H3 クイック スタート (Databricks SQL)
このページの H3 地理空間関数のクイック スタートでは、次のことを説明します。
- 位置情報データセットを Unity Catalog に読み込む方法。
- 緯度と経度の列を H3 セル列に変換する方法。
- 郵便番号ポリゴンまたはマルチポリゴン WKT 列を H3 セル列に変換する方法。
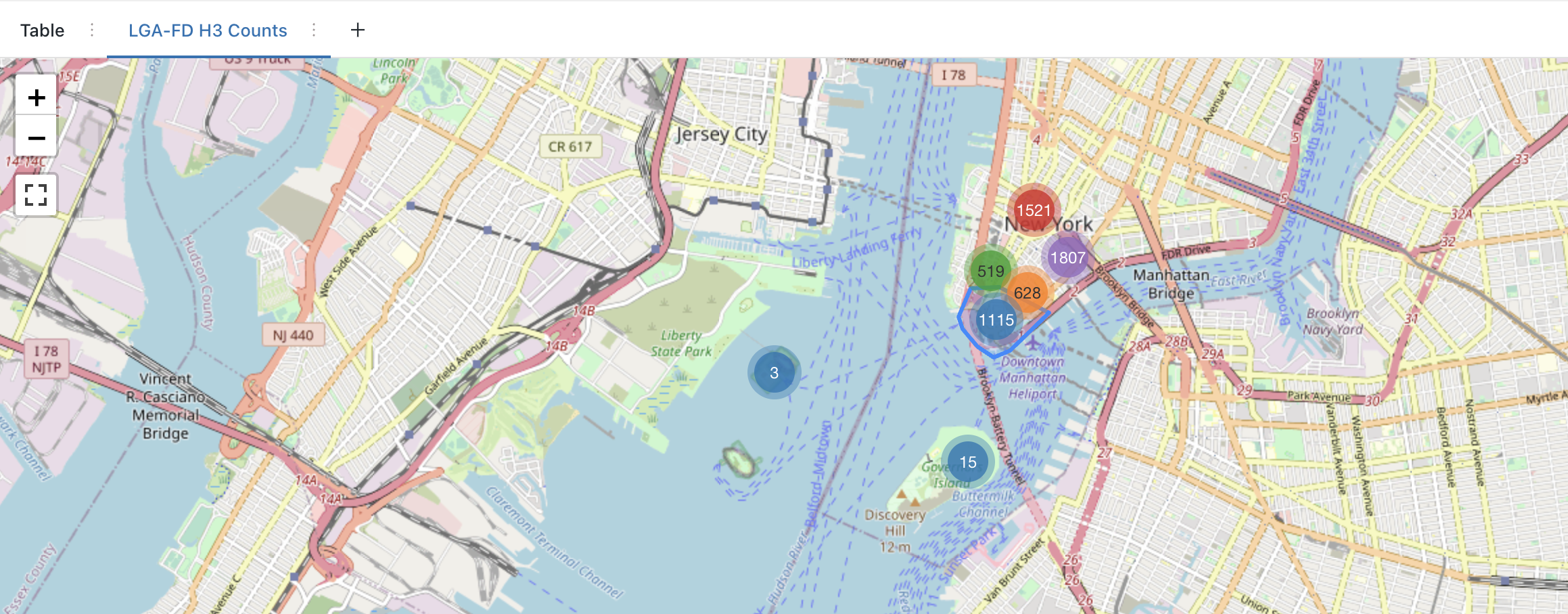
- ラガーディア空港からマンハッタンの金融街へのピックアップとドロップオフの分析を照会する方法。
- H3 集計カウントをマップにレンダリングする方法。
ノートブックとクエリの例
Unity Catalog データを準備する
このノートブックでは、次の操作を行います。
- Databricks Filesystem からタクシーのパブリック データセットを設定する。
- NYC の郵便番号データセットを設定する。
Unity Catalog データを準備する
Databricks Runtime 11.3 LTS 以降を使用した Databricks SQL クエリ
クエリ 1: 基本データがセットアップされていることを確認します。 「ノートブック」を参照してください。
use catalog geospatial_docs;
use database nyc_taxi;
show tables;
-- Verify initial data is setup (see instructions in setup notebook)
-- select format_number(count(*),0) as count from yellow_trip;
-- select * from nyc_zipcode;
クエリ 2: H3 NYC 郵便番号 - 解像度 で 12 を適用します。
use catalog geospatial_docs;
use database nyc_taxi;
-- drop table if exists nyc_zipcode_h3_12;
create table if not exists nyc_zipcode_h3_12 as (
select
explode(h3_polyfillash3(geom_wkt, 12)) as cell,
zipcode,
po_name,
county
from
nyc_zipcode
);
-- optional: zorder by `cell`
optimize nyc_zipcode_h3_12 zorder by (cell);
select
*
from
nyc_zipcode_h3_12;
クエリ 3: H3タクシー トリップ - 解像度 で 12 を適用します。
use catalog geospatial_docs;
use database nyc_taxi;
-- drop table if exists yellow_trip_h3_12;
create table if not exists yellow_trip_h3_12 as (
select
h3_longlatash3(pickup_longitude, pickup_latitude, 12) as pickup_cell,
h3_longlatash3(dropoff_longitude, dropoff_latitude, 12) as dropoff_cell,
*
except
(
rate_code_id,
store_and_fwd_flag
)
from
yellow_trip
);
-- optional: zorder by `pickup_cell`
-- optimize yellow_trip_h3_12 zorder by (pickup_cell);
select
*
from
yellow_trip_h3_12
where pickup_cell is not null;
クエリ 4: H3 LGA ピックアップ - ラガーディア (LGA) からの 25M のピックアップ
use catalog geospatial_docs;
use database nyc_taxi;
create
or replace view lga_pickup_h3_12 as (
select
t.*
except(cell),
s.*
from
yellow_trip_h3_12 as s
inner join nyc_zipcode_h3_12 as t on s.pickup_cell = t.cell
where
t.zipcode = '11371'
);
select
format_number(count(*), 0) as count
from
lga_pickup_h3_12;
-- select
-- *
-- from
-- lga_pickup_h3_12;
クエリ 5: H3 金融街ドロップオフ - 金融街での合計 34M のドロップオフ
use catalog geospatial_docs;
use database nyc_taxi;
create
or replace view fd_dropoff_h3_12 as (
select
t.*
except(cell),
s.*
from
yellow_trip_h3_12 as s
inner join nyc_zipcode_h3_12 as t on s.dropoff_cell = t.cell
where
t.zipcode in ('10004', '10005', '10006', '10007', '10038')
);
select
format_number(count(*), 0) as count
from
fd_dropoff_h3_12;
-- select * from fd_dropoff_h3_12;
クエリ 6: H3 LGA-FD - LGA からピックアップし、金融街で 827K のドロップオフ
use catalog geospatial_docs;
use database nyc_taxi;
create
or replace view lga_fd_dropoff_h3_12 as (
select
*
from
fd_dropoff_h3_12
where
pickup_cell in (
select
distinct pickup_cell
from
lga_pickup_h3_12
)
);
select
format_number(count(*), 0) as count
from
lga_fd_dropoff_h3_12;
-- select * from lga_fd_dropoff_h3_12;
クエリ 7: 郵便番号による LGA-FD - 郵便番号 + 横棒グラフで、金融街でのドロップオフをカウント
use catalog geospatial_docs;
use database nyc_taxi;
select
zipcode,
count(*) as count
from
lga_fd_dropoff_h3_12
group by
zipcode
order by
zipcode;
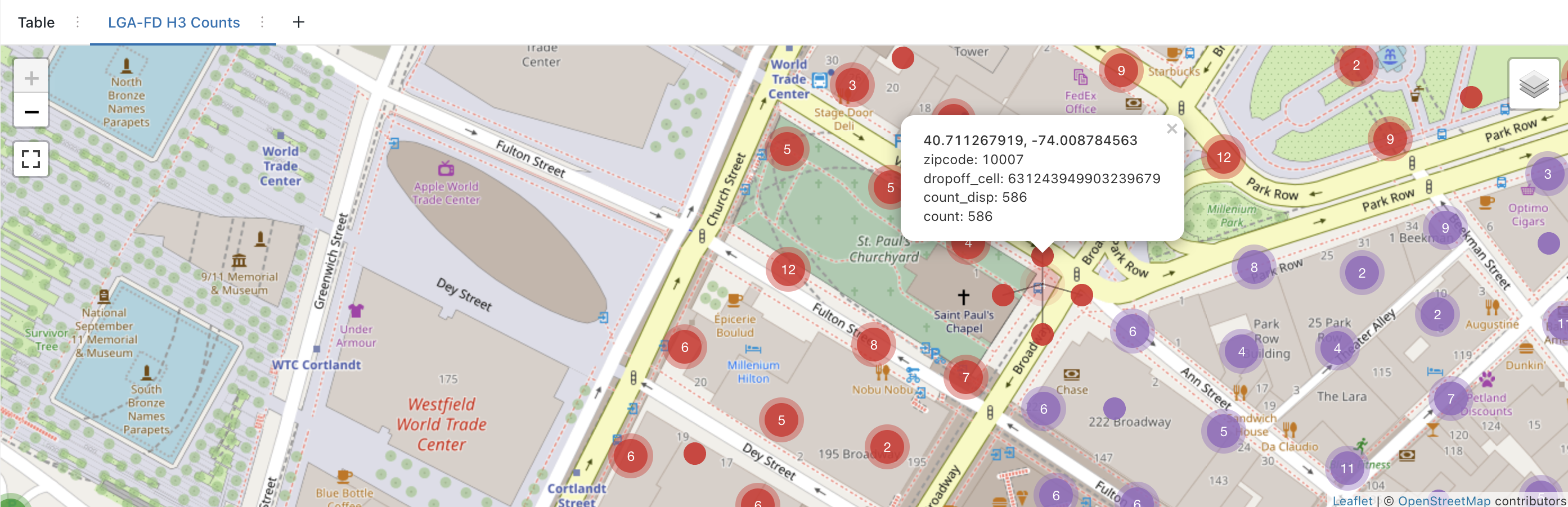
クエリ 8: H3 による LGA-FD - 金融街でのドロップオフを H3 セルによりカウント + マップ マーカーを視覚化
use catalog geospatial_docs;
use database nyc_taxi;
select
zipcode,
dropoff_cell,
h3_centerasgeojson(dropoff_cell) :coordinates [0] as dropoff_centroid_x,
h3_centerasgeojson(dropoff_cell) :coordinates [1] as dropoff_centroid_y,
format_number(count(*), 0) as count_disp,
count(*) as `count`
from
lga_fd_dropoff_h3_12
group by
zipcode,
dropoff_cell
order by
zipcode,
`count` DESC;
Databricks Runtime 11.3 LTS 以降の Notebooks
クイック スタート - Python: H3 NYC タクシー (ラガーディアからマンハッタンへ)
Notebooks + kepler.gl 内で Spark Python バインドを使用する Databricks SQL と同じクイック スタート構造です。
クイック スタート - Scala: H3 NYC タクシー (ラガーディアからマンハッタンへ)
Python セルを介して Notebooks + kepler.gl 内で Spark Scala バインドを使用する Databricks SQL と同じクイック スタート構造です。
クイック スタート - SQL: H3 NYC タクシー (ラガーディアからマンハッタンへ)
Python セルを介して Notebooks + kepler.gl 内で Spark SQL バインドを使用する Databricks SQL と同じクイック スタート構造です。