モデルの監視とデバッグのための推論テーブル
重要
この機能はパブリック プレビュー段階にあります。
重要
この記事では、カスタム モデルの推論テーブル
この記事では、提供されたモデルを監視するための推論テーブルについて説明します。 次の図は、推論テーブルを使った一般的なワークフローを示しています。 推論テーブルは、モデル提供エンドポイントの受信要求と送信応答を自動的に取り込み、Unity Catalog Delta テーブルとしてそれらをログします。 このテーブルのデータを使って、ML モデルを監視、デバッグ、改善することができます。
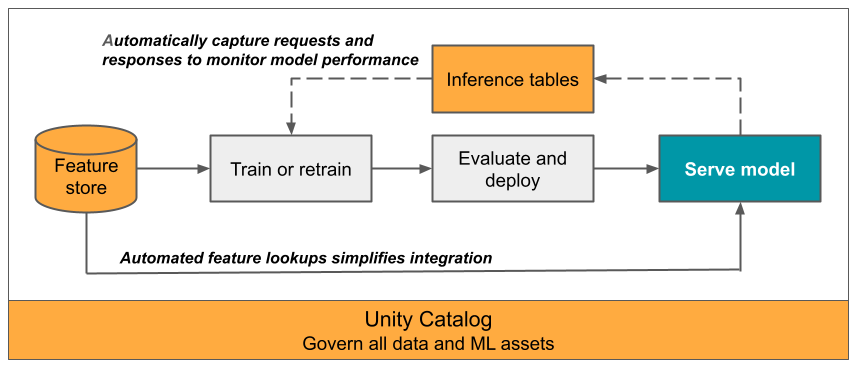
推論テーブルとは?
運用環境ワークフローでモデルのパフォーマンスを監視することは、AI および ML モデルのライフサイクルの重要な側面です。 推論テーブルは、Mosaic AI Model Serving エンドポイントから提供される要求の入力と応答 (予測) を継続的にログし、Unity Catalog の Delta テーブルにそれらを保存することで、モデルの監視と診断を簡略化しています。 これで、Databricks SQL クエリ、ノートブック、レイクハウス監視など、Databricks プラットフォームのすべての機能を使って、モデルの監視、デバッグ、最適化を実行できるようになります。
既存の、または新規作成したモデル提供エンドポイント上で推論テーブルを有効にすると、そのエンドポイントへの要求は UC のテーブルに自動的にログされます。
推論テーブルの一般的な用途を次に示します。
- データとモデルの品質を監視します。 Lakehouse Monitoring を使うと、モデルのパフォーマンスとデータ ドリフトを継続的に監視できます。 Lakehouse Monitoring により、関係者と共有できるデータとモデルの品質ダッシュボードが自動的に生成されます。 さらに、受信データの変化やモデルのパフォーマンス低下に基づいてモデルの再トレーニングが必要なタイミングを通知するアラートを有効にすることもできます。
- 運用環境の問題をデバッグします。 推論テーブルは、HTTP 状態コード、モデルの実行時間、要求と応答の JSON コードなどのデータをログします。 このパフォーマンス データは、デバッグ目的で使用できます。 推論テーブルの履歴データを使って、過去の要求に対するモデルのパフォーマンスを比較することもできます。
- トレーニング コーパスを作成します。 推論テーブルを実測値ラベルと結合することで、モデルの再トレーニングや微調整、改善に使用できるトレーニング コーパスを作成できます。 Databricks ジョブを使うと、継続的なフィードバック ループを設定して、再トレーニングを自動化できます。
要件
- ワークスペースで Unity カタログが有効になっている必要があります。
- エンドポイントの作成者と修飾子の両方に、エンドポイントに対する管理可能アクセス許可が必要です。 「アクセス制御リスト」を参照してください。
- エンドポイントの作成者と修飾子の両方に、Unity Catalog における次のアクセス許可が必要です:
- 指定したカタログに対する
USE CATALOGアクセス許可。 - 指定したスキーマに対する
USE SCHEMAアクセス許可。 - スキーマ内の
CREATE TABLEアクセス許可。
- 指定したカタログに対する
推論テーブルの有効化と無効化
このセクションでは、Databricks UI を使って推論テーブルを有効または無効にする方法を示します。 API を使うこともできます。手順については、「API を使用してモデル提供エンドポイントで推論テーブルを有効にする」を参照してください。
推論テーブルの所有者は、エンドポイントを作成したユーザーです。 テーブルのすべてのアクセス制御リスト (ACL) は、標準の Unity カタログのアクセス許可に従い、テーブル所有者が変更できます。
警告
次のいずれかの操作を行うと、推論テーブルが破損する可能性があります。
- テーブル スキーマを変更する。
- テーブル名を変更する。
- テーブルを削除する。
- Unity カタログ カタログやスキーマへのアクセス許可が失われます。
この場合、エンドポイント ステータスの auto_capture_config には、ペイロード テーブルの FAILED ステータスが表示されます。 その場合は、推論テーブルを引き続き使うために新しいエンドポイントを作成する必要があります。
エンドポイントの作成時に推論テーブルを有効にするには、次の手順に従います。
Databricks Mosaic AI UI の[サービング] をクリックします。
[提供エンドポイントの作成] をクリックします。
[Enable inference table] (推論テーブルを有効にする) を選びます。
ドロップダウン メニューで、テーブルを配置する場所のカタログとスキーマを選びます。
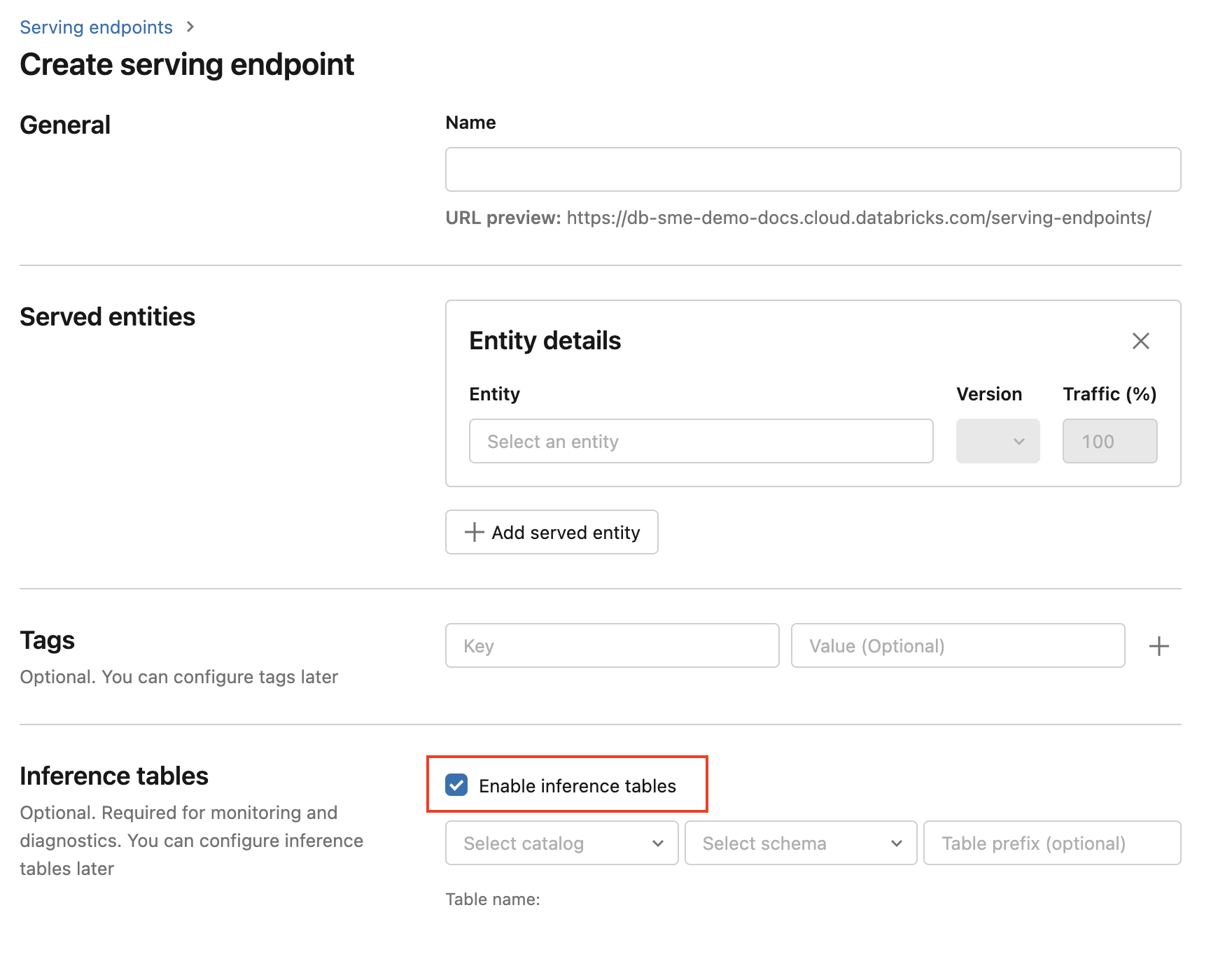
既定のテーブル名は
<catalog>.<schema>.<endpoint-name>_payloadです。 必要に応じて、カスタムのテーブル プレフィックスを入力できます。[提供エンドポイントの作成] をクリックします。
また、既存のエンドポイントの推論テーブルを有効にすることもできます。 既存のエンドポイント構成を編集するには、次の操作を行います。
- エンドポイント ページに移動します。
- [構成の編集] をクリックします。
- 前の手順の手順 3 以降を実行します。
- 完了したら、[Update serving endpoint] (提供エンドポイントの更新) をクリックします。
以下の手順に従って推論テーブルを無効にします。
- エンドポイント ページに移動します。
- [構成の編集] をクリックします。
- [Enable inference table] (推論テーブルを有効にする) をクリックしてチェックマークをオフにします。
- エンドポイントの指定に問題がなければ、[更新] をクリックします。
ワークフロー: 推論テーブルを使ってモデルのパフォーマンスを監視する
推論テーブルを使ってモデルのパフォーマンスを監視するには、次の手順を実行します。
- エンドポイントの作成中にエンドポイントの推論テーブルを有効にします。あるいは後で更新して有効にします。
- エンドポイントのスキーマに従ってアンパックすることで、推論テーブル内の JSON ペイロードを処理するようにワークフローをスケジュールします。
- (省略可能) アンパックされた要求と応答をグラウンド トゥルース ラベルと結合して、モデル品質メトリックを計算できるようにします。
- 結果的に生成される Delta テーブルに対してモニターを作成し、メトリックを更新します。
スターター ノートブックはこのワークフローを実装しています。
推論テーブルを監視するためのスターター ノートブック
次のノートブックは、Lakehouse Monitoring 推論テーブルからの要求をアンパックするために、上記の手順を実装しています。 ノートブックは、オンデマンドで、または Databricks ジョブを使って定期的なスケジュールで実行できます。
推論テーブル Lakehouse Monitoring スターター ノートブック
LLM を提供するエンドポイントからのテキスト品質を監視するためのスターター ノートブック
次のノートブックを使って、推論テーブルから要求をアンパックし、一連のテキスト評価メトリック (読みやすさや有害性など) を計算し、これらのメトリックを監視できるようにします。 ノートブックは、オンデマンドで、または Databricks ジョブを使って定期的なスケジュールで実行できます。
LLM 推論テーブル Lakehouse Monitoring スターター ノートブック
推論テーブルで結果のクエリと分析を行う
サービス モデルの準備ができると、モデルに対して行われたすべての要求が応答と共に推論テーブルに自動的に記録されます。 UI でテーブルを表示する、DBSQL またはノートブックからテーブルのクエリを実行する、または REST API を使ってテーブルのクエリを実行することができます。
UI でテーブルを表示するには: エンドポイント ページで推論テーブルの名前をクリックし、カタログ エクスプローラーでテーブルを開きます。

DBSQL または Databricks ノートブックからテーブルのクエリを実行するには: 次のようなコードを実行して、推論テーブルのクエリを実行できます。
SELECT * FROM <catalog>.<schema>.<payload_table>
UI を使って推論テーブルを有効にした場合、payload_table はエンドポイントの作成時に割り当てたテーブル名です。 API を使って推論テーブルを有効にした場合、payload_table は state 応答の auto_capture_config セクションで報告されます。 例については、「API を使用してモデル提供エンドポイントで推論テーブルを有効にする」を参照してください。
パフォーマンスに関するメモ
エンドポイントを呼び出した後、スコア付け要求を送信してから 1 時間以内に、推論テーブルにその呼び出しが記録されるのを確認できます。 さらに、Azure Databricks では最低 1 回のログ配信が保証されているため、重複するログが送信される可能性はほとんどありません。
Unity カタログ推論テーブル スキーマ
推論テーブルに記録される各要求と応答は、次のスキーマを使用して Delta テーブルに書き込まれます:
Note
入力のバッチを使用してエンドポイントを呼び出すと、バッチ全体が 1 つの行としてログに記録されます。
| 列名 | 説明 | Type |
|---|---|---|
databricks_request_id |
Azure Databricks によって生成された要求識別子は、要求を処理するすべてのモデルにアタッチされます。 | STRING |
client_request_id |
モデル サービス要求本文で指定できる、オプションのクライアント生成の要求識別子。 詳細については、「client_request_id の指定」を参照してください。 |
STRING |
date |
モデル サービス要求を受信した UTC 日付。 | DATE |
timestamp_ms |
要求をサービス提供するモデルが受信されたときのタイムスタンプ (エポック ミリ秒)。 | LONG |
status_code |
モデルから返された HTTP 状態コード。 | INT |
sampling_fraction |
要求がダウンサンプリングされた場合に使用されるサンプリング率。 この値は 0 ~ 1 の間になります。1 は、受信要求の 100% が含まれていることを表します。 | DOUBLE |
execution_time_ms |
モデルが推論を実行した実行時間 (ミリ秒単位)。 これには、オーバーヘッド ネットワーク待機時間は含まれません。また、モデルが予測を生成するのにかかった時間のみを表します。 | LONG |
request |
モデル サービス エンドポイントに送信された未加工の要求 JSON 本文。 | STRING |
response |
モデル サービス エンドポイントによって返された未加工の応答 JSON 本文。 | STRING |
request_metadata |
要求に関連付けられたモデル サービス エンドポイントに関連するメタデータのマップ。 このマップには、エンドポイントに使用されるエンドポイント名、モデル名、およびモデル バージョンが含まれています。 | MAP<STRING、STRING> |
指定 client_request_id
client_request_id フィールドは、モデル サービス要求本文でユーザーが指定できる省略可能な値です。 ユーザーは、このフィールドを使って client_request_id の下にある最終的な推論テーブルに表示される要求に対して独自の識別子を指定でき、client_request_idを使用する他のテーブル (グラウンド トゥルース ラベルの結合など) と要求を結合することができます。 client_request_id を指定するには、要求ペイロードの最上位キーとして含めます。 client_request_id を指定しない場合、値は要求に対応する行に null として表示されます。
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
その後、client_request_id に関連付けられたラベルを持つ他のテーブルがある場合に、client_request_id をグラウンド トゥルース ラベル結合に使用できます。
制限事項
- カスタマー マネージド キーはサポートされていません。
- 基盤モデルをホストするエンドポイントの場合、推論テーブルは、プロビジョニングされたスループット ワークロードでのみサポートされます。
- Azure Firewall では Unity カタログ デルタ テーブルの作成に失敗する可能性があるため、既定ではサポートされていません。 有効化が必要な場合は、Databricks アカウント チームにお問い合わせください。
- 推論テーブルが有効な場合、単一のエンドポイントで提供されるすべてのモデルの合計最大コンカレンシーの制限は 128 です。 この制限の引き上げを依頼するには、Azure Databricks アカウント チームにお問い合わせください。
- 推論テーブルに 500,000 個を超えるファイルが含まれている場合、追加のデータはログされません。 この制限を超えないようにするには、OPTIMIZE を実行するか、古いデータを削除してテーブルのリテンション期間を設定します。 テーブル内のファイルの数を確認するには、
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>を実行します。 - 推論テーブルのログ配信は現在ベストエフォート方式で行われていますが、要求から 1 時間以内にログを使用できます。 詳細については、Databricks アカウント チームにお問い合わせください。
一般的なモデル提供エンドポイントの制限については、「モデル提供の制限とリージョン」を参照してください。