのキュレーションされた環境を補足するキャッシュ済みのイメージが使用されます。
スケーリング: 実行に現在使用可能な数より多くのノードが必要な場合、クラスターはスケールアップを試みます。
実行中: スクリプト フォルダー src 内のすべてのスクリプトがコンピューティング先にアップロードされ、データ ストアがマウントまたはコピーされて、スクリプトが実行されます。 stdout からの出力と ./logs フォルダーがジョブ履歴にストリーミングされるので、ジョブの監視のために使用できます。
モデルのハイパーパラメーターをチューニングする
1 組のパラメーターを使用してモデルをトレーニングしたので、モデルの精度をさらに上げることができるかどうかを見てみましょう。 Azure Machine Learning の sweep 機能を使用して、モデルのハイパーパラメーターを調整して最適化できます。
モデルのハイパーパラメーターを調整するには、トレーニング中に検索するパラメーター空間を定義します。 これを行うには、トレーニング ジョブに渡されるパラメーター (batch_size、first_layer_neurons、second_layer_neurons、および learning_rate) の一部を azure.ml.sweep パッケージからの特別な入力に置き換えます。
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[25, 50, 100]),
first_layer_neurons=Choice(values=[10, 50, 200, 300, 500]),
second_layer_neurons=Choice(values=[10, 50, 200, 500]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)次に、監視する主要メトリックや使用するサンプリング アルゴリズムなど、いくつかのスイープ固有のパラメーターを使用して、コマンド ジョブのスイープを構成します。
次のコードでは、ランダム サンプリングを使用して、主要メトリック validation_acc を最大化するために、さまざまな構成セットのハイパーパラメーターを試します。
また、早期終了ポリシー BanditPolicy も定義します。 このポリシーは、2 回の反復ごとにジョブをチェックすることによって動作します。 主要メトリック validation_acc が上位 10% の範囲外の場合、Azure Machine Learning はジョブを終了します。 これにより、モデルでは、ターゲット メトリックへの到達を支援する見込みがないハイパーパラメーターの探索を回避します。
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="Accuracy",
goal="Maximize",
max_total_trials=20,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)これで、以前と同様にこのジョブを送信できます。 今回は、トレーニング ジョブをスイープするスイープ ジョブを実行します。
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)ジョブの実行中に表示されるスタジオ ユーザー インターフェイス リンクを使用して、ジョブを監視できます。
最適なモデルを見つけて登録する
すべての実行が完了すると、最も高い精度でモデルを生成した実行を見つけることができます。
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "keras_dnn_mnist_model"
path="azureml://jobs/{}/outputs/artifacts/paths/keras_dnn_mnist_model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="mlflow_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)その後、このモデルを登録できます。
registered_model = ml_client.models.create_or_update(model=model)モデルをオンライン エンドポイントとしてデプロイする
モデルを登録したら、オンライン エンドポイント (つまり、Azure クラウドの Web サービス) としてデプロイできます。
通常、機械学習サービスをデプロイするには、以下のものが必要です。
- デプロイするモデル資産。 これらの資産には、トレーニング ジョブに既に登録したモデルのファイルとメタデータが含まれます。
- サービスとして実行するコード。 コードは、特定の入力要求 (エントリ スクリプト) でモデルを実行します。 このエントリ スクリプトは、デプロイされた Web サービスに送信されたデータを受け取り、それをモデルに渡します。 モデルがデータを処理した後、スクリプトはモデルの応答をクライアントに返します。 スクリプトはこのモデルに固有で、モデルが受け入れ、返すデータを理解する必要があります。 MLFlow モデルを使用すると、Azure Machine Learning によってこのスクリプトが自動的に作成されます。
デプロイの詳細については、「Python SDK v2 を使用して、マネージド オンライン エンドポイントに機械学習モデルをデプロイしてスコアリングする」を参照してください。
新しいオンライン エンドポイントを作成する
モデルをデプロイする最初の手順として、オンライン エンドポイントを作成する必要があります。 エンドポイント名は、Azure リージョン全体で一意である必要があります。 この記事では、汎用一意識別子 (UUID) を使用して一意の名前を作成します。
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "keras-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using Keras",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")エンドポイントを作成したら、次のように取得できます。
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)モデルをエンドポイントにデプロイする
エンドポイントを作成したら、エントリ スクリプトを使用してモデルをデプロイできます。 1 つのエンドポイントに複数のデプロイを設定できます。 ルールを使用すると、エンドポイントはトラフィックをこれらのデプロイに転送できます。
次のコードでは、受信トラフィックの 100% を処理する 1 つのデプロイを作成します。 デプロイに任意の色名 (tff-blue) を指定しました。 デプロイには、tff-green や tff-red などの他の名前を使用することもできます。 エンドポイントにモデルをデプロイするコードでは、次の処理が行われます。
- 前に登録したモデルの最適なバージョンをデプロイする
score.pyファイルを使用してモデルにスコアを付けする- 推論を実行するために (前に作成した) カスタム環境を使用する
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
model = registered_model
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="keras-blue-deployment",
endpoint_name=online_endpoint_name,
model=model,
# code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Note
このデプロイが完了するまでに少し時間がかかると想定してください。
デプロイしたモデルをテストする
エンドポイントにモデルをデプロイしたので、エンドポイントの invoke メソッドを使用して、デプロイされたモデルの出力を予測できます。
エンドポイントをテストするには、何らかのテスト データが必要です。 トレーニング スクリプトで使用したテスト データをローカルでダウンロードしてみましょう。
import urllib.request
data_folder = os.path.join(os.getcwd(), "data")
os.makedirs(data_folder, exist_ok=True)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-images-idx3-ubyte.gz",
filename=os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"),
)
urllib.request.urlretrieve(
"https://azureopendatastorage.blob.core.windows.net/mnist/t10k-labels-idx1-ubyte.gz",
filename=os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"),
)これらをテスト データセットに読み込みます。
from src.utils import load_data
X_test = load_data(os.path.join(data_folder, "t10k-images-idx3-ubyte.gz"), False)
y_test = load_data(
os.path.join(data_folder, "t10k-labels-idx1-ubyte.gz"), True
).reshape(-1)テスト セットから 30 個のランダム サンプルを選択し、JSON ファイルに書き込みます。
import json
import numpy as np
# find 30 random samples from test set
n = 30
sample_indices = np.random.permutation(X_test.shape[0])[0:n]
test_samples = json.dumps({"input_data": X_test[sample_indices].tolist()})
# test_samples = bytes(test_samples, encoding='utf8')
with open("request.json", "w") as outfile:
outfile.write(test_samples)次に、エンドポイントを呼び出し、返された予測を出力し、入力イメージと共にプロットできます。 正しく分類されていないサンプルを強調表示するには、赤いフォントの色と反転画像 (黒の場合は白) を使用します。
import matplotlib.pyplot as plt
# predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request.json",
deployment_name="keras-blue-deployment",
)
# compare actual value vs. the predicted values:
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Note
モデルの精度は高いので、必要に応じて、不適切な分類のサンプルが表示されるまでセルを何度か実行します。
リソースをクリーンアップする
エンドポイントを使用しない場合は、削除してリソースの使用を停止します。 他のデプロイがエンドポイントを使っていないことを確認してから削除してください。
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Note
このクリーンアップが完了するまでに少し時間がかかると想定してください。
次の手順
この記事では、Keras モデルのトレーニングと登録を行いました。 また、モデルをオンライン エンドポイントにデプロイしました。 Azure Machine Learning の詳細については、以下の他の記事をご覧ください。