検索拡張生成または微調整を使用して大規模な言語モデルを拡張する
一連の記事では、大規模言語モデル (LLM) が応答の生成に使用する知識取得メカニズムについて説明します。 既定では、LLM はトレーニング データにのみアクセスできます。 ただし、モデルを拡張して、リアルタイム データまたはプライベート データを含めることができます。
最初のメカニズムは、取得拡張生成 (RAG)です。 RAG は、セマンティック検索とコンテキスト プライミングを組み合わせた前処理の形式です。 コンテキスト プライミング については、生成型 AI ソリューションを構築するための主要な概念と考慮事項で詳しく説明します。
2 つ目のメカニズムは、の微調整
以下のセクションでは、これらの 2 つのメカニズムについて詳しく説明します。
RAG について理解する
RAG は、"データを介したチャット" シナリオを有効にするためによく使用されます。 このシナリオでは、ドキュメント、ドキュメント、その他の独自のデータなど、テキスト コンテンツの大規模なコーパスが組織に含まれる可能性があります。 このコーパスは、ユーザー プロンプトに対する回答の基礎として使用されます。
大まかに言うと、各ドキュメントまたはドキュメントの一部に対して、チャンクと呼ばれるデータベース エントリを作成します。 チャンクは、ドキュメントのファセットを表す数値のベクトル (配列) の埋め込み時にインデックス化されます。 ユーザーがクエリを送信すると、データベースで同様のドキュメントを検索し、クエリとドキュメントを LLM に送信して回答を作成します。
Note
検索拡張世代 (RAG) という用語を緩和的に使用します。 この記事で説明する RAG ベースのチャット システムを実装するプロセスは、サポート容量 (RAG) で外部データを使用するか、応答 (RCG) の中心として使用するかを適用できます。 微妙な区別は、RAGに関連するほとんどの文献では述べられていません。
ベクトル化されたドキュメントのインデックスの作成
RAG ベースのチャット システムを作成する最初の手順は、ドキュメントまたはチャンクのベクター埋め込みを含むベクター データ ストアを作成することです。 ドキュメントのベクター化インデックスを作成するための基本的な手順を示す次の図を考えてみましょう。

この図は、データ パイプラインを表しています。 パイプラインは、システムが使用するデータのインジェスト、処理、および管理を担当します。 パイプラインには、ベクター データベースに格納されるデータの前処理と、LLM にフィードされるデータが正しい形式であることを確認する処理が含まれます。
プロセス全体は、機械学習モデルで処理できる方法で入力のセマンティック プロパティをキャプチャするデータ (通常は単語、フレーズ、文、またはドキュメント全体) の数値表現である埋め込みの概念によって駆動されます。
埋め込みを作成するには、コンテンツのチャンク (文、段落、またはドキュメント全体) を Azure OpenAI Embeddings API に送信します。 API はベクターを返します。 ベクター内の各値は、コンテンツの特性 (次元) を表します。 ディメンションには、トピック、セマンティックの意味、構文と文法、単語と語句の使用法、コンテキストリレーションシップ、スタイル、またはトーンが含まれる場合があります。 一緒に、ベクトルのすべての値は、コンテンツの 次元空間表します。 3 つの値を持つベクトルの 3D 表現を考えると、特定のベクトルは XYZ 平面の平面の特定の領域にあります。 1,000 以上の値がある場合はどうでしょうか。 人間が紙に 1,000 次元のグラフを描画して理解を深めることはできませんが、コンピューターはその程度の次元空間を理解しても問題ありません。
図の次の手順では、ベクターとコンテンツ (またはコンテンツの場所へのポインター) とその他のメタデータをベクター データベースに格納する方法を示します。 ベクター データベースは任意の種類のデータベースに似ていますが、次の 2 つの違いがあります。
- ベクトル データベースでは、データを検索するためのインデックスとしてベクトルが使用されます。
- ベクトル データベースは、コサイン類似検索と呼ばれるアルゴリズムを実装し、最近傍法とも呼ばれます。 このアルゴリズムでは、検索条件に最も近いベクトルが使用されます。
ベクター データベースに格納されているドキュメントのコーパスを使用すると、開発者は、ユーザーのクエリに一致するドキュメントを取得する 取得コンポーネント を構築できます。 データは、ユーザーのクエリに応答するために必要なものを LLM に提供するために使用されます。
ドキュメントを使用してクエリに応答する
RAG システムでは、まずセマンティック検索を使用して、LLM が回答を作成するときに役立つ可能性のある記事を見つけます。 次の手順では、ユーザーの元のプロンプトと一致する記事を LLM に送信して回答を作成します。
次の図は、単純な RAG 実装 (単純な RAG
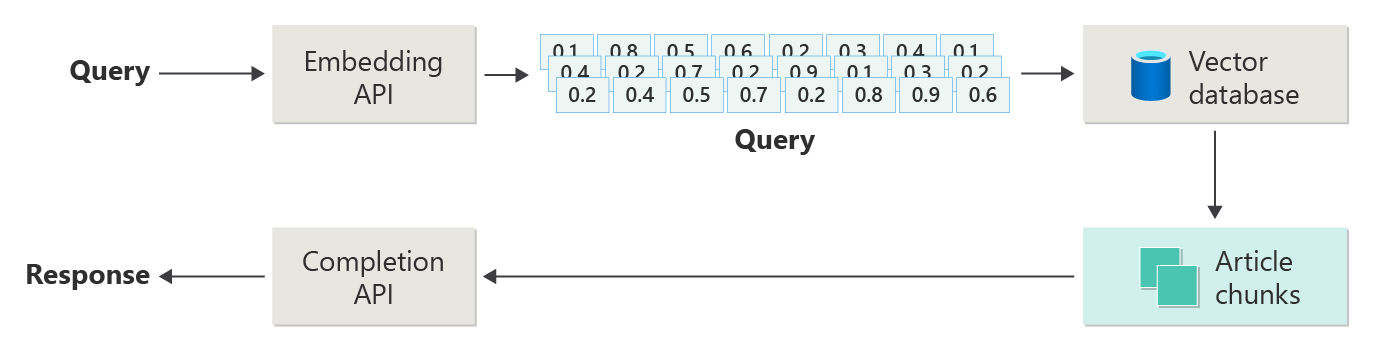
この図では、ユーザーがクエリを送信しています。 最初の手順では、ベクターを返すユーザーのプロンプトの埋め込みを作成します。 次の手順では、ベクトル データベースで、最も近い近隣の一致であるドキュメント (またはドキュメントの一部) を検索します。
コサイン類似度 は、2つのベクトルの類似性を測定するのに役立つ指標です。 基本的にメトリックは、それらの間の角度のコサインを評価します。 1 に近いコサインの類似性は、高い類似性 (小さな角度) を示します。 -1 付近の類似性は、非類似度 (ほぼ 180 度の角度) を示します。 このメトリックは、ドキュメントの類似性などのタスクにとって非常に重要です。ここでの目標は、類似したコンテンツまたは意味を持つドキュメントを見つけることです。
最近傍アルゴリズム、ベクトル空間内のポイントに最も近いベクトル (近隣) を見つけることで機能します。 k近傍法 (KNN) アルゴリズムでは、k は、考慮するk個の最近傍の数を指します。 このアプローチは、分類と回帰で広く使用されています。このアルゴリズムは、トレーニング セット内の最も近い近傍 k のマジョリティ ラベルに基づいて新しいデータ ポイント ラベルを予測します。 KNN とコサインの類似性は多くの場合、レコメンデーション エンジンなどのシステムで一緒に使用されます。その目的は、埋め込み空間内のベクトルとして表されるユーザーの好みに最も似た項目を見つけることです。
その検索から最適な結果を取得し、一致するコンテンツをユーザーのプロンプトと共に送信して、(できれば) 一致するコンテンツによって通知される応答を生成します。
課題と考慮事項
RAG システムには、一連の実装の課題があります。 データのプライバシーは最も重要です。 システムは、特に外部ソースから情報を取得して処理する場合に、ユーザー データを責任を持って処理する必要があります。 計算要件も重要な場合があります。 取得プロセスと生成プロセスの両方がリソースを集中的に消費します。 データまたはモデルのバイアスを管理しながら、応答の精度と関連性を確保することも、もう 1 つの重要な考慮事項です。 開発者は、効率的かつ倫理的で貴重な RAG システムを作成するため、これらの課題を慎重にナビゲートする必要があります。
高度な取得拡張生成システムを構築、運用対応の RAG システムを有効にするためにデータと推論パイプラインを構築する方法について詳しく説明します。
すぐに生成 AI ソリューションの構築の実験を開始する場合は、python 用の独自のデータ サンプルを使用してチャットを開始する を確認することをお勧めします。 このチュートリアルは、
モデルの微調整
LLM のコンテキストでは、微調整とは、LLM が最初に大規模で多様なデータセットでトレーニングされた後に、ドメイン固有のデータセットでトレーニングすることによってモデルのパラメーターを調整するプロセスです。
LLM は、幅広いデータセットでトレーニング (事前トレーニング) され、言語構造、コンテキスト、および幅広い知識を把握します。 この段階では、一般的な言語パターンを学習します。 微調整により、より小さい特定のデータセットに基づいて、事前トレーニング済みモデルにトレーニングが追加されます。 このセカンダリ トレーニング フェーズでは、特定のタスクに対してより適切に実行されるようにモデルを調整したり、特定のドメインを理解したりして、その精度と特殊なアプリケーションとの関連性を高めたりすることを目的としています。 微調整時、モデルの重みが調整され、この小さなデータセットの微妙な違いをより適切に予測または理解できるようになります。
いくつかの考慮事項があります。
- 特殊化: 微調整により、法的ドキュメント分析、医療テキストの解釈、カスタマー サービスの対話など、特定のタスクに合わせてモデルが調整されます。 この特殊化により、モデルはそれらの領域でより効果的になります。
- 効率: モデルをゼロからトレーニングするよりも、特定のタスクの事前トレーニング済みモデルを微調整する方が効率的です。 微調整では、必要なデータが少なくなり、計算リソースも少なくなります。
- 適応性: 微調整により、元のトレーニング データに含まれなかった新しいタスクやドメインに適応できます。 LLM の適応性により、さまざまなアプリケーションに対応する汎用性の高いツールが提供されます。
- パフォーマンスの向上: モデルが最初にトレーニングしたデータとは異なるタスクの場合、微調整によってパフォーマンスが向上する可能性があります。 微調整により、モデルが調整され、新しいドメインで使用される特定の言語、スタイル、または用語が理解されます。
- パーソナル化: 一部のアプリケーションでは、微調整によって、ユーザーまたは組織の特定のニーズや好みに合わせてモデルの応答や予測をカスタマイズできます。 ただし、微調整には特定の欠点と制限があります。 これらの要因を理解することは、RAG などの代替手段と微調整を選択するタイミングを決定するのに役立ちます。
- データ要件の: 微調整には、ターゲット タスクまたはドメインに固有の十分な大きさで高品質のデータセットが必要です。 このデータセットの収集とキュレーションは、困難かつリソースを大量に消費する可能性があります。
- オーバーフィットのリスク: オーバーフィットは、特に小規模なデータセットではリスクです。 オーバーフィットにより、モデルはトレーニング データに対して良好なパフォーマンスを発揮しますが、見えない新しいデータではパフォーマンスが低下します。 オーバーフィットが発生すると、一般化可能性が低下します。
- コストとリソースの: ゼロからのトレーニングよりもリソースを集中的に消費する量は少なくなりますが、微調整を行うには、特に大規模なモデルやデータセットに対して計算リソースが必要です。 一部のユーザーまたはプロジェクトでは、コストが非常に大きくなる可能性があります。
- メンテナンスと更新: 微調整されたモデルでは、ドメイン固有の情報が時間の経過と同時に変化しても有効な状態を維持するために、定期的な更新が必要になる場合があります。 この継続的なメンテナンスには、追加のリソースとデータが必要です。
- モデルの誤差: モデルは特定のタスク用に微調整されているため、一般的な言語の理解と汎用性の一部が失われる可能性があります。 この現象は、モデルドリフト
呼ばれます。
微調整を使用してモデルをカスタマイズ、モデルを微調整する方法について説明します。 大まかに言うと、潜在的な質問と好ましい回答の JSON データセットを提供します。 このドキュメントでは、50 ~ 100 の質問と回答のペアを提供することで顕著な改善が見られたことを示していますが、適切な数はユース ケースによって大きく異なります。
微調整と RAG
表面的には、微調整と RAG の間にかなりの重複があるように見えるかもしれません。 微調整と検索強化生成のどちらを選択するかは、パフォーマンスへの期待値、リソースの可用性、ドメインの特異性ニーズと一般化性の比較など、タスクの特定の要件によって異なります。
RAG の代わりに微調整を使用する場合:
- タスク固有のパフォーマンス: 特定のタスクの高パフォーマンスが重要であり、大きなオーバーフィット リスクなしでモデルを効果的にトレーニングするのに十分なドメイン固有のデータが存在する場合は、微調整が推奨されます。
- データの制御: 基本モデルのトレーニング対象データとは大きく異なる独自のデータまたは高度に特殊化されたデータがある場合、微調整を行うことで、この固有の知識をモデルに組み込むことができます。
- リアルタイム更新の必要性が制限: タスクで最新の情報でモデルを常に更新する必要がない場合、RAG モデルは通常、最新のデータを取得するために up-to-date 外部データベースまたはインターネットにアクセスする必要があるため、微調整がより効率的になる可能性があります。
微調整よりも RAG を優先する場合:
- 動的コンテンツまたは進化するコンテンツ: RAG は、最新の情報が重要なタスクに適しています。 RAG モデルは外部ソースからリアルタイムでデータを取り込むことができるため、ニュース生成や最近のイベントに関する質問への回答などのアプリケーションに適しています。
- 特殊化に対する一般化: 狭い領域で優れているのではなく、幅広いトピックで強力なパフォーマンスを維持することが目標である場合は、RAG が推奨される場合があります。 外部サポート情報が使用されるため、特定のデータセットにオーバーフィットするリスクを伴うことなくさまざまなドメイン間で応答を生成できます。
- リソースの制約: データ収集とモデルトレーニングのリソースが限られている組織では、RAG アプローチを使用すると、特に基本モデルが目的のタスクに対して合理的に適切に実行されている場合に、微調整に代わるコスト効率の高い代替手段が提供される可能性があります。
アプリケーション設計に関する最終的な考慮事項
アプリケーションの設計上の決定に影響を与える可能性がある、この記事で考慮すべき事項とその他のポイントの簡単な一覧を次に示します。
- アプリケーションの特定のニーズに基づいて、微調整と RAG を決定します。 微調整により、特殊なタスクのパフォーマンスが向上する一方で、RAG では動的アプリケーションの柔軟性と up-to日付コンテンツが提供される場合があります。