Azure Databricks と自動 ML を使用する開発環境を Azure Machine Learning 内に構成する方法について説明します。
Azure Databricks は、Azure クラウド内のスケーラブルな Apache Spark プラットフォームで大規模な集中型機械学習ワークフローを実行する場合に最適です。 これは、CPU または GPU ベースのコンピューティング クラスターにより、コラボレーションに適した Notebook ベースの環境を提供するものです。
その他の機械学習開発環境については、Python 開発環境のセットアップに関するページを参照してください。
前提条件
Azure Machine Learning ワークスペース。 作成するには、ワークスペース リソースの作成に関する記事の手順に従います。
Azure Machine Learning と AutoML を使用する Azure Databricks
Azure Databricks は、Azure Machine Learning と、その AutoML 機能と統合されています。
Azure Databricks は、以下のように使用できます。
- Spark MLlib を使用してモデルをトレーニングし、そのモデルを ACI/AKS にデプロイするため。
- Azure Machine Learning SDK を使用して自動機械学習機能と一緒に。
- Azure Machine Learning パイプラインからのコンピューティング先として。
Databricks クラスターをセットアップする
Databricks クラスターを作成します。 一部の設定は、Databricks に自動化された機械学習用の SDK をインストールする場合にのみ適用されます。
クラスターの作成には数分かかります。
次の設定を使用します。
| 設定 | 適用対象 | 値 |
|---|---|---|
| クラスター名 | 常時 | yourclustername |
| Databricks Runtime のバージョン | 常時 | 9.1 LTS |
| Python バージョン | 常時 | 3 |
| worker の種類 (同時実行反復処理の最大数を決定) |
自動化された ML のみ |
メモリ最適化 VM 優先 |
| ワーカー | 常時 | 2 以上 |
| 自動スケールの有効化 | 自動化された ML のみ |
オフ |
クラスターが実行中になるまで待機してから、次に進んでください。
Azure Machine Learning SDK を Databricks に追加する
クラスターが実行されたら、ライブラリを作成して、適切な Azure Machine Learning SDK パッケージをクラスターにアタッチします。
自動 ML を使用するには、AutoML を含む Azure Machine Learning SDK の追加に関するセクションに進んでください。
ライブラリを保存する現在のワークスペース フォルダーを右クリックします。 [作成]>[ライブラリ] の順に選択します。
ヒント
前のバージョンの SDK がある場合は、クラスターのインストール済みライブラリでその選択を解除し、ごみ箱に移動します。 新しいバージョンの SDK をインストールし、クラスターを再起動します。 再起動後に問題がある場合は、クラスターをデタッチし、再アタッチします。
次のオプションを選択します (他の SDK のインストールはサポートされていません)
SDK パッケージ extras ソース PyPi 名 Databricks 用 Python Egg または PyPI のアップロード azureml-sdk[databricks] 警告
他の SDK extras はインストールできません。 [
databricks] オプションのみを選択します。- [すべてのクラスターに自動的にアタッチする] は選択しないでください。
- クラスター名の横にある [アタッチ] を選択します。
状態が [アタッチ済み] に変わるまで、エラーを監視します。これには数分かかる場合があります。 このステップが失敗した場合は、次の操作を行います。
次のようにして、クラスターを再起動してみます。
- 左側のウィンドウで、 [クラスター] を選択します。
- テーブルでクラスター名を選択します。
- [ライブラリ] タブで [再起動] を選択します。
インストールが成功すると次のようになります。
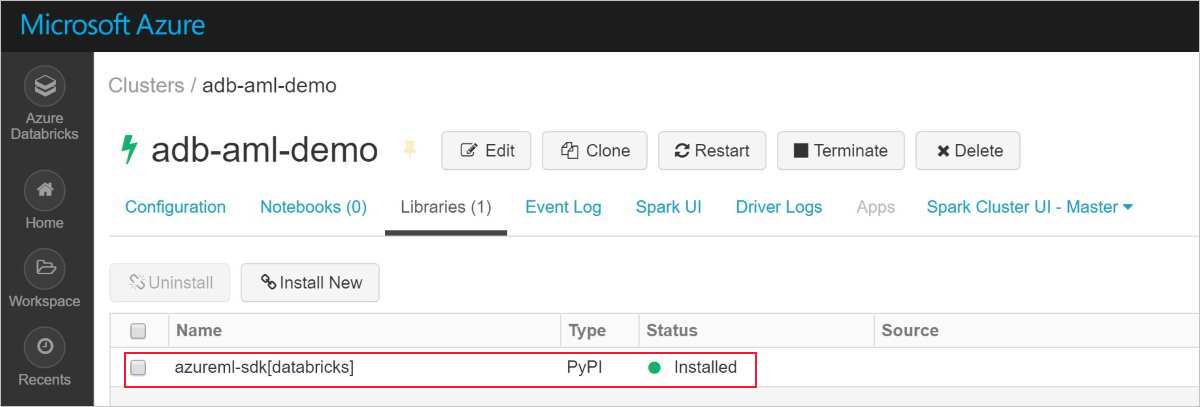
AutoML を含む Azure Machine Learning SDK を Databricks に追加する
クラスターが Databricks Runtime 7.3 LTS (ML "以外") で作成された場合は、ノートブックの最初のセルで次のコマンドを実行して Azure Machine Learning SDK をインストールします。
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
AutoML 構成の設定
AutoML 構成では、Azure Databricks を使用するときに次のパラメーターを追加してください。
max_concurrent_iterationsは、ご利用のクラスター内のワーカー ノードの数に基づきます。spark_context=scは、既定の Spark コンテキストに基づきます。
Azure Databricks と連携動作する ML ノートブック
実際に試してみましょう。
サンプル ノートブックがたくさんありますが、Azure Databricks で動作するのはこれらのサンプル ノートブックのみです。
これらのサンプルは、ワークスペースから直接インポートしてください。 次を参照してください。
トラブルシューティング
Databricks での自動化された機械学習の実行をキャンセルする:自動化された機械学習機能を Azure Databricks で使用しているときに、実行をキャンセルして新しい実験の実行を開始するには、Azure Databricks クラスターを再起動してください。
Databricks での自動化された機械学習の 10 回を超える繰り返し: 自動化された機械学習の設定で、繰り返し回数が 10 回を超えている場合は、実行を送信するときに
show_outputをFalseに設定します。Azure Machine Learning SDK 用の Databricks ウィジェットと自動化された機械学習:Azure Machine Learning SDK ウィジェットは、Databricks ノートブックではサポートされていません。この理由は、ノートブックが HTML ウィジェットを解析できないからです。 Azure Databricks のノートブック セルで次の Python コードを使用することにより、portal でウィジェットを表示することができます。
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))パッケージをインストールする際の失敗
追加のパッケージがインストールされていると、Azure Databricks で Azure Machine Learning SDK のインストールが失敗します。
psutilのようなパッケージでは、競合が発生することがあります。 インストール エラーを回避するには、ライブラリ バージョンを止めてパッケージをインストールします。 この問題は Databricks に関連したもので、Azure Machine Learning SDK には関連はありません。 他のライブラリでもこの問題が発生する場合があります。 例:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0別の方法として、Python ライブラリでインストールの問題が発生し続けている場合は、初期化スクリプトを使用することができます。 この方法は、公式にはサポートされていません。 詳細については、「Cluster-scoped init scripts」を参照してください。
インポート エラー:
pandas._libs.tslibsから名前Timedeltaをインポートできません:自動機械学習を使用するときにこのエラーが表示される場合は、notebook で次の 2 行を実行します。%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4インポート エラー:'pandas.core.indexes' という名前のモジュールはありません:自動化された機械学習を使用しているときにこのエラーが表示される場合は、以下を実行します。
次のコマンドを実行して、Azure Databricks クラスターに 2 つのパッケージをインストールします。
scikit-learn==0.19.1 pandas==0.22.0クラスターをデタッチし、次にクラスターをノートブックに再アタッチします。
これらの手順で問題が解決しない場合は、クラスターを再起動してみてください。
FailToSendFeather:Azure Databricks クラスター上のデータの読み取り時に
FailToSendFeatherエラーが表示された場合は、次の解決策を参照してください。azureml-sdk[automl]パッケージを最新バージョンにアップグレードします。azureml-dataprepバージョン 1.1.8 以降を追加します。pyarrowバージョン 0.11 以降を追加します。
次のステップ
- MNIST データセットを使用して Azure Machine Learning でモデルをトレーニングおよびデプロイします。
- Azure Machine Learning SDK for Python のリファレンスに関するページを参照してください。