エージェント向けの MLflow トレース
重要
この機能はパブリック プレビュー段階にあります。
この記事では、Databricks 上の MLflow Tracing と、それを使用して生成 AI アプリケーションに可観測性を追加する方法について説明します。
MLflow トレースとは
MLflow Tracing は、Gen AI アプリケーションの実行に関する詳細情報をキャプチャします。 要求の各中間ステップに関連付けられている入力、出力、メタデータをトレースして、バグの原因と予期しない動作を特定できるようにします。 たとえば、モデルが幻覚を起こした場合は、その幻覚をもたらした各手順をすばやく検査できます。
MLflow Tracing は Databricks のツールとインフラストラクチャと統合されているため、Databricks ノートブックまたは MLflow 実験 UI にトレースを格納して表示できます。
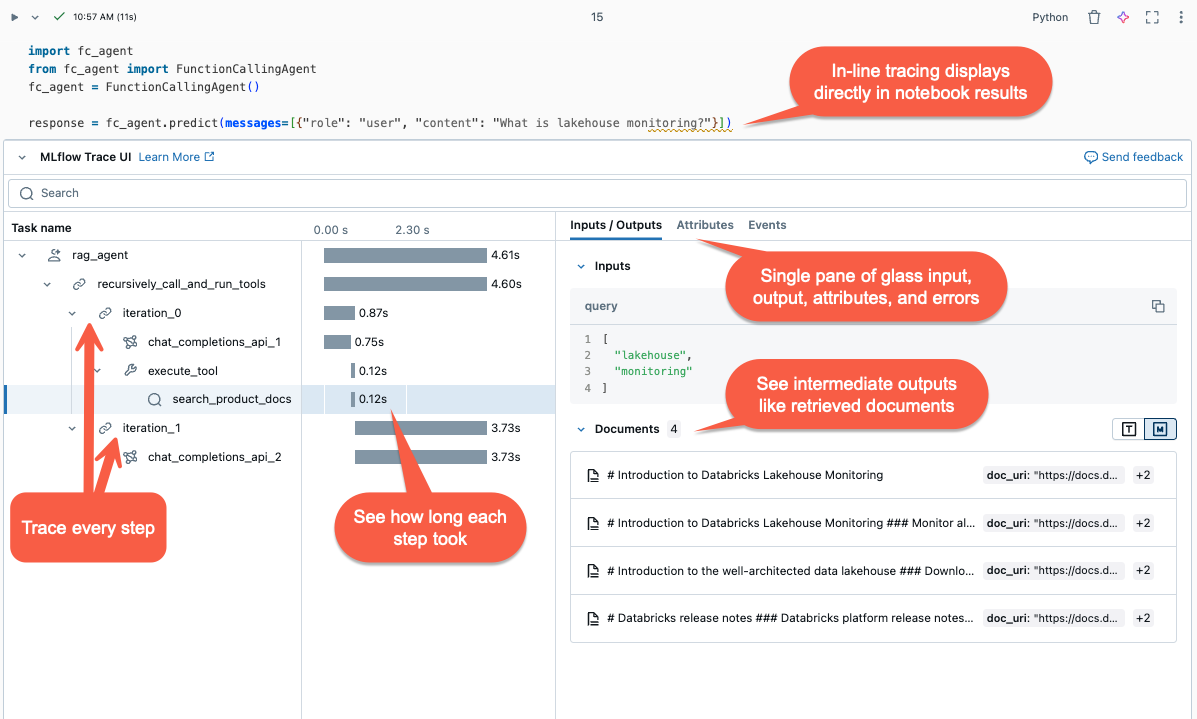
MLflow トレースを使用する理由
MLflow トレースには、いくつかの利点があります。
- 対話型トレースの視覚化を確認し、調査ツールを使用して問題を診断します。
- プロンプト テンプレートとガードレールによって適切な結果が生成されることを確認します。
- さまざまなフレームワーク、モデル、チャンク サイズの待機時間を分析します。
- さまざまなモデルでトークンの使用を測定して、アプリケーションのコストを見積もります。
- ベンチマークの "ゴールデン" データセットを確立して、さまざまなバージョンのパフォーマンスを評価します。
- 実稼働モデル エンドポイントからのトレースを格納して、問題をデバッグし、オフラインのレビューと評価を実行します。
エージェントにトレースを追加する
MLflow トレースでは、生成 AI アプリケーションにトレースを追加するための 3 つの方法がサポートされています。 API リファレンスの詳細については、「MLflow のドキュメント」を参照してください。
| API | 推奨されるユース ケース | 説明 |
|---|---|---|
| MLflow の自動ログ | 統合 GenAI ライブラリを使用した開発 | 自動ログ記録では、LangChain、LlamaIndex、OpenAI などのサポートされているオープン ソース フレームワークのトレースが自動的にログに記録されます。 |
| Fluent API | Pyfunc を使用したカスタム エージェント | トレースのツリー構造の管理を気にせずにトレースを追加するための低コード API。 MLflow は、Python スタックを使用して、適切な親子スパンリレーションシップを自動的に決定します。 |
| MLflow Client API | マルチスレッドなどの高度なユース ケース | MLflowClient では、高度なユース ケースに対して細かくスレッド セーフな API が提供されます。 スパンの親子関係を手動で管理する必要があります。 これにより、特にマルチスレッドのユース ケースに対して、トレース ライフサイクルをより適切に制御できます。 |
MLflow トレースをインストールする
MLflow トレースは MLflow バージョン 2.13.0 以降で使用できます。これは、<DBR< 15.4 LTS ML 以降にプレインストールされています。 必要に応じて、次のコードを使用して MLflow をインストールします。
%pip install mlflow>=2.13.0 -qqqU
%restart_python
または、互換性のある MLflow バージョンを含む最新バージョンの databricks-agentsをインストールすることもできます。
%pip install databricks-agents
自動ログ記録を使用してエージェントにトレースを追加する
GenAI ライブラリで LangChain や OpenAI などのトレースがサポートされている場合は、コードに mlflow.<library>.autolog() を追加して自動ログ記録を有効にします。 例えば:
mlflow.langchain.autolog()
Note
Databricks Runtime 15.4 LTS ML 以降では、ノートブック内で MLflow トレースが既定で有効になっています。 たとえば、LangChain でトレースを無効にするには、ノートブックで mlflow.langchain.autolog(log_traces=False) を実行します。
MLflow では、トレース自動ログ記録用の追加ライブラリがサポートされています。 統合ライブラリの完全な一覧については、MLflow Tracing のドキュメントを参照してください。
Fluent API を使用してエージェントにトレースを手動で追加する
MLflow の Fluent API は、コードの実行フローに基づいてトレース階層を自動的に作成します。
関数を装飾する
@mlflow.trace デコレーターを使用して、装飾された関数のスコープのスパンを作成します。
MLflow Span オブジェクト トレースステップを整理します。 スパンは、ワークフロー内の個々の操作またはステップ (API 呼び出しやベクター ストア クエリなど) に関する情報をキャプチャします。
スパンは、関数が呼び出されたときに開始され、戻ったときに終了します。 MLflow は、関数の入力と出力、および関数から発生した例外を記録します。
たとえば、次のコードでは、入力引数 xy と出力をキャプチャする、my_function という名前のスパンを作成します。
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
トレース コンテキスト マネージャーを使用する
関数だけでなく、任意のコード ブロックのスパンを作成する場合は、コード ブロックをラップするコンテキスト マネージャーとして mlflow.start_span() を使用できます。 スパンは、コンテキストが入力されたときに開始され、コンテキストが終了したときに終了します。 スパンの入力と出力は、コンテキスト マネージャーによって生成されるスパン オブジェクトのセッター メソッドを使用して手動で提供する必要があります。
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
外部関数をラップする
外部ライブラリ関数をトレースするには、関数を mlflow.traceでラップします。
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
Fluent API の例
次の例は、Fluent API mlflow.trace と mlflow.start_span を使用して quickstart-agentをトレースする方法を示しています。
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
トレースを追加した後、関数を実行します。 次に、前のセクションの predict() 関数の例を続けます。 呼び出しメソッドを実行すると、トレースが自動的に表示 predict()。
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
MLflow Client API
MlflowClient では、トレースの開始と終了、スパンの管理、スパン フィールドの設定を行うために、細かいスレッド セーフな API が公開されます。 トレースのライフサイクルと構造を完全に制御できます。 これらの API は、Fluent API がマルチスレッド アプリケーションやコールバックなどの要件に不十分な場合に役立ちます。
MLflow クライアントを使用して完全なトレースを作成する手順を次に示します。
client = MlflowClient()で MLflowClient のインスタンスを作成します。client.start_trace()メソッドを使用してトレースを開始します。 これにより、トレース コンテキストが開始され、絶対ルート スパンが開始され、ルート スパン オブジェクトが返されます。 このメソッドは、start_span()API の前に実行する必要があります。client.start_trace()でトレースの属性、入力、出力を設定します。
Note
Fluent API の
start_trace()メソッドと同等のメソッドはありません。 これは、Fluent API によってトレース コンテキストが自動的に初期化され、それがマネージド状態に基づいてルート スパンであるかどうかを判断するためです。start_trace() API はスパンを返します。
span.request_idとspan.span_idを使用して、トレースの一意識別子 (trace_idとも呼ばれます) である要求 ID と、返されたスパンの ID を取得します。client.start_span(request_id, parent_id=span_id)を使用して子スパンを開始し、スパンの属性、入力、出力を設定します。- このメソッドでは、トレース階層内の正しい位置にスパンを関連付けるために、
request_idとparent_idが必要です。 別のスパン オブジェクトを返します。
- このメソッドでは、トレース階層内の正しい位置にスパンを関連付けるために、
client.end_span(request_id, span_id)を呼び出して、子スパンを終了します。作成するすべての子スパンに対してステップ 3 から 5 を繰り返します。
すべての子スパンが終了したら、
client.end_trace(request_id)を呼び出してトレースを終了し、それを記録します。
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
トレースを確認
エージェントの実行後にトレースを確認するには、次のいずれかのオプションを使用します。
- トレース視覚エフェクトは、セル出力にインラインでレンダリングされます。
- トレースは MLflow 実験に記録されます。 実験 ページの トレース タブで、履歴トレースの完全な一覧を確認および検索できます。 アクティブな MLflow 実行でエージェントが実行されると、トレースが 実行 ページに表示されます。
- search_traces() API を使用してプログラムでトレースを取得します。
本番環境で MLflow トレースを使用する
また、MLflow Tracing は Mosaic AI モデル Serving と統合されているため、問題を効率的にデバッグし、パフォーマンスを監視し、オフライン評価用のゴールデン データセットを作成できます。 MLflow トレースがサービス エンドポイントで有効になっている場合、トレースは 列の下の response に記録されます。
テーブルにクエリを実行し、結果をノートブックに表示することで、推論テーブルに記録されたトレースを視覚化できます。 ノートブックで display(<the request logs table>) を使用し、視覚化するトレースの個々の行を選択します。
サービス エンドポイントの MLflow トレースを有効にするには、エンドポイント構成の ENABLE_MLFLOW_TRACING 環境変数を True に設定する必要があります。 カスタム環境変数を使用してエンドポイントをデプロイする方法については、「プレーンテキスト環境変数を追加する」を参照してください。 deploy() API を使用してエージェントをデプロイした場合、トレースは自動的に推論テーブルに記録されます。 「生成 AI アプリケーション用にエージェントをデプロイする」を参照してください。
Note
推論テーブルへのトレースの書き込みは非同期的に行われるので、開発中のノートブック環境と同じオーバーヘッドは追加されません。 ただし、特に各推論要求のトレース サイズが大きい場合、エンドポイントの応答速度にオーバーヘッドが発生する可能性があります。 Databricks は、環境とモデルの実装に大きく依存しているため、モデル エンドポイントに対する実際の待機時間への影響に関するサービス レベル アグリーメント (SLA) を保証しません。 Databricks では、運用アプリケーションにデプロイする前に、エンドポイントのパフォーマンスをテストし、トレースのオーバーヘッドに関する分析情報を得ることをお勧めします。
次の表は、さまざまなトレース サイズの推論待機時間への影響を大まかに示しています。
| 要求あたりのトレース サイズ | 待機時間への影響 (ms) |
|---|---|
| ~ 10 KB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
制限事項
- MLflow トレースは、Databricks ノートブック、ノートブック ジョブ、Model Serving で使用できます。
LangChain の自動ログは、すべての LangChain 予測 API をサポートしているわけではありません。 サポートされている API の完全な一覧については、MLflow のドキュメントを参照してください。