高度な検索拡張生成システムを構築する
この記事では、取得拡張生成 (RAG) について詳しく説明します。 開発者が運用環境に対応した RAG ソリューションを作成するために必要な作業と考慮事項について説明します。
ビジネスにおけるジェネレーティブ AI のトップ ユース ケースの 1 つである "データを介したチャット" アプリケーションを構築するための 2 つのオプションについては、「RAG を使用して LLM を拡張する 」または「の微調整」を参照してください。
次の図は、RAG の手順またはフェーズを示しています。
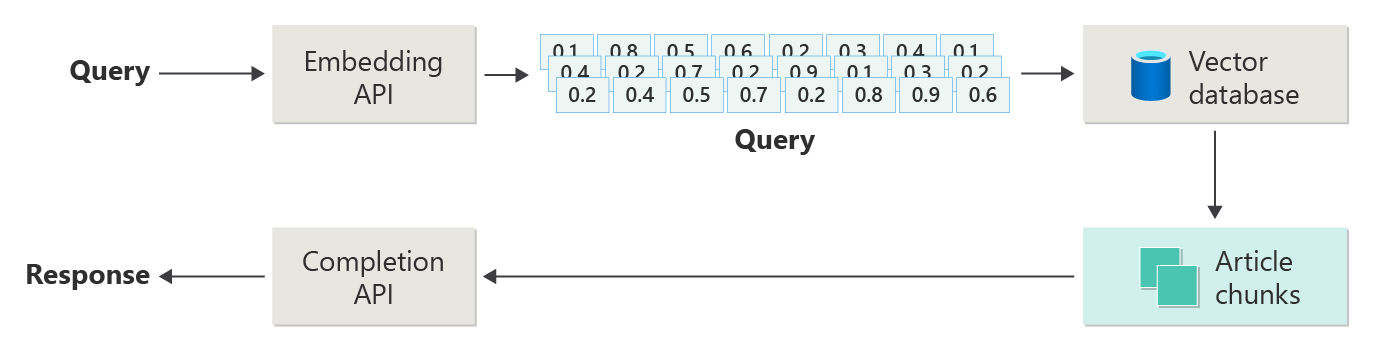
この図は、単純な RAG と呼ばれるものです。 これは、RAG ベースのチャット システムを実装するために必要なメカニズム、役割、責任を最初に理解するのに便利な方法です。
ただし、実際の実装には、記事、クエリ、および応答を使用できるように準備するための、より多くの前処理と後処理の手順があります。 次の図は、RAG をより現実的に表したもので、高度な RAG と呼ばれることもあります。

この記事では、実際の RAG ベースのチャット システムでの前処理フェーズと後処理フェーズを理解するための概念的なフレームワークについて説明します。
- インジェスト フェーズ
- 推論パイプライン フェーズ
- 評価フェーズ
インジェスト
インジェストは、主に組織のドキュメントを格納して、ユーザーの質問に答えるために簡単に取得できるようにします。 課題は、ユーザーのクエリに最も一致するドキュメントの部分が、推論中に配置され、使用されるようにすることです。 照合は、主にベクトル化された埋め込みとコサイン類似性検索によって実現されます。 ただし、コンテンツの性質 (パターンやフォームなど) とデータ編成戦略 (ベクター データベースに格納されている場合のデータの構造) を理解することで、照合が容易になります。
インジェストの場合、開発者は次の手順を考慮する必要があります。
- コンテンツの前処理と抽出
- チャンク戦略
- チャンク編成
- 戦略を更新する
コンテンツの前処理と抽出
クリーンで正確なコンテンツは、RAG ベースのチャット システムの全体的な品質を向上させる最良の方法の 1 つです。 クリーンで正確なコンテンツを取得するには、まず、インデックスを作成するドキュメントの形状と形式を分析します。 ドキュメントは、ドキュメントなどの指定されたコンテンツ パターンに準拠していますか? そうでない場合、ドキュメントはどのような種類の質問に答える可能性がありますか?
少なくとも、インジェスト パイプラインに次の手順を作成します。
- テキスト形式を標準化する
- 特殊文字を処理する
- 関連性のない古いコンテンツを削除する
- バージョン管理されたコンテンツのアカウント
- コンテンツ エクスペリエンスのアカウント (タブ、画像、テーブル)
- メタデータを抽出する
この情報の一部 (メタデータなど) は、推論パイプラインの取得および評価プロセス中に使用するためにベクター データベース内のドキュメントと共に保持されている場合に役立つ場合があります。 また、テキスト チャンクと組み合わせて、チャンクのベクトル埋め込みを促すこともできます。
チャンク戦略
開発者は、より大きなドキュメントをより小さなチャンクに分割する方法を決定する必要があります。 チャンクを使用すると、LLM に送信される補足コンテンツの関連性が向上し、ユーザー クエリに正確に応答できます。 また、取得後のチャンクの使用方法についても検討してください。 システム デザイナーは、一般的な業界の手法を調査し、いくつかの実験を行う必要があります。 組織内の限られた容量で戦略をテストすることもできます。
開発者は、以下の点を考慮する必要があります。
- チャンク サイズの最適化: 最適なチャンク サイズとチャンクを指定する方法を決定します。 セクション単位 段落単位 文単位
- 重複とスライディング ウィンドウのチャンク: コンテンツを個別のチャンクに分割するか、チャンクを重複させるかを決定します。 スライディング ウィンドウのデザインでは、両方を実行することもできます。
- Small2Big: チャンクが細かいレベル、例えば1つの文で行われる場合、コンテンツは隣接する文やそれを含む段落を簡単に見つけられるようにしっかりと整理されていますか? この情報を取得して LLM に提供すると、ユーザー クエリに応答するためのより多くのコンテキストが提供される場合があります。 詳細については、次のセクションを参照してください。
チャンク編成
RAG システムでは、ベクター データベース内のデータを戦略的に整理することが、生成プロセスを強化するために関連情報を効率的に取得するための鍵となります。 考慮する可能性があるインデックス作成と取得の戦略の種類を次に示します。
- 階層インデックス: このアプローチでは、インデックスの複数のレイヤーを作成する必要があります。 最上位レベルのインデックス (サマリー インデックス) を使用すると、検索領域を関連する可能性のあるチャンクのサブセットにすばやく絞り込みます。 第 2 レベルのインデックス (チャンク インデックス) は、実際のデータへのより詳細なポインターを提供します。 この方法では、最初に概要インデックスをフィルター処理することで、詳細インデックス内でスキャンするエントリの数が減るため、取得プロセスを大幅に高速化できます。
- 特殊化インデックス: データの性質とチャンク間のリレーションシップに応じて、グラフ ベースやリレーショナル データベースなどの特殊なインデックスを使用できます。
- グラフ ベースのインデックスは、引用ネットワークやナレッジ グラフなど、取得を強化できる情報またはリレーションシップがチャンクに相互接続されている場合に役立ちます。
- リレーショナル データベース は、チャンクが表形式で構成されている場合に有効です。 SQL クエリを使用して、特定の属性またはリレーションシップに基づいてデータをフィルター処理および取得します。
- ハイブリッド インデックス: ハイブリッド アプローチでは、複数のインデックス作成方法を組み合わせて、その強みを全体的な戦略に適用します。 たとえば、最初のフィルター処理に階層インデックスを使用し、グラフベースのインデックスを使用して、取得中にチャンク間のリレーションシップを動的に探索できます。
配置の最適化
取得したチャンクの関連性と精度を高めるために、回答する質問またはクエリの種類に合わせてそれらを厳密に調整します。 1 つの戦略は、チャンクが回答に最適な質問を表すチャンクごとに仮定の質問を生成して挿入する方法です。 これは、以下のいくつかの点で役立ちます。
- 照合の改善: 検索時に、システムは受信したクエリとこれらの仮説的な質問を比較して最適な一致を見つけ、取得されるチャンクの関連性を向上させることができます。
- 機械学習モデルのトレーニング データ: これらの質問とチャンクのペアは、RAG システムの基になるコンポーネントである機械学習モデルを改善するためのトレーニング データです。 RAG システムは、各チャンクで最適に回答される質問の種類を学習します。
- 直接クエリ処理: 実際のユーザー クエリが架空の質問と密接に一致する場合、システムは対応するチャンクをすばやく取得して使用し、応答時間を短縮できます。
各チャンクの仮定の質問は、取得アルゴリズムをガイドするラベルのように機能するため、より焦点を絞り、コンテキストに対応します。 この種の最適化は、チャンクがさまざまな情報トピックまたは種類をカバーする場合に便利です。
更新方法
組織が頻繁に更新されるドキュメントにインデックスを作成する場合は、更新されたコーパスを維持して、取得元コンポーネントが最新の情報に確実にアクセスできるようにすることが不可欠です。 取得コンポーネント は、ベクター データベースに対してクエリを実行し、結果を返すシステム内のロジックです。 これらの種類のシステムでベクター データベースを更新するための戦略を次に示します。
増分更新:
- 定期的な間隔: ドキュメントの変更頻度に応じて、定期的な間隔 (毎日または毎週など) で更新をスケジュールします。 この方法により、データベースが既知のスケジュールに従って定期的に更新されます。
- トリガー ベースの更新: 更新によってインデックスの再作成がトリガーされるシステムを実装します。 たとえば、ドキュメントを変更または追加すると、影響を受けるセクションでインデックスの再作成が自動的に開始されます。
部分更新:
- 選択的インデックス再作成: データベース全体のインデックスを再作成する代わりに、変更されたコーパス部分のみを更新します。 この方法は、完全なインデックス再作成よりも効率的です (特に大規模なデータセットの場合)。
- 差分エンコード: 既存のドキュメントとその更新されたバージョンの違いのみ格納します。 このアプローチでは、変更されていないデータを処理する必要がないようにすることで、データ処理の負荷が軽減されます。
バージョン管理:
- スナップショット作成: ドキュメントコーパスバージョンを異なる時点で維持します。 この手法は、バックアップ メカニズムを提供し、システムが以前のバージョンに戻すか、以前のバージョンを参照できるようにします。
- ドキュメントのバージョン管理: バージョン管理システムを使用して、変更履歴を維持し、更新プロセスを簡略化するためにドキュメントの変更を体系的に追跡します。
リアルタイム更新:
- ストリーム処理: 情報タイムラインが重要な場合は、ドキュメントに変更が加えられたときに、リアルタイム ベクター データベースの更新にストリーム処理テクノロジを使用します。
- ライブ クエリ: インデックス付きベクターのみに依存するのではなく、ライブ データクエリアプローチを使用して up-to-date 応答を行い、ライブ データとキャッシュされた結果を組み合わせて効率を高めます。
最適化手法:
バッチ処理: バッチ処理では、リソースを最適化し、オーバーヘッドを削減するために、変更が蓄積され、適用頻度が低くなります。
ハイブリッド アプローチ: さまざまな戦略を組み合わせます。
- 軽微な変更には増分更新を使用します。
- メジャー更新プログラムでは、完全なインデックス再作成を使用します。
- コーパスに加えられた構造変更を文書化します。
適切な更新戦略または適切な組み合わせを選択することは、次のような特定の要件によって異なります。
- ドキュメント コーパスのサイズ
- 更新頻度
- リアルタイム データのニーズ
- リソースの可用性
特定のアプリケーションのニーズに基づいて、これらの要因を評価します。 各アプローチには、複雑さ、コスト、更新の待機時間のトレードオフがあります。
推論パイプライン
アーティクルはチャンクされ、ベクター化され、ベクター データベースに格納されます。 次に、完了の課題の解決に焦点を当てます。
最も正確で効率的な完了を得るには、多くの要因を考慮する必要があります。
- ユーザーのクエリは、ユーザーが探している結果を取得する方法で記述されていますか?
- ユーザーのクエリは、組織のポリシーに違反していますか?
- ベクター データベースで最も近い一致を見つける可能性を高めるために、ユーザーのクエリをどのように書き直しますか?
- クエリの結果を評価して、記事のチャンクがクエリに確実に揃うようにするにはどうすればよいですか?
- LLM にクエリ結果を渡す前に、クエリ結果を評価および変更して、最も関連性の高い詳細が完了に確実に含まれるようにするにはどうすればよいですか?
- LLM の応答を評価して、LLM の完了がユーザーの元のクエリに確実に応答するようにするにはどうすればよいですか?
- LLM の応答が組織のポリシーに準拠していることを確認するにはどうすればよいですか?
推論パイプライン全体がリアルタイムで実行されます。 前処理と後処理の手順を設計する正しい方法は 1 つではありません。 プログラミング ロジックとその他の LLM 呼び出しの組み合わせを選択する可能性があります。 最も重要な考慮事項の 1 つは、可能な限り正確で準拠しているパイプラインを構築することと、それを実現するために必要なコストと待機時間のトレードオフです。
推論パイプラインの各ステージで特定の戦略を特定しましょう。
クエリの前処理手順
クエリの前処理は、ユーザーがクエリを送信した直後に行われます。

これらの手順の目的は、ユーザーがシステムの範囲内にある質問を確実に行い、コサインの類似性または "ニアレスト ネイバー" 検索を使用して、可能な限り最適な記事チャンクを見つける可能性を高めるためにユーザーのクエリを準備することです。
ポリシー チェック: この手順には、特定のコンテンツを識別、削除、フラグ付け、または拒否するロジックが含まれます。 たとえば、個人データの削除や不適切な言葉の削除、"脱獄" 試行の特定があります。 ジェイルブレイクとは、モデルに組み込まれた安全性、倫理性、または運用上のガイドラインをユーザーが回避または操作しようとすることを指します。
クエリの書き換え: この手順は、頭字語を拡張したり、スラングを削除したり、より抽象的に質問したりして、高レベルの概念と原則 (ステップ バックプロンプト) を抽出するために質問を言い換えることから何でも可能です。
ステップバック プロンプトのバリエーションとして、仮想ドキュメント埋め込み (HyDE) があります。 HyDE は LLM を使用してユーザーの質問に回答し、その応答の埋め込み (架空のドキュメント埋め込み) を作成した後、埋め込みを使用してベクター データベースに対して検索を実行します。
サブクエリ
サブクエリ処理ステップは、元のクエリに基づいています。 元のクエリが長くて複雑な場合は、プログラムによって複数の小さなクエリに分割し、すべての応答を結合すると便利です。
たとえば、物理学における科学的発見に関する質問は、「誰が現代物理学、アルバート・アインシュタイン、ニールス・ボーアにもっと大きな貢献をしたか」と考えられます。
複雑なクエリをサブクエリに分割すると、管理しやすくなります。
- サブクエリ 1: 「アルバート・アインシュタインの現代物理学への重要な貢献は何ですか?
- サブクエリ 2: "Niels Bohr の現代物理学への重要な貢献は何ですか?
これらのサブクエリの結果は、各物理学者による主要な理論と発見を詳しく説明しています。 次に例を示します。
- アインシュタインの場合、相対性理論、光電効果、E=mc^2が含まれる可能性があります。
- Bohr の貢献には、Bohr の水素原子のモデル、ボーアの量子力学に関する研究、およびボーアの補完の原則が含まれる場合があります。
これらのコントリビューションの概要が示されたら、それらの貢献を評価して、より多くのサブクエリを決定できます。 次に例を示します。
- サブクエリ 3: 「アインシュタインの理論は現代物理学の発展にどのように影響しましたか?
- サブクエリ 4: 「ボーアの理論は現代物理学の発展にどのように影響しましたか?
これらのサブクエリでは、次のような物理に対する各科学者の影響を調べることができます。
- アインシュタインの理論が宇宙論と量子理論の進歩につながった方法
- ボーアの研究が原子構造と量子力学の理解にどのように貢献したか
これらのサブクエリの結果を組み合わせることで、言語モデルは、理論上の進歩に基づいて現代の物理学により重要な貢献をしたユーザーに関するより包括的な応答を形成するのに役立ちます。 このメソッドは、より具体的で回答可能なコンポーネントにアクセスし、それらの結果を一貫した回答に合成することで、元の複雑なクエリを簡略化します。
クエリ ルーター
組織では、コンテンツのコーパスを複数のベクター ストアまたは取得システム全体に分割することを選択できます。 そのシナリオでは、クエリ ルーターを使用できます。 クエリ ルーター は、特定のクエリに対する最適な回答を提供するために、最適なデータベースまたはインデックスを選択します。
クエリ ルーターは、通常、ユーザーがクエリを作成した後、クエリを取得システムに送信する前の時点で動作します。
クエリ ルーターの簡略化されたワークフローを次に示します。
- クエリ分析: LLM または別のコンポーネントは、受信クエリを分析して、その内容、コンテキスト、および必要となる可能性のある情報の種類を理解します。
- インデックス選択: クエリ ルーターは、分析に基づいて、使用可能な複数のインデックスから 1 つ以上のインデックスを選択します。 各インデックスは、さまざまな種類のデータまたはクエリに最適化される場合があります。 たとえば、一部のインデックスは、ファクト クエリに適している場合があります。 他のインデックスは、意見や主観的なコンテンツを提供することに優れている場合があります。
- クエリ ディスパッチ: 選択したインデックスにクエリがディスパッチされます。
- 結果の集計: 選択したインデックスからの応答が取得され、場合によっては集計または処理されて包括的な回答が形成されます。
- 回答生成: 最後の手順では、取得した情報に基づいてコヒーレント応答を生成し、複数のソースからコンテンツを統合または合成する必要があります。
組織では、以下のユース ケースに対して複数の取得エンジンまたはインデックスを使用する場合があります。
- データ型の特殊化: 一部のインデックスは、ニュース記事、学術論文、さらに一般的な Web コンテンツや特定のデータベース (医療情報や法的情報など) に特化している場合があります。
- クエリの種類の最適化: 特定のインデックスは、迅速な事実検索 (日付やイベントなど) 用に最適化される場合があります。 複雑な推論タスクや、ドメインに関する深い知識を必要とするクエリに使用する方が適している場合もあります。
- アルゴリズムの違い: ベクターベースの類似性検索、従来のキーワードベースの検索、より高度なセマンティック理解モデルなど、さまざまな検索アルゴリズムが異なるエンジンで使用される場合があります。
医療勧告コンテキストで使用される RAG ベースのシステムを想像してみてください。 システムは複数のインデックスにアクセスできます。
- 詳細な説明と技術的な説明のために最適化された医学研究論文のインデックス
- 症状と治療の実際の例を提供する臨床ケース スタディ インデックス
- 基本的な質問や公衆衛生情報に関する健康情報の一般的な索引
ユーザーが新薬の生化学効果に関する技術的な質問をした場合、クエリ ルーターは、その深さと技術的な焦点に基づいて、医学研究論文インデックスを優先する可能性があります。 しかし、一般的な病気の典型的な症状に関する質問の場合、内容が幅広く理解しやすいため、一般的な健康指標が選択される場合があります。
取得後の処理ステップ
取得後の処理は、取得元コンポーネントがベクター データベースから関連するコンテンツ チャンクを取得した後に発生します。

候補コンテンツ チャンクを取得したら、次のステップは、LLM に提示するプロンプトを準備する前に、LLM プロンプトを拡張するときに記事チャンクの有用性を検証することです。
プロンプトの側面で考慮すべき事項を次に示します。
- あまりにも多くの補足情報を含めると、最も重要な情報が無視される可能性があります。
- 無関係な情報を含めると、回答に悪影響を及ぼす可能性があります。
もう 1 つの考慮事項は、"干し草の山の中の針" の問題です。これは、プロンプトの最初と最後のコンテンツが、中間のコンテンツよりも LLM にとって大きな重みを持つという、一部の LLM の既知の癖を指す用語です。
最後に、LLM の最大コンテキスト ウィンドウ長と、非常に長いプロンプトを完了するために必要なトークンの数を検討します (特に大規模なクエリの場合)。
これらの問題に対処するため、取得後処理パイプラインには以下のステップが含まれる場合があります。
- 結果のフィルター処理: この手順では、ベクター データベースによって返されるアーティクル チャンクがクエリに関連していることを確認します。 そうでない場合、LLM プロンプトが作成されるときに結果は無視されます。
- 再ランク付け: ベクトル ストアから取得したアーティクル チャンクをランク付けして、関連する詳細がプロンプトの端 (先頭と末尾) の近くにあることを確認します。
- プロンプト圧縮: プロンプトを LLM に送信する前に、小規模で安価なモデルを使用して、複数のアーティクルチャンクを 1 つの圧縮プロンプトに圧縮して要約します。
完了後の処理ステップ
完了後の処理は、ユーザーのクエリの後に発生し、すべてのコンテンツ チャンクが LLM に送信されます。

精度の検証は、LLM のプロンプトの完了後に行われます。 完了後の処理パイプラインには、以下のステップが含まれる場合があります。
- ファクト チェック: 事実として提示されている記事で行われた特定の要求を特定し、その事実を正確に確認することを目的とします。 ファクト チェックの手順が失敗した場合は、より良い回答を得るために LLM を再クエリするか、ユーザーにエラー メッセージを返すのが適切な場合があります。
- ポリシー チェック: 回答に有害なコンテンツが含まれていないことを確認するための防御の最後の行 。ユーザーまたは組織のどちらに対しても。
評価
非決定的システムの結果の評価は、ほとんどの開発者が慣れている単体テストまたは統合テストを実行するほど簡単ではありません。 いくつかの要因を考慮する必要があります。
- ユーザーは取得している結果に満足していますか?
- ユーザーは質問に対して正確な回答を得ていますか?
- ユーザー フィードバックをキャプチャする方法 ユーザー データに関して収集できるデータを制限するポリシーはありますか?
- 不十分な回答の診断のために、質問に答えるすべての作業を可視化していますか? 根本原因分析を実行できるように、入力と出力の推論パイプラインに各ステージのログを保持していますか?
- 回帰や結果の低下なしにシステムに変更を加える方法
ユーザーからのフィードバックのキャプチャと操作
前述のように、組織のプライバシー チームと協力して、クエリ セッションのフォレンジックと根本原因分析のためのフィードバック キャプチャ メカニズム、テレメトリ、ログ記録を設計することが必要になる場合があります。
次のステップでは、評価パイプラインを開発します。 評価パイプラインは、逐語的なフィードバックを分析する複雑さと時間のかかる性質と、AI システムによって提供される応答の根本原因に役立ちます。 この分析は、すべての応答を調査して、AI クエリが結果をどのように生成したかを理解し、ドキュメントから使用されるコンテンツ チャンクの適切性を確認し、これらのドキュメントを分割するために使用される戦略を調べることが含まれるため、非常に重要です。
また、結果を強化する可能性のある追加の前処理または後処理の手順も考慮する必要があります。 この詳細な調査では、多くの場合、特にユーザーのクエリへの応答に適したドキュメントが存在しない場合に、コンテンツのギャップが明らかになります。
これらのタスクの規模を効果的に管理するには、評価パイプラインの構築が不可欠になります。 効率的なパイプラインでは、カスタム ツールを使用して、AI によって提供される回答の品質を概算するメトリックを評価します。 このシステムは、ユーザーの質問に対して特定の回答が与えられた理由、その回答の生成に使用されたドキュメント、およびクエリを処理する推論パイプラインの有効性を判断するプロセスを効率化します。
ゴールデン データセット
RAG チャット システムのような非決定的なシステムの結果を評価する方法の 1 つは、ゴールデン データセットを使用することです。 ゴールデン データセット は、精選された一連の質問と承認された回答、メタデータ (トピックや質問の種類など)、回答の基礎となる真理として役立つソース ドキュメントへの参照、さらにはバリエーション (ユーザーが同じ質問をする方法の多様性を把握するためのさまざまな言い回し) です。
ゴールデン データセットは、"ベスト ケース シナリオ" を表します。開発者は、システムを評価してパフォーマンスを確認し、新しい機能や更新プログラムを実装するときに回帰テストを実行できます。
損害の評価
損害モデリングは、潜在的な損害を予測して、個人にリスクをもたらす可能性のある製品の欠陥を発見し、そのようなリスクを軽減するための積極的な戦略を策定することを目的とした手法です。
テクノロジ (特に AI システム) の影響を評価するために設計されたツールは、提供されたリソースで概説されているように、損害モデリングの原則に基づいていくつかの重要なコンポーネントを備えています。
損害評価ツールの主な機能は、以下のとおりです。
利害関係者識別: このツールは、直接ユーザー、間接的に影響を受ける関係者、将来の世代や環境上の懸念などの非人道的要因など、テクノロジの影響を受けるさまざまな利害関係者を識別して分類するのに役立つ場合があります。
損害のカテゴリと説明: このツールには、プライバシーの喪失、感情的な苦痛、経済的搾取など、潜在的な損害の包括的な一覧が含まれる場合があります。 このツールは、さまざまなシナリオをユーザーに案内し、テクノロジがこれらの損害を引き起こす可能性がある方法を示し、意図した結果と意図しない結果の両方を評価するのに役立ちます。
重大度と確率の評価: このツールは、ユーザーが特定された各損害の重大度と確率を評価するのに役立つ場合があります。 ユーザーは、最初に対処する問題に優先順位を付けることができます。 たとえば、データでサポートされている定性評価 (使用可能な場合) などがあります。
軽減策: このツールは、害を特定して評価した後に、潜在的な軽減戦略を提案できます。 たとえば、システム設計の変更、セーフガードの追加、特定されたリスクを最小限に抑える代替技術ソリューションなどがあります。
フィードバックメカニズム: このツールには、損害評価プロセスが動的で、新しい情報や視点に応答できるように、利害関係者からのフィードバックを収集するためのメカニズムを組み込む必要があります。
ドキュメントとレポート: 透明性と説明責任のために、ツールは、損害評価プロセス、調査結果、および実行される潜在的なリスク軽減アクションを文書化する詳細なレポートを容易にする可能性があります。
これらの機能は、リスクを特定して軽減するのに役立ちますが、最初から広範な影響を考慮することで、より倫理的で責任ある AI システムを設計するのにも役立ちます。
詳細については、次の記事を参照してください。
セーフガードのテストと検証
この記事では、RAG ベースのチャット システムが悪用または侵害される可能性を軽減することを目的としたいくつかのプロセスについて説明します。 レッド チーミング は、軽減策が効果的であることを保証する上で重要な役割を果たします。 レッド チーミングでは、潜在的な敵対者のアクションをシミュレートして、アプリケーションの潜在的な弱点や脆弱性を明らかにします。 このアプローチは、ジェイルブレイクの重大なリスクに対処する上で特に重要です。
開発者は、さまざまなガイドライン シナリオで RAG ベースのチャット システムセーフガードを厳密に評価して、それらを効果的にテストおよび検証する必要があります。 このアプローチは堅牢性を確保するだけでなく、定義された倫理基準と運用手順に厳密に準拠するようにシステムの応答を微調整するのにも役立ちます。
アプリケーション設計に関する最終的な考慮事項
アプリケーションの設計上の決定に影響を与える可能性がある、この記事で考慮すべき事項とその他のポイントの簡単な一覧を次に示します。
- 設計における生成 AI の非決定的な性質を確認します。 出力の変動性を計画し、応答の一貫性と関連性を確保するためのメカニズムを設定します。
- 待ち時間とコストの増加の可能性に対するユーザー プロンプトの前処理の利点を評価します。 送信前にプロンプトを簡略化または変更すると、応答の品質が向上する可能性がありますが、応答サイクルに複雑さと時間が追加される可能性があります。
- パフォーマンスを向上させるには、LLM 要求を並列化するための戦略を調査します。 この方法では待機時間が短縮される可能性がありますが、複雑さとコストへの影響の可能性を回避するには慎重な管理が必要です。
生成型 AI ソリューションの構築の実験をすぐに開始する場合は、「Python用の独自のデータ サンプルを使用してチャットを開始する」を参照することをお勧めします。 このチュートリアルは、