RAG データ パイプラインの説明と処理のステップ
この記事では、RAG アプリケーションで使用するための非構造化データの準備について学習します。 非構造化データとは、テキストや画像を含む可能性のある PDF ドキュメントや、オーディオやビデオなどのマルチメディア コンテンツなど、特定の構造や構成を持たないデータを指します。
非構造化データには定義済みのデータ モデルやスキーマがないため、構造とメタデータのみに基づいてクエリを実行することはできません。 そのため、非構造化データには、未加工のテキスト、画像、オーディオ、またはその他のコンテンツからセマンティックの意味を理解して抽出できる手法が必要になります。
データの準備中、RAG アプリケーション データ パイプラインは、未加工の非構造化データを受け取り、ユーザーのクエリとの関連性に基づいてクエリを実行できる個別のチャンクに変換します。 データの前処理の主なステップを次に示します。 各ステップには、調整可能なさまざまなノブがあります。これらのノブに関する詳細な説明については、「RAG アプリケーションの品質の概要」をご覧ください。
取得のために非構造化データを準備する
このセクションの残りの部分では、セマンティック検索を使用して非構造化データを取得用に準備するプロセスについて説明します。 セマンティック検索は、ユーザー クエリのコンテキスト上の意味と意図を理解し、より関連性の高い検索結果を提供します。
セマンティック検索は、非構造化データに対して RAG アプリケーションの取得コンポーネントを実装するときに使用できるいくつかのアプローチの 1 つです。 これらのドキュメントでは、取得ノブのセクションで代替の取得戦略について説明しています。
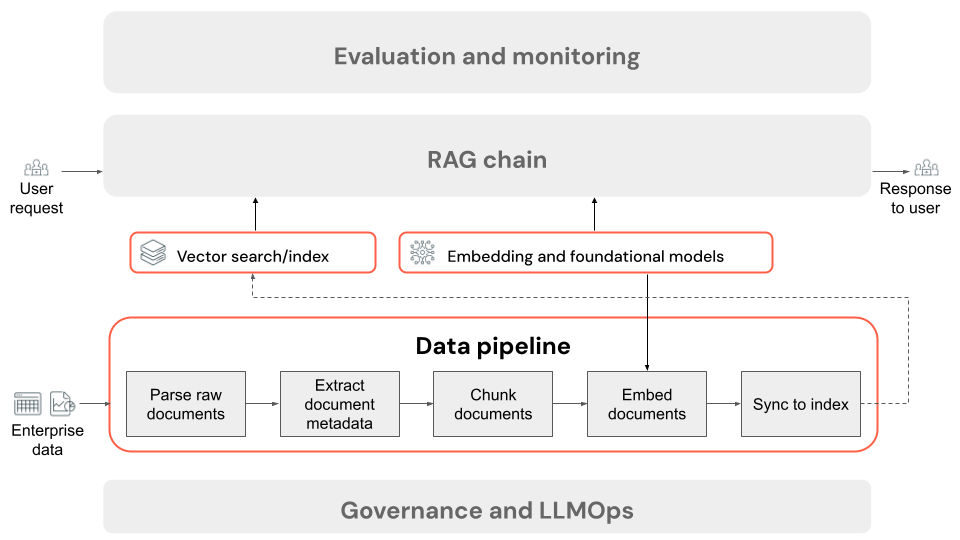
RAG アプリケーション データ パイプラインのステップ
非構造化データを使用する RAG アプリケーションのデータ パイプラインの一般的なステップを次に示します。
- 生のドキュメントを解析する: 最初のステップでは、生データを使用可能な形式に変換します。 これには、PDF のコレクションからテキスト、表、画像を抽出したり、光学式文字認識 (OCR) 技術を使用して画像からテキストを抽出したりすることが含まれます。
- ドキュメント メタデータを抽出する (省略可能): 場合によっては、ドキュメント タイトル、ページ番号、URL、その他の情報などのドキュメント メタデータを抽出して使用すると、取得ステップで正しいデータをより正確に照会できます。
- ドキュメントをチャンク化する: 解析されたドキュメントが埋め込みモデルと LLM のコンテキスト ウィンドウに収まるように、解析されたドキュメントをより小さな個別のチャンクに分割します。 ドキュメント全体ではなく、これらの焦点を絞ったチャンクを取得すると、応答を生成するためのよりターゲットを絞ったコンテキストが LLM に提供されます。
- チャンクの埋め込み: セマンティック検索を使用する RAG アプリケーションでは、埋め込みモデルと呼ばれる特殊な種類の言語モデルによって、前のステップのチャンクが数値ベクトルまたは数値のリストにそれぞれ変換され、コンテンツの各部分の意味がカプセル化されます。 重要なのは、これらのベクトルが表面的なキーワードだけでなく、テキストのセマンティックな意味を表していることです。 これにより、リテラル テキストの一致ではなく、意味に基づいた検索が可能になります。
- ベクトル データベースのチャンクにインデックスを付ける: 最後のステップでは、チャンクのベクトル表現をチャンクのテキストとともにベクトル データベースに読み込みます。 ベクトル データベースは、埋め込みなどのベクトル データを効率的に保存および検索するために設計された特殊な種類のデータベースです。 多数のチャンクでパフォーマンスを維持するために、ベクトル データベースには、通常、検索効率を最適化する方法でベクトル埋め込みを整理およびマップするためにさまざまなアルゴリズムを使用するベクトル インデックスが含まれています。 クエリ時に、ユーザーの要求がベクトルに埋め込まれ、データベースはベクトル インデックスを利用して最も類似したチャンク ベクトルを見つけし、対応する元のテキスト チャンクを返します。
類似性を計算するプロセスは、計算コストが高くなる可能性があります。 Databricks Vector Search などのベクトル インデックスは、多くの場合、高度な近似法を使用して埋め込みを効率的に整理およびナビゲートするためのメカニズムを提供して、このプロセスを高速化しています。 これにより、各埋め込みをユーザーのクエリと個別に比較することなく、最も関連性の高い結果を迅速にランク付けできます。
データ パイプラインの各ステップには、RAG アプリケーションの品質に影響を与えるエンジニアリング上の決定が含まれます。 たとえば、ステップ 3 で適切なチャンク サイズを選択すると、LLM は特定のコンテキスト化された情報を確実に受け取り、ステップ 4 で適切な埋め込みモデルを選択すると、取得時に返されるチャンクの精度が決まります。
このデータ準備プロセスは、ユーザーがクエリを送信したときにトリガーされるオンライン ステップとは異なり、システムがクエリに応答する前に実行されるため、オフライン データ準備と呼ばれます。