バッチ エンドポイントのジョブと入力データを作成する
Azure Machine Learning でバッチ エンドポイントを使用すると、大量の入力データに対して長いバッチ操作を実行できます。 データは、異なるリージョン間など、さまざまな場所に配置できます。 特定の種類のバッチ エンドポイントでは、リテラル パラメーターを入力として受け取ることもできます。
この記事では、バッチ エンドポイントのパラメーター入力を指定し、デプロイ ジョブを作成する方法について説明します。 このプロセスでは、データ資産、データ ストア、ストレージ アカウント、ローカル ファイルなど、さまざまなソースからのデータの操作がサポートされています。
前提条件
バッチ エンドポイントとデプロイ。 これらのリソースを作成するには、「Azure Machine Learning にバッチ デプロイで MLflow モデルをデプロイする」を参照してください。
バッチ エンドポイント デプロイを実行するためのアクセス許可。 AzureML データ科学者、共同作成者、所有者の各ロールを使用して、デプロイを実行できます。 カスタム役割の定義に必要な特定のアクセス許可を確認するには、「バッチ エンドポイントでの認可」を参照してください。
エンドポイントを呼び出す資格情報。 詳細については、「認証の確立」を参照してください。
エンドポイントがデプロイされているコンピューティング クラスターからの入力データに対する読み取りアクセス。
ヒント
特定の状況では、資格情報のないデータ ストアまたは外部の Azure Storage アカウントをデータ入力として使用する必要があります。 これらのシナリオでは、コンピューティング クラスターのマネージド ID がストレージ アカウントのマウントに使用されるため、データ アクセス用にコンピューティング クラスターを構成してください。 ジョブ (呼び出し元) の ID は基になるデータの読み取りに使用されるため、引き続ききめ細かいアクセスの制御が可能です。
認証を確立する
エンドポイントを呼び出すには、有効な Microsoft Entra トークンが必要です。 エンドポイントを呼び出すと、Azure Machine Learning によって、トークンに関連付けられている ID の下にバッチ デプロイ ジョブが作成されます。
- Azure Machine Learning CLI (v2) または Azure Machine Learning SDK for Python (v2) を使用してエンドポイントを呼び出す場合、Microsoft Entra トークンを手動で取得する必要はありません。 サインイン時に、システムによってユーザー ID が認証されます。 また、トークンが取得されて渡されます。
- REST API を使用してエンドポイントを呼び出す場合は、トークンを手動で取得する必要があります。
次の手順で説明するように、呼び出しには独自の資格情報を使用できます。
Azure CLI を使用して、対話型認証またはデバイス コード認証でサインインします。
az login
さまざまな種類の資格情報の詳細については、「さまざまな種類の資格情報を使用してジョブを実行する方法」を参照してください。
基本的なジョブを作成する
バッチ エンドポイントからジョブを作成するには、エンドポイントを呼び出します。 呼び出しは、Azure Machine Learning CLI、Azure Machine Learning SDK for Python、または REST API 呼び出しを使用して実行できます。
次の例は、処理用の単一の入力データ フォルダーを受け取るバッチ エンドポイントの呼び出しの基本を示しています。 さまざまな入力と出力を呼び出す例については、「入力と出力について」を参照してください。
バッチ エンドポイントで invoke 操作を使用します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
特定のデプロイを呼び出す
バッチ エンドポイントは、同じエンドポイントで複数のデプロイをホストできます。 ユーザーが特に指定しない限り、既定のエンドポイントが使われます。 次の手順を使用して、使用するデプロイを変更できます。
引数 --deployment-name または -d を使ってデプロイの名前を指定します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
ジョブのプロパティを構成する
一部のジョブ プロパティは、呼び出し時に構成できます。
Note
現時点では、パイプライン コンポーネントのデプロイを使用して、バッチ エンドポイントでのみジョブのプロパティを構成できます。
実験名を構成する
実験名を構成するには、次の手順を使用します。
引数 --experiment-name を使って実験の名前を指定します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
入力と出力について
バッチ エンドポイントは、コンシューマーがバッチ ジョブの作成に使用できる永続的な API を提供します。 同じインターフェイスを使用して、デプロイで想定される入力と出力を指定できます。 入力を使用して、ジョブを実行するためにエンドポイントに必要な情報を渡します。
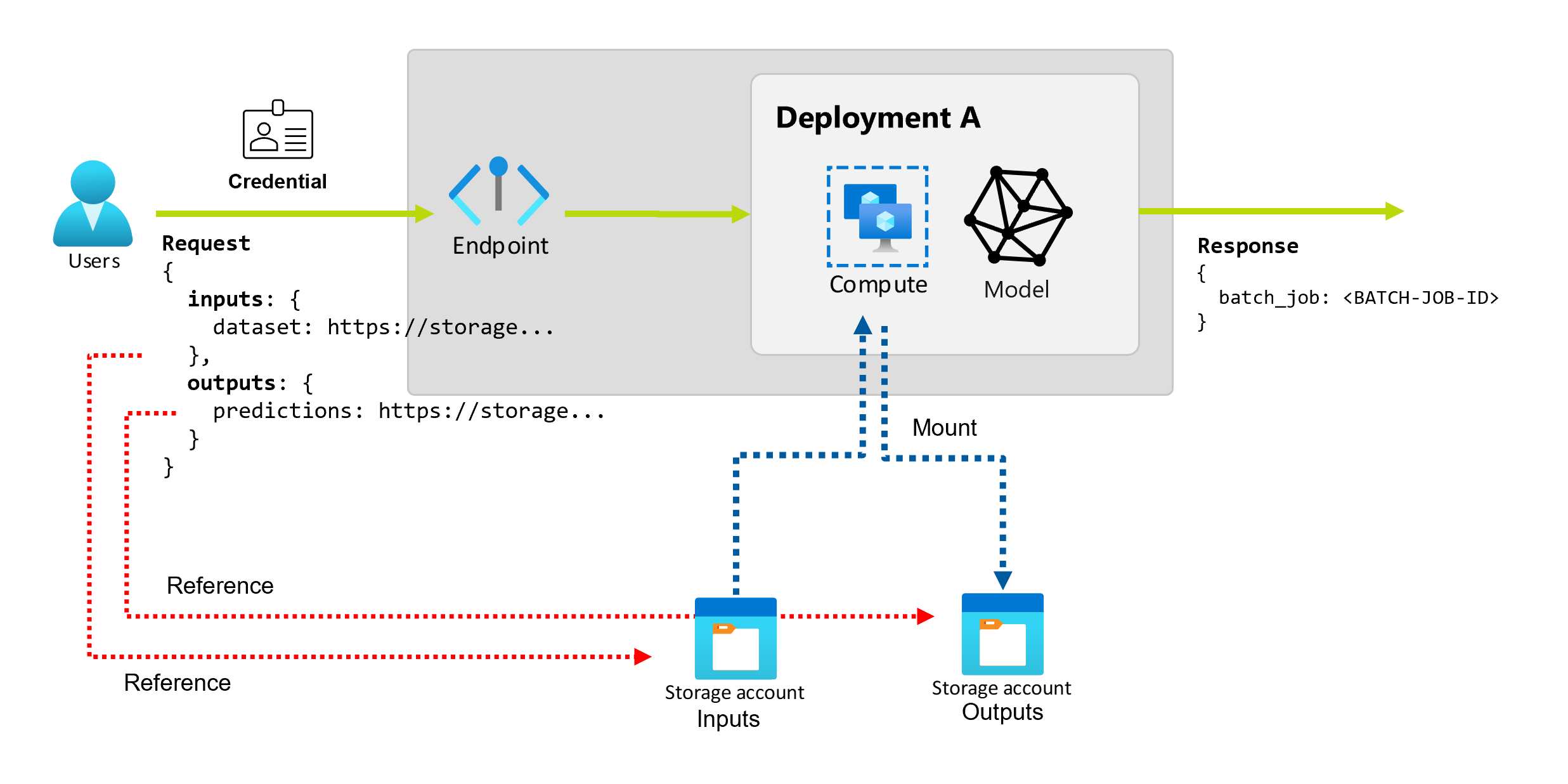
バッチ エンドポイントは次の 2 種類の入力をサポートします。
入力と出力の数と種類は、バッチ デプロイの種類によって異なります。 モデル デプロイは、常に 1 つのデータ入力を必要とし、1 つのデータ出力を生成します。 リテラル入力は、モデル デプロイではサポートされていません。 これに対し、パイプライン コンポーネント デプロイでは、エンドポイントを構築するためのより一般的なコンストラクトが提供されます。 パイプライン コンポーネント デプロイでは、任意の数のデータ入力、リテラル入力、出力を指定できます。
次の表は、バッチ デプロイの入力と出力をまとめたものです。
| デプロイの種類 | 入力の数 | サポートされている入力の種類 | 出力の数 | サポートされている出力の種類 |
|---|---|---|---|---|
| モデル デプロイ | 1 | データ入力 | 1 | データ出力 |
| パイプライン コンポーネント デプロイ | 0-N | データ入力とリテラル入力 | 0-N | データ出力 |
ヒント
入力と出力は常に名前付きです。 それぞれの名前は、データを識別し、呼び出し中に値を渡すためのキーとして機能します。 モデル デプロイでは、常に 1 つの入力と出力が必要であるため、モデル デプロイでの呼び出し中に名前は無視されます。
sales_estimation のように、ユース ケースを最もよく表す名前を割り当てることができます。
データ入力を調べる
データ入力とは、データが配置されている場所を指す入力のことです。 バッチ エンドポイントは通常、大量のデータを消費するため、呼び出し要求の一部として入力データを渡すことはできません。 代わりに、バッチ エンドポイントがデータを検索する場所を指定します。 パフォーマンスを向上させるために、入力データはターゲット コンピューティング インスタンスにマウントされ、ストリーミングされます。
バッチ エンドポイントは、次の種類のストレージにあるファイルを読み取ることができます。
-
Azure Machine Learning データ資産。フォルダー (
uri_folder)、ファイル (uri_file) の種類などです。 - Azure Machine Learning データ ストア。Azure Blob Storage、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2 などです。
- Blob Storage、Data Lake Storage Gen1、Data Lake Storage Gen2 などの Azure Storage アカウント。
- Azure Machine Learning CLI または Azure Machine Learning SDK for Python を使用してエンドポイントを呼び出す場合は、ローカル データ フォルダーとファイル。 ただし、ローカル データは、Azure Machine Learning ワークスペースの既定のデータ ストアにアップロードされます。
重要
非推奨の通知: 型 FileDataset (V1) のデータ資産は非推奨で、今後廃止される予定です。 この機能に依存する既存のバッチ エンドポイントは引き続き機能します。 ただし、次を使用して作成されたバッチ エンドポイント内の V1 データセットはサポートされません。
- 一般公開されている Azure Machine Learning CLI v2 のバージョン (2.4.0 以降)。
- 一般公開されている REST API のバージョン (2022-05-01 以降)。
リテラル入力を調べる
リテラル入力とは文字列、数値、ブール値など、呼び出し時に表現および解決できる入力のことです。 通常は、リテラル入力を使用して、パイプライン コンポーネント デプロイの一部としてエンドポイントにパラメーターを渡します。 バッチ エンドポイントでは、次のリテラル型がサポートされています。
stringbooleanfloatinteger
リテラル入力は、パイプライン コンポーネントのデプロイでのみサポートされます。 リテラル エンドポイントを指定する方法を確認するには、「リテラル入力を使ってジョブを作成する」を参照してください。
データ出力を調べる
データ出力とは、バッチ ジョブの結果が配置される場所のことです。 各出力には識別可能な名前が付けられ、Azure Machine Learning によって、名前付き出力のそれぞれに一意のパスが自動的に割り当てられます。 必要に応じて、別のパスを指定できます。
重要
バッチ エンドポイントでは、Blob Storage データ ストアでの出力の書き込みのみがサポートされます。 階層型名前空間が有効なストレージ アカウント (Data Lake Storage Gen2 など) に書き込む必要がある場合、サービスは完全に互換性があるため、ストレージ サービスを Blob Storage データ ストアとして登録できます。 このように、バッチ エンドポイントからの出力を Data Lake Storage Gen2 に書き込むことができます。
データ入力を使ってジョブを作成する
次の例は、データ資産、データ ストア、Azure Storage アカウントからデータ入力を取得するときにジョブを作成する方法を示しています。
データ資産からの入力データを使用する
Azure Machine Learning のデータ資産 (以前のデータセット) は、ジョブへの入力としてサポートされています。 Azure Machine Learning の登録済みデータ資産に保存されている入力データを使用する、バッチ エンドポイント ジョブを実行するには、次の手順に従います。
警告
型 Table (MLTable) のデータ資産は、現在サポートされていません。
データ資産を作成します。 この例では、複数の CSV ファイルを含むフォルダーで構成されています。 バッチ エンドポイントを使用して、ファイルを並列で処理します。 データが既にデータ資産として登録されている場合は、この手順をスキップできます。
heart-data.yml という名前の YAML ファイルにデータ資産定義を作成します。
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataデータ資産を作成します。
az ml data create -f heart-data.yml
入力を設定します。
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)データ資産 ID は
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>形式です。エンドポイントを実行します。
--set引数を使用して入力を指定します。 最初に、データ資産の名前のハイフンをアンダースコア文字に置き換えます。 キーに使用できるのは、英数字とアンダースコア文字だけです。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDモデル デプロイにサービスを提供するエンドポイントの場合、
--input引数を使用してデータ入力を指定できます。これは、モデル デプロイで必要なデータ入力が常に 1 つだけであるためです。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_ID複数の入力を指定する場合、引数
--setによって長いコマンドが生成される傾向があります。 このような場合は、ファイル内の入力を一覧表示し、エンドポイントを呼び出すときにファイルを参照できます。 たとえば、次の行を含む inputs.yml という名前の YAML ファイルを作成できます。inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1次に、
--file引数を使用して入力を指定する次のコマンドを実行できます。az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
データ ストアからの入力データを使用する
バッチ デプロイ ジョブは、Azure Machine Learning に登録済みのデータ ストア内のデータを直接参照できます。 この例では、まず、Azure Machine Learning ワークスペース内のデータ ストアにいくつかのデータをアップロードします。 その後、そのデータに対してバッチ デプロイを実行します。
この例では、既定のデータ ストアを使用しますが、別のデータ ストアを使用できます。 Azure Machine Learning ワークスペースでは、既定の BLOB データ ストアの名前は workspaceblobstore です。 次の手順で別のデータ ストアを使用する場合は、workspaceblobstore を優先するデータ ストアの名前に置き換えます。
サンプル データをデータ ストアにアップロードします。 サンプル データは、azureml-examples リポジトリで入手できます。 データは、そのリポジトリの sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data フォルダーにあります。
- Azure Machine Learning スタジオで、既定の BLOB データ ストアのデータ資産ページを開き、その BLOB コンテナーの名前を検索します。
- Azure Storage Explorer や AzCopy などのツールを使用して、そのコンテナー内の heart-disease-uci-unlabeled という名前のフォルダーにサンプル データをアップロードします。
入力情報を設定します。
ファイル パスを
INPUT_PATH変数に配置します。DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"pathsフォルダーが入力パスの一部であることがわかります。 この形式は、後続の値がパスであることを示します。エンドポイントを実行します。
--set引数を使用して入力を指定します。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHモデル デプロイにサービスを提供するエンドポイントの場合、
--input引数を使用してデータ入力を指定できます。これは、モデル デプロイで必要なデータ入力が常に 1 つだけであるためです。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folder複数の入力を指定する場合、引数
--setによって長いコマンドが生成される傾向があります。 このような場合は、ファイル内の入力を一覧表示し、エンドポイントを呼び出すときにファイルを参照できます。 たとえば、次の行を含む inputs.yml という名前の YAML ファイルを作成できます。inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>データがファイル内にある場合は、代わりに入力に
uri_file型を使用します。次に、
--file引数を使用して入力を指定する次のコマンドを実行できます。az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Azure Storage アカウントからの入力データを使用する
Azure Machine Learning バッチ エンドポイントでは、Azure Storage アカウント内のクラウドの場所 (パブリックとプライベートの両方) からデータを読み取ることができます。 ストレージ アカウント内のデータを使用してバッチ エンドポイント ジョブを実行するには、次の手順を使用します。
ストレージ アカウントからデータを読み取るために必要な追加の構成の詳細については、「データ アクセス用にコンピューティング クラスターを構成する」を参照してください。
入力を設定します。
INPUT_DATA変数を設定します。INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"データがファイル内にある場合は、次のような形式を使用して入力パスを定義します。
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"エンドポイントを実行します。
--set引数を使用して入力を指定します。az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAモデル デプロイにサービスを提供するエンドポイントの場合、
--input引数を使用してデータ入力を指定できます。これは、モデル デプロイで必要なデータ入力が常に 1 つだけであるためです。az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folder複数の入力を指定する場合、
--set引数によって長いコマンドが生成される傾向があります。 このような場合は、ファイル内の入力を一覧表示し、エンドポイントを呼び出すときにファイルを参照できます。 たとえば、次の行を含む inputs.yml という名前の YAML ファイルを作成できます。inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data次に、
--file引数を使用して入力を指定する次のコマンドを実行できます。az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlデータがファイル内にある場合は、データ入力に inputs.yml ファイルの
uri_file型を使用します。
リテラル入力を使ってジョブを作成する
パイプライン コンポーネントのデプロイでは、リテラル入力を受け取ることができます。 基本的なパイプラインを含むバッチ デプロイの例については、「バッチ エンドポイントを使用してパイプラインをデプロイする方法」を参照してください。
次の例は、名前が score_mode、型が string、値が append の入力を指定する方法を示します。
inputs.yml という名前のような YAML ファイルに入力を配置します。
inputs:
score_mode:
type: string
default: append
--file 引数を使用して入力を指定する次のコマンドを実行します。
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
--set 引数を使用して、型と既定値を指定することもできます。 ただし、この方法では、複数の入力を指定すると、長いコマンドが生成される傾向があります。
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
データ出力を使ってジョブを作成する
次の例は、score という名前の出力の場所を変更する方法を示しています。 完全にするために、この例では heart_data という名前の入力も構成します。
この例では、既定のデータ ストア workspaceblobstore を使用します。 ただし、Blob Storage アカウントであれば、ワークスペース内の他の任意のデータ ストアを使用できます。 別のデータ ストアを使用する場合は、次の手順の workspaceblobstore を優先するデータ ストアの名前に置き換えます。
データ ストアの ID を取得します。
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')データ ストア ID は
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore形式です。データ出力を作成します。
inputs-and-outputs.yml という名前のファイルで入力と出力の値を定義します。 出力パスでデータ ストア ID を使用します。 完全にするために、データ入力も定義します。
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathNote
pathsフォルダーが出力パスの一部であることがわかります。 この形式は、後続の値がパスであることを示します。デプロイを実行します。
--file引数を使用して、入力と出力の値を指定します。az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml