Azure HDInsight で Apache Ambari を使用して Apache Hive を最適化する
Apache Ambari は、HDInsight クラスターを管理および監視するための Web インターフェイスです。 Ambari Web UI の概要については、「Ambari Web UI を使用した HDInsight クラスターの管理」を参照してください。
以下のセクションでは、Apache Hive の全体的なパフォーマンスを最適化するための構成オプションについて説明します。
- Hive 構成パラメーターを変更するには、[Services](サービス) サイドバーで [Hive] を選択します。
- [Configs](構成) タブに移動します。
Hive 実行エンジンを設定する
Hive は、Apache Hadoop MapReduce と Apache TEZ の 2 つの実行エンジンを提供します。 Tez は MapReduce より高速です。 HDInsight Linux クラスターでは、既定の実行エンジンとして Tez を使用します。 実行エンジンを変更するには、次の手順を実行します。
Hive の [Configs](構成) タブで、フィルター ボックスに「execution engine」と入力します。
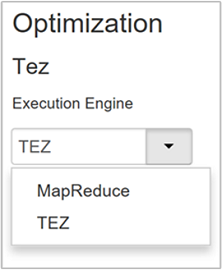
[Optimization](最適化) プロパティの既定値は Tez です。
マッパーを調整する
Hadoop では、1 つのファイルを複数のファイルに分割 ( "マップ" ) し、分割されたファイルの並列処理を試みます。 マッパーの数は分割数によって異なります。 次の 2 つの構成パラメーターは、Tez 実行エンジンの分割数を制御します。
tez.grouping.min-size:グループ化された分割のサイズの下限であり、既定値は 16 MB (16,777,216 バイト) です。tez.grouping.max-size:グループ化された分割のサイズの上限であり、既定値は 1 GB (1,073,741,824 バイト) です。
パフォーマンスの目安として、これらのパラメーターの両方を減らすと待機時間が改善され、増やすとスループットが向上します。
たとえば、128 MB のデータ サイズに対して 4 つのマッパー タスクを設定するには、これらのパラメーターをそれぞれ 32 MB (33,554,432バイト) に設定します。
制限パラメーターを変更するには、Tez サービスの [Configs](構成) タブに移動します。 [General]\(全般\) パネルを展開し、
tez.grouping.max-sizeパラメーターとtez.grouping.min-sizeパラメーターを見つけます。両方のパラメーターを 33,554,432 バイト(32 MB) に設定します。

これらの変更は、サーバーのすべての Tez ジョブに影響します。 最適な結果を得るために、適切なパラメーター値を選択してください。
レジューサーを調整する
Apache ORC と Snappy は、どちらもハイ パフォーマンスを提供します。 ただし、Hive は既定でレジューサーの数が少なすぎるため、ボトルネックが発生する可能性があります。
たとえば、入力データ サイズが 50 GB であるとします。 このデータを ORC 形式にして Snappy で圧縮すると 1 GB になります。 Hive では、(マッパーに入力されたバイト数 / hive.exec.reducers.bytes.per.reducer) で必要なレジューサーの数を見積もります。
既定の設定を使用した場合、この例は 4 レジューサーになります。
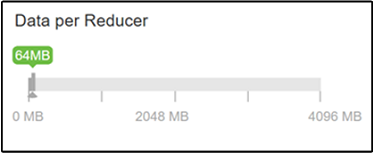
hive.exec.reducers.bytes.per.reducer パラメーターは、レジューサーごとに処理されるバイト数を指定します。 既定値は 64 MB です。 この値を調整して並列処理を増やすと、パフォーマンスが向上する場合があります。 また、値を小さくしすぎると、生成されるレジューサーが多すぎ、パフォーマンスに悪影響を及ぼす可能性があります。 このパラメーターは、特定のデータ要件、圧縮設定、その他の環境要因に基づきます。
パラメーターを変更するには、Hive の [Configs](構成) タブに移動し、[Settings](設定) ページで [Data per Reducer](レジューサーごとのデータ) パラメーターを見つけます。
[Edit](編集) を選択して値を 128 MB (134,217,728 バイト) に変更し、Enter キーを押して保存します。
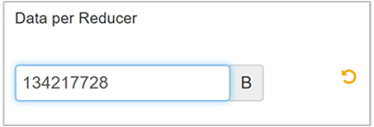
入力サイズが 1,024 MB、レジューサーごとのデータが 128 MB とすると、8 レジューサー (1024/128) になります。
[Data per Reducer](レジューサーごとのデータ) パラメーターの値が正しくない場合、多数のレジューサーが生成され、クエリのパフォーマンスに悪影響を及ぼす可能性があります。 レジューサーの最大数を制限するには、
hive.exec.reducers.maxを適切な値に設定します。 既定値は 1009 です。
並列実行を有効にする
Hive クエリは、1 つ以上のステージで実行されます。 独立したステージを並列実行できれば、クエリのパフォーマンスが向上します。
クエリの並列実行を有効にするには、Hive の [Configs]\(構成\) タブに移動し、
hive.exec.parallelプロパティを検索します。 既定値は false です。 値を true に変更し、Enter キーを押して値を保存します。並列実行するジョブの数を制限するには、
hive.exec.parallel.thread.numberプロパティを変更します。 既定値は 8 です。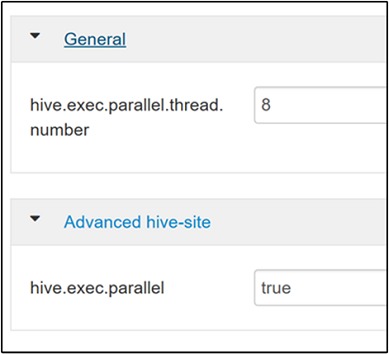
ベクター化を有効にする
Hive では行単位でデータを処理します。 ベクター化では、1 行ずつではなく、1,024 行のブロック単位でデータを処理するよう Hive に指示します。 ベクター化は、ORC ファイル形式にのみ適用されます。
ベクター化されたクエリ実行を有効にするには、Hive の [Configs]\(構成\) タブに移動し、
hive.vectorized.execution.enabledパラメーターを検索します。 Hive 0.13.0 以降では、既定値は true です。クエリの Reduce 側でベクター化された実行を有効にするには、
hive.vectorized.execution.reduce.enabledパラメーターを true に設定します。 既定値は false です。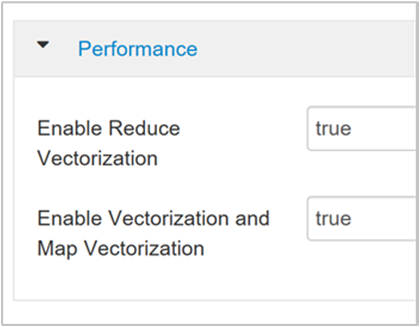
コストベースの最適化 (CBO) を有効にする
既定では、Hive は一連のルールに従って、1 つの最適なクエリ実行プランを見つけます。 コストベースの最適化 (CBO) は、クエリを実行するために複数のプランを評価します。 また、各プランにコストが割り当てられ、クエリの実行にかかるコストが最も低いプランが決定されます。
CBO を有効にするには、[Hive]>[Configs]\(構成\)>[Settings]\(設定\) に移動し、[Enable Cost Based Optimizer]\(コスト ベースのオプティマイザー を有効にする\) を探して、トグル ボタンを [オン] に切り替えます。

CBO を有効にすると、次の追加の構成パラメーターによって Hive クエリのパフォーマンスが向上します。
hive.compute.query.using.statstrue に設定すると、Hive はその metastore に保存されている統計を使用して、
count(*)のような単純なクエリに応答します。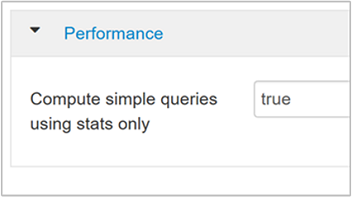
hive.stats.fetch.column.statsCBO を有効にすると、列統計が作成されます。 Hive は metastore に保存されている列統計を使用して、クエリを最適化します。 列数が多い場合、各列の列統計のフェッチに時間がかかります。 false に設定すると、metastore からの列統計のフェッチが無効になります。
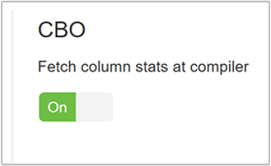
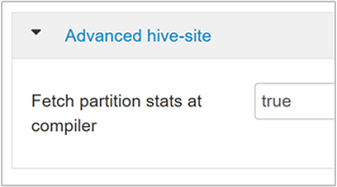
hive.stats.fetch.partition.stats基本的なパーティション統計 (行数、データ サイズ、ファイル サイズなど) は metastore に保存されています。 true に設定すると、metastore からパーティション統計がフェッチされます。 false の場合、ファイルのサイズはファイル システムからフェッチされます。 行の数は、行スキーマからフェッチされます。
詳しくは、「Azure での分析ブログ」で「Hive コスト ベースの最適化」のブログ記事をご覧ください
中間圧縮を有効にする
マップ タスクによって、レジューサー タスクで使用される中間ファイルが作成されます。 中間圧縮により、中間ファイルのサイズが縮小されます。
通常、Hadoop ジョブでは I/O ボトルネックが発生します。 データを圧縮することで、I/O を高速化し、全体的なネットワーク転送速度を向上させることができます。
使用可能な圧縮の種類は次のとおりです。
| Format | ツール | アルゴリズム | ファイル拡張子 | 分割可能かどうか |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
いいえ |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
はい |
| LZO | Lzop |
LZO | .lzo |
はい (インデックス付きの場合) |
| Snappy | 該当なし | Snappy | Snappy | いいえ |
原則として、分割可能な圧縮方法を使用することが重要です。そうしないと、作成されるマッパーが少数になります。 入力データがテキストの場合は、bzip2 が最適なオプションです。 ORC 形式の場合、Snappy が最速の圧縮オプションです。
中間圧縮を有効にするには、Hive の [Configs]\(構成\) タブに移動し、
hive.exec.compress.intermediateパラメーターを true に設定します。 既定値は false です。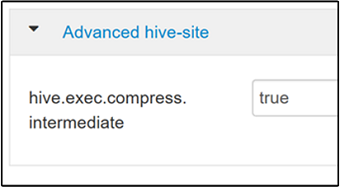
Note
中間ファイルを圧縮する場合、コーデックに高圧縮の出力がなくても、CPU コストが低い圧縮コーデックを選択します。
中間圧縮コーデックを設定するには、
mapred.map.output.compression.codecカスタム プロパティをhive-site.xmlファイルまたはmapred-site.xmlファイルに追加します。カスタム設定を追加するには、次の手順を実行します。
a. [Hive]>[Configs]\(構成\)>[Advanced]\(詳細\)>[Custom hive-site]\(カスタム hive-site\) に移動します。
b. [Custom hive-site](カスタム hive-site) ウィンドウの下部にある [Add Property...](プロパティの追加...) を選択します。
c. [Add Property](プロパティの追加) ウィンドウで、キーとして
mapred.map.output.compression.codec、値としてorg.apache.hadoop.io.compress.SnappyCodecを入力します。d. [追加] を選択します。
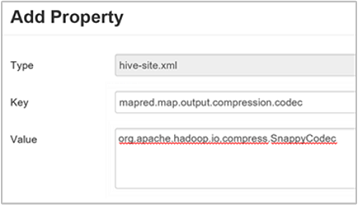
この設定により、Snappy 圧縮を使用して中間ファイルが圧縮されます。 プロパティが追加されると、[Custom hive-site](カスタム hive-site) ウィンドウに表示されます。
Note
この手順により、
$HADOOP_HOME/conf/hive-site.xmlファイルが変更されます。
最終出力を圧縮する
Hive の最終出力を圧縮することもできます。
Hive の最終出力を圧縮するには、Hive の [Configs]\(構成\) タブに移動し、
hive.exec.compress.outputパラメーターを true に設定します。 既定値は false です。出力圧縮コーデックを選択するには、前のセクションの手順 3. で説明したように、[Custom hive-site](カスタム hive-site) ウィンドウに
mapred.output.compression.codecカスタム プロパティを追加します。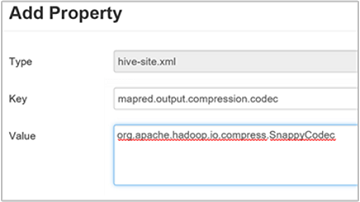
予測実行を有効にする
予測実行では、実行速度の遅いタスクトラッカーを検出して拒否一覧に登録するために、特定の数の重複タスクが起動されます。 個々のタスクの結果を最適化することで、全体的なジョブの実行を改善します。
大量の入力を伴う実行時間の長い MapReduce タスクでは、予測実行を有効にしないでください。
予測実行を有効にするには、Hive の [Configs]\(構成\) タブに移動し、
hive.mapred.reduce.tasks.speculative.executionパラメーターを true に設定します。 既定値は false です。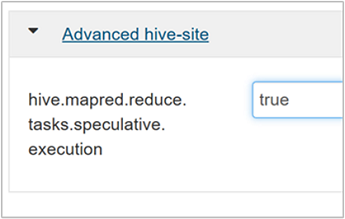
動的パーティションを調整する
Hive では、個々のパーティションを事前に定義せずに、レコードをテーブルに挿入するときに動的パーティションを作成できます。 これは強力な機能です。 ただし、これにより多数のパーティションが作成される可能性があります。 また、各パーティションには多数のファイルが含まれます。
Hive で動的パーティションを実行するには、
hive.exec.dynamic.partitionパラメーターの値が true (既定値) である必要があります。動的パーティション モードを strict に変更します。 strict モードでは、少なくとも 1 つのパーティションが静的である必要があります。 この設定により、WHERE 句にパーティション フィルターがないクエリを防ぐことができます。つまり、strict はすべてのパーティションをスキャンするクエリを防ぎます。 Hive の [Configs]\(構成\) タブに移動し、
hive.exec.dynamic.partition.modeを strict に設定します。 既定値は nonstrict です。作成する動的パーティションの数を制限するには、
hive.exec.max.dynamic.partitionsパラメーターを変更します。 既定値は 5000 です。ノードあたりの動的パーティションの総数を制限するには、
hive.exec.max.dynamic.partitions.pernodeを変更します。 既定値は 2000 です。
ローカル モードを有効にする
Hive のローカル モードでは、1 台のコンピューター上のジョブのすべてのタスクを実行できます。 または、場合によっては 1 つのプロセスで実行されます。 この設定により、入力データが小さい場合にクエリのパフォーマンスが向上します。 また、クエリのタスクを開始するオーバーヘッドがクエリの全体的な実行のかなりの割合を消費する場合、クエリのパフォーマンスが向上します。
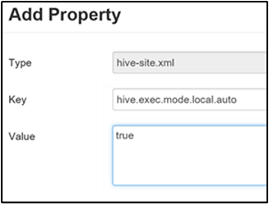
ローカル モードを有効にするには、「hive.exec.mode.local.auto」の手順 3. で説明したように、[Custom hive-site](カスタム hive-site) ウィンドウに hive.exec.mode.local.auto パラメーターを追加します。
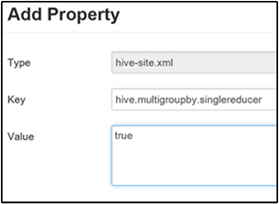
単一の MapReduce の MultiGROUP BY を設定する
このプロパティを true に設定すると、共通の group-by キーを使用する MultiGROUP BY クエリによって、単一の MapReduce ジョブが生成されます。
この動作を有効にするには、「hive.multigroupby.singlereducer」の手順 3. で説明したように、[Custom hive-site](カスタム hive-site) ウィンドウに hive.multigroupby.singlereducer パラメーターを追加します。
Hive のその他の最適化
以下のセクションでは、設定可能な Hive 関連のその他の最適化について説明します。
結合の最適化
Hive の既定の結合の種類は "シャッフル結合" です。 Hive では、特別なマッパーが入力を読み取り、中間ファイルに結合キーと値のペアを生成します。 Hadoop は、シャッフル ステージでこれらのペアを並べ替えてマージします。 このシャッフル ステージはコストがかかります。 データに基づいて適切な結合を選択すると、パフォーマンスを大幅に向上させることができます。
| 結合の種類 | タイミング | 方法 | Hive の設定 | 説明 |
|---|---|---|---|---|
| シャッフル結合 |
|
|
Hive の重要な設定は不要 | 毎回動作する |
| マップ結合 |
|
|
hive.auto.convert.join=true |
高速だが制限がある |
| 並べ替え/マージ/バケット処理 | 両方のテーブルが次の状態の場合:
|
各プロセス:
|
hive.auto.convert.sortmerge.join=true |
効率性 |
実行エンジンの最適化
Hive 実行エンジンの最適化に関するその他の推奨事項を次に示します。
| 設定 | 推奨 | HDInsight の既定値 |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = 安全性は高いが低速、false = 高速 | false |
tez.am.resource.memory.mb |
ほとんどの場合、上限は 4 GB | Auto-Tuned |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |