予測モデルの推論と評価
この記事では、予測タスクにおけるモデルの推論と評価に関連する概念について説明します。 AutoML で予測モデルをトレーニングする手順と例については、「SDK と CLI で時系列予測モデルをトレーニングするために AutoML を設定する」を参照してください。
AutoML を使用して最適なモデルをトレーニングして選択したら、次の手順で予測を生成します。 次に、可能であれば、それらの精度を、トレーニング データから提供されるテスト セットで評価します。 自動機械学習で予測モデルの評価を設定して実行する方法については、トレーニング、推論、評価のオーケストレーションに関するページを参照してください。
推論シナリオ
機械学習で、"推論" とは、トレーニングで使用されていない新しいデータのモデル予測を生成するプロセスです。 データは時間に依存するため、予測で予測を生成する方法は複数あります。 最も簡単なシナリオは、推論期間がトレーニング期間の直後に続き、予測ホライズンまで予測を生成する場合です。 次の図にこのシナリオを示します。
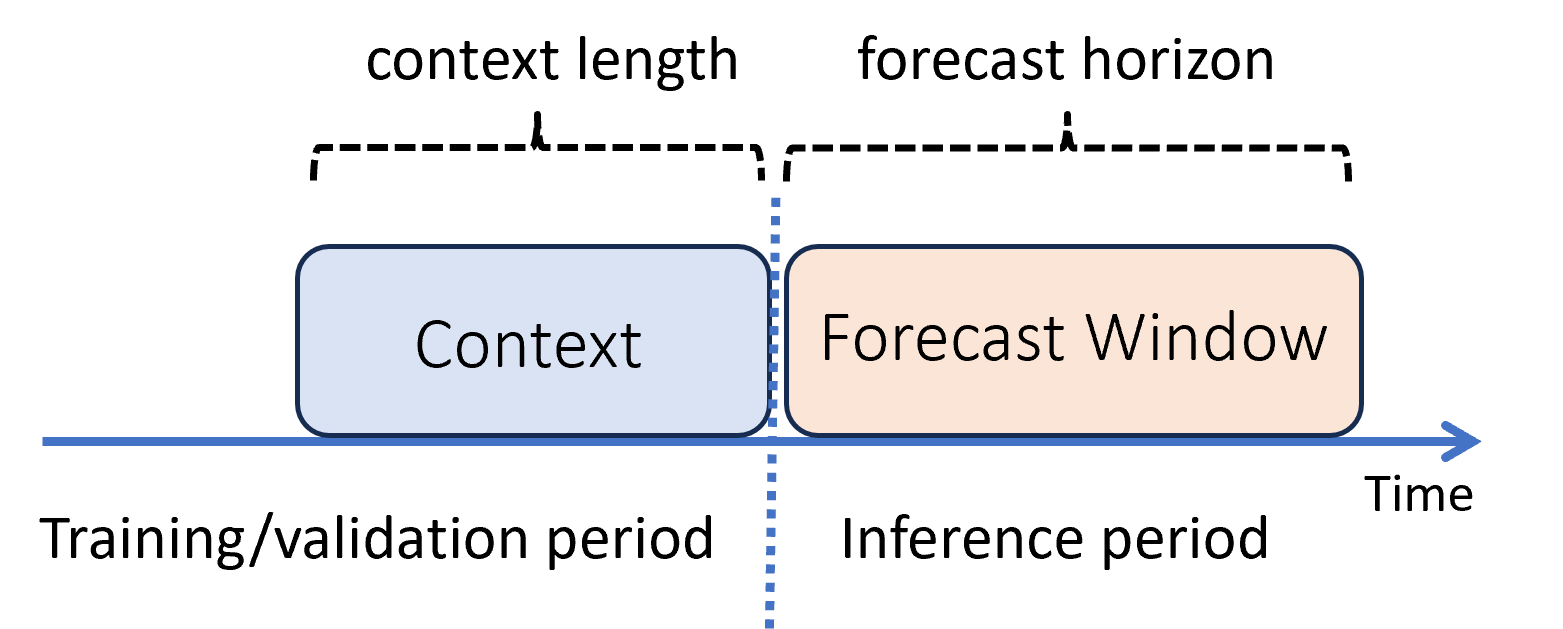
この図は、2 つの重要な推論パラメーターを示しています。
- "コンテキストの長さ" は、モデルで予測を行う場合に必要となる履歴の量です。
- "予測ホライズン" は、予測器が時間的にどのぐらい先まで予測するようにトレーニングされるかということです。
予測モデルでは、通常、何らかの履歴情報 ("コンテキスト") を使用して、予測ホライズンまでの予測を行います。 コンテキストがトレーニング データの一部である場合、AutoML では予測を行うにあたり必要なものを保存します。 明示的に指定する必要はありません。
より複雑な他の推論シナリオが 2 つあります。
- 予測ホライズンよりも将来の予測を生成する
- トレーニング期間と推論期間にギャップがある場合に予測を取得する
次のサブセクションでは、これらのケースについて説明します。
予測ホライズンを超えて予測する: 再帰的予測
ホライズンを超えた予測が必要な場合、AutoML は推論期間にわたってモデルを再帰的に適用します。 モデルからの予測は、後続の予測ウィンドウに対する予測を生成するための "入力として提供" されます。 次の図に簡単な例を示します。
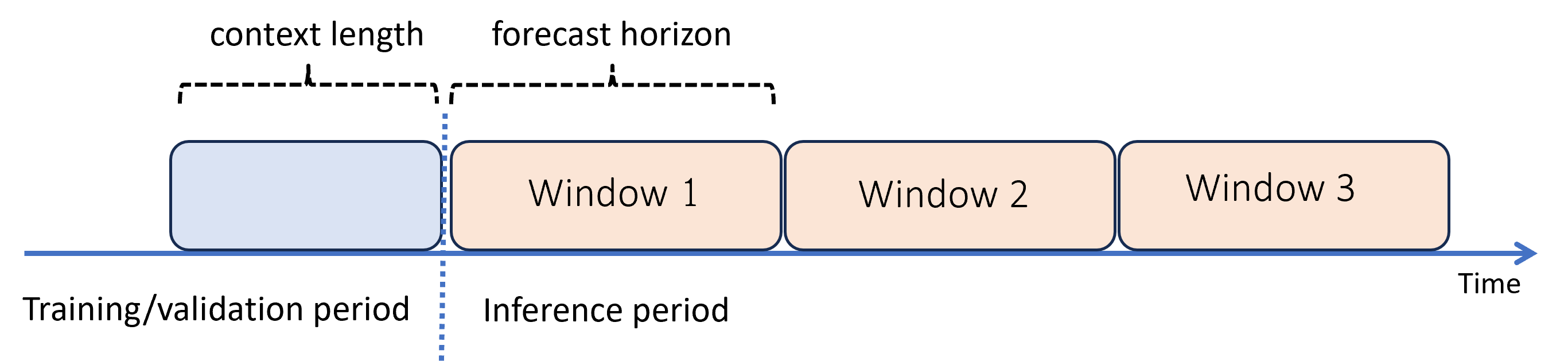
ここで、機械学習では、ホライズンの 3 倍の長さの期間に対して予測を生成します。 1 つのウィンドウからの予測を、次のウィンドウ用のコンテキストとして使用します。
警告
再帰的予測ではモデリング エラーが発生します。 元の予測ホライズンから遠くなるほど予測の精度は低下します。 ホライズンをより長くして再トレーニングすると、より正確なモデルが見つかることがあります。
トレーニング期間と推論期間にギャップがある場合の予測
モデルをトレーニングした後に、それを使用して、トレーニング中にまだ利用できなかった新しい観測値から予測を行うとします。 この場合、トレーニング期間と推論期間に時間差があります。
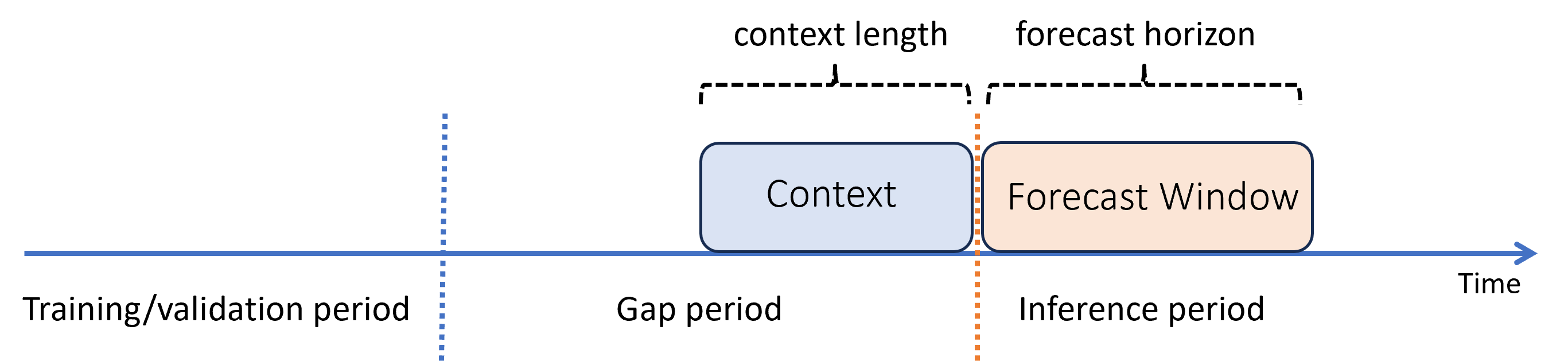
AutoML ではこの推論シナリオがサポートされますが、図に示すように、ギャップ期間にコンテキスト データを指定する必要があります。 "推論コンポーネント" に渡される予測データには、特徴量の値、ギャップ内で観測されるターゲット値、推論期間内のターゲットの欠落値つまり NaN 値が必要です。 次の表はこのパターンの例を示しています。
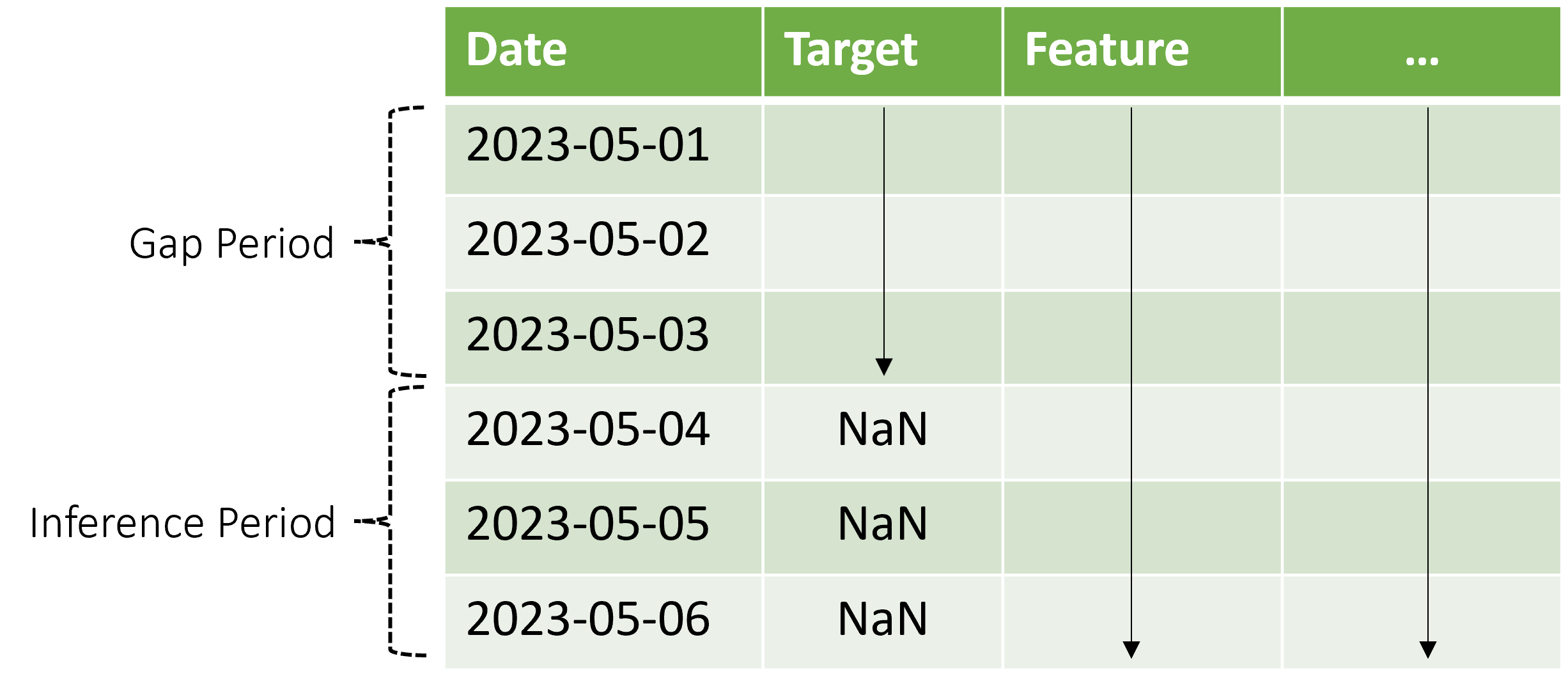
ターゲットと特徴量の既知の値は 2023-05-01 から 2023-05-03 に対して提供されます。 2023-05-04 以降のターゲット値が欠落している場合は、推論期間がその日付から始まることを示します。
AutoML では、新しいコンテキスト データを使用して、ラグやその他のルックバック機能を更新し、さらに内部状態を維持する ARIMA などのモデルを更新します。 この操作では、モデル パラメーターの更新や再適合は行いません。
モデルの評価
"評価" とは、トレーニング データから提供されたテスト セットに対して予測を生成し、モデル デプロイの決定を導くメトリックをこれらの予測から計算するプロセスです。 したがって、モデル評価に適した推論モードとして、ローリング予測が挙げられます。
予測モデルを評価するためのベスト プラクティスの手順では、トレーニングされた予測機能をテスト セット全体で時間的にロール フォワードし、複数の予測ウィンドウでエラー メトリックを平均します。 この手順は、"バックテスト" と呼ばれることがあります。 理想的には、評価のテスト セットは、モデルの予測期間と比べて長くなります。 そうしないと、予測エラーの推定値は統計的にノイズが多くなり、信頼性が低くなる可能性があります。
次の図は、3 つの予測ウィンドウを含む簡単な例を示しています。
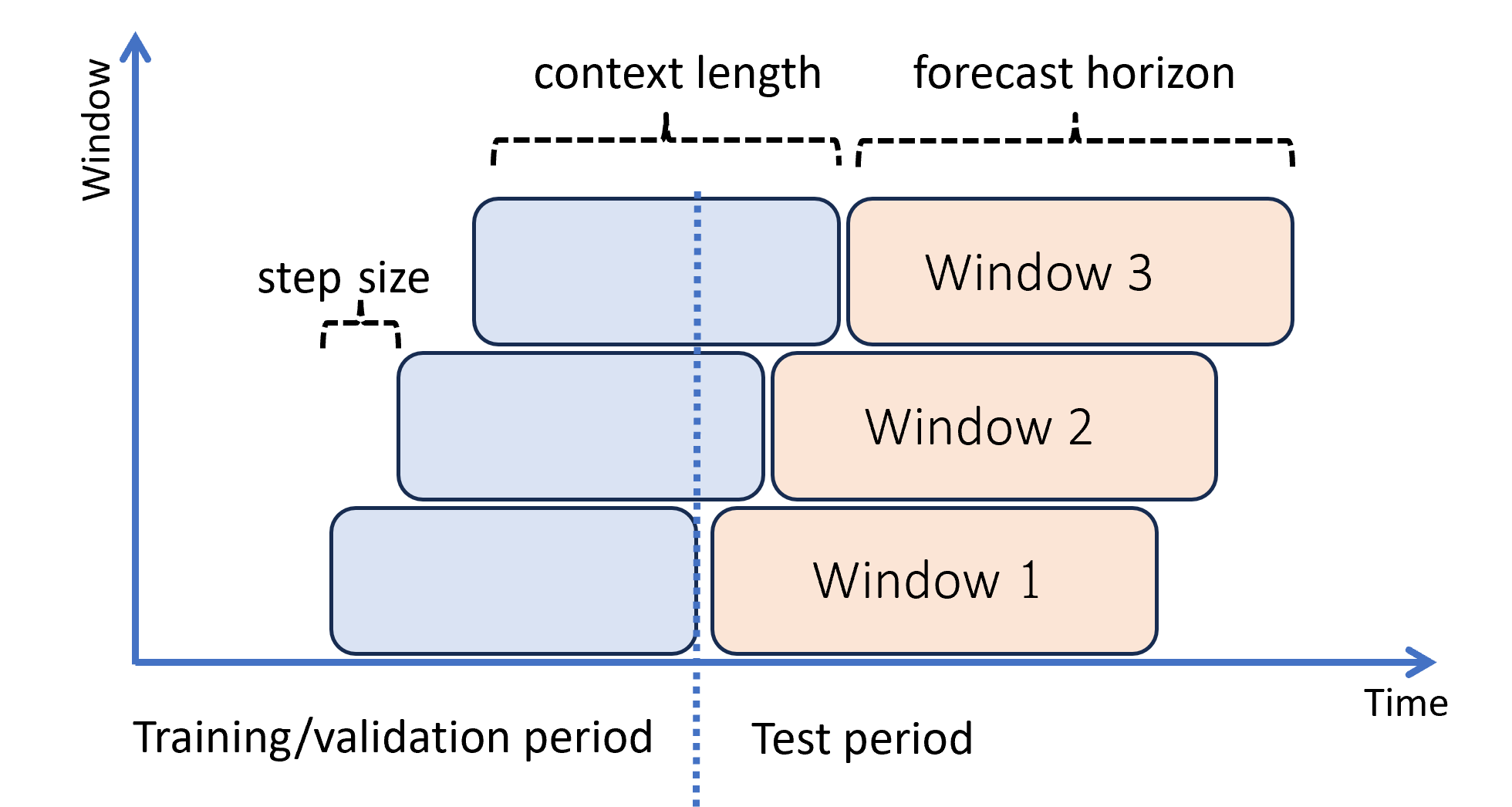
この図は、次の 3 つのローリング評価パラメーターを示しています。
- "コンテキストの長さ" は、モデルで予測を行う場合に必要となる履歴の量です。
- "予測ホライズン" は、予測器が時間的にどのぐらい先まで予測するようにトレーニングされるかということです。
- "ステップ サイズ" は、テスト セットの各繰り返しでローリング ウィンドウが時間的にどのぐらい先まで進むかを示します。
コンテキストは予測ウィンドウと共に進みます。 テスト セットからの実際の値が現在のコンテキスト ウィンドウに収まる場合、それらは予測を行うために使用されます。 特定の予測ウィンドウに使用される実際の値の最新の日付は、ウィンドウの始点と呼ばれます。 次の表は、ホライズンが 3 日、ステップ サイズが 1 日である 3 ウィンドウのローリング予測からの出力例を示しています。
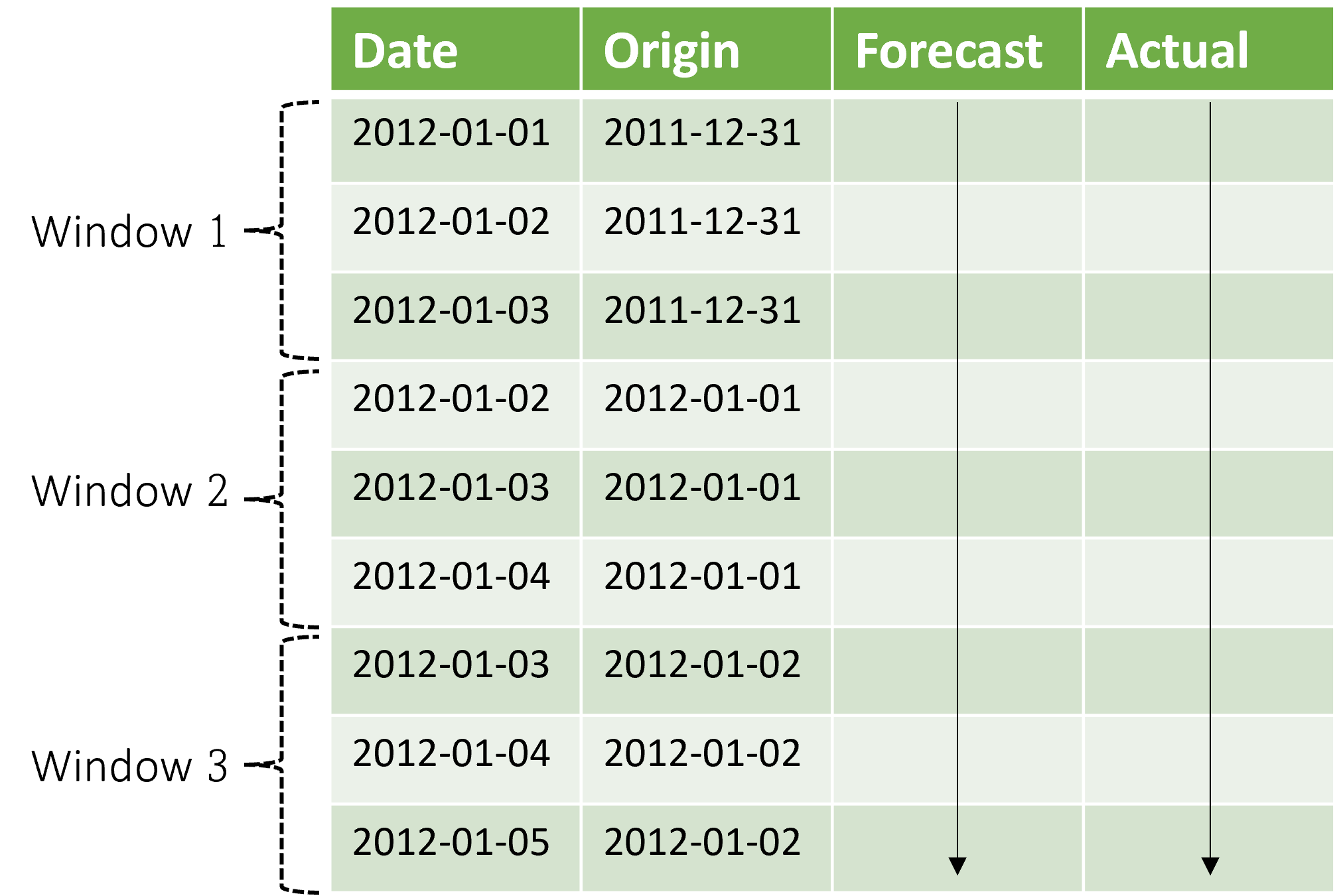
このような表を使用することで、予測と実績を視覚化して比較し、必要な評価メトリックを計算できます。 AutoML パイプラインでは、推論コンポーネントを使用してテスト セットでローリング予測を生成できます。
注意
テスト期間が予測ホライズンと同じ長さの場合、ローリング予測では、ホライズンまでの予測を 1 つのウィンドウで表示します。
評価メトリック
通常、評価の概要またはメトリックの選択は、特定のビジネス シナリオに左右されます。 いくつかの一般的な選択肢を次に示します。
- モデルによってキャプチャされるデータの特定の動態をチェックするために観察されるターゲット値と予測値のプロット
- 実際の値と予測値の平均絶対誤差率 (MAPE)
- 実際の値と予測値の二乗平均平方根誤差 (RMSE)。場合によっては正規化を伴う
- 実際の値と予測値の平均絶対誤差 (MAE)。場合によっては正規化を伴う
ビジネス シナリオに応じて、他にも多くの可能性があります。 推論結果またはローリング予測から評価メトリックを計算するために、独自の後処理ユーティリティの作成が必要になる場合があります。 メトリックの詳細については、「回帰/予測メトリック」を参照してください。
関連するコンテンツ
- 時系列予測モデルをトレーニングするように AutoML を設定する方法の詳細について確認します。
- AutoML が機械学習を使用して予測モデルを構築する方法について確認します。
- AutoML での予測に関するよくある質問への回答を確認します。