推論用の RAG チェーン
この記事では、ユーザーがオンライン設定で RAG アプリケーションに要求を送信したときに行われるプロセスについて説明します。 データ パイプラインによる処理が済んだデータは、RAG アプリケーションでの使用に適しています。 推論時に呼び出される一連のステップつまりチェーンは、一般に "RAG チェーン" と呼ばれます。
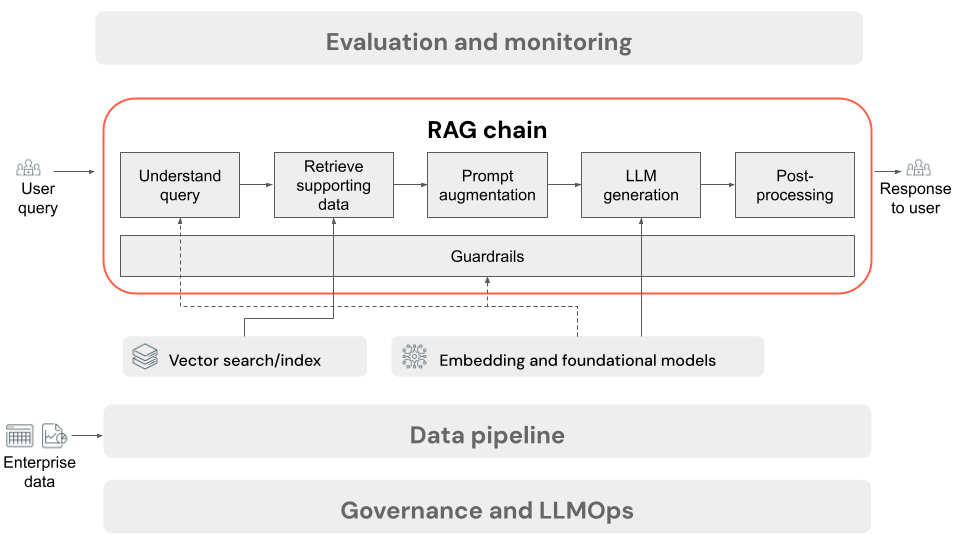
- (オプション) ユーザー クエリの前処理: 場合によっては、ベクトル データベースのクエリにいっそう適したものにするため、ユーザー クエリが前処理されます。 これには、テンプレート内でのクエリの書式設定、別のモデルを使った要求の書き換え、検索に役立つキーワードの抽出が含まれる場合があります。 このステップの出力は、後の取得ステップで使われる取得クエリです。
- 取得: ベクトル データベースからサポート情報を取得するため、取得クエリは、データ準備中にドキュメント チャンクを埋め込むために使われたのと同じ埋め込みモデルを使って、埋め込みに変換されます。 これらの埋め込みにより、コサイン類似度などの尺度を使って、取得クエリと非構造化テキスト チャンクの間のセマンティック類似性を比較できます。 次に、チャンクがベクター データベースから取得され、埋め込まれた要求とどの程度似ているかに基づいてランク付けされます。 上位の (最も似ている) 結果が返されます。
- プロンプト拡張: LLM に送信されるプロンプトは、各コンポーネントの使用方法をモデルに指示するテンプレートにおいて (多くの場合、応答形式を制御するための追加の指示があります)、取得されたコンテキストを使ってユーザー クエリを拡張することで形成されます。 使用する適切なプロンプト テンプレートを反復処理するプロセスは、プロンプト エンジニアリングと呼ばれます。
- LLM 生成: LLM は拡張されたプロンプトを受け取ります。これには、ユーザーのクエリと、取得されたサポート データが入力として含まれます。 その後、追加のコンテキストに基づいて応答が生成されます。
- (オプション) 後処理: LLM の応答は、さらに処理されて、追加のビジネス ロジックの適用、引用の追加、定義済みのルールや制約に基づく生成されたテキストの調整が行われる場合があります。
RAG アプリケーション データ パイプラインと同様に、RAG チェーンの品質に影響を与える可能性のある、エンジニアリングに関する多くの重要な決定があります。 たとえば、ステップ 2 で取得するチャンクの数や、それらをステップ 3 でユーザーのクエリと組み合わせる方法に関する決定は、高品質の応答を生成するモデルの機能に大きく影響する可能性があります。
チェーン全体を通して、エンタープライズ ポリシーに確実に準拠するためのさまざまなガードレールを適用できます。 これには、適切な要求のためのフィルター処理、データ ソースにアクセスする前のユーザーのアクセス許可の確認、生成された応答に対するコンテンツ モデレーション手法の適用が含まれる場合があります。