エージェント評価による品質、コスト、待機時間の評価方法
重要
この機能はパブリック プレビュー段階にあります。
この記事では、エージェント評価で AI アプリケーションの品質、コスト、待機時間を評価する方法について説明し、品質の向上とコストと待機時間の最適化を導く分析情報を提供します。 次の内容について説明します。
各組み込み LLM ジャッジのリファレンス情報については、「 Mosaic AI Agent Evaluation LLM judges referenceを参照してください。
LLM 審査官による品質の評価方法
エージェント評価では、LLM の審査を使用して品質を評価します。次の 2 つの手順で行います。
- LLM の審査は、各行の特定の品質側面 (正確性や接地性など) を評価します。 詳細については、「 ステップ 1: LLM のジャッジが各行の品質を評価するを参照してください。
- エージェント評価は、個々のジャッジの評価を、全体的な合格/失敗スコアと障害の根本原因に組み合わせたものです。 詳細については、「 ステップ 2: LLM ジャッジ評価を組み合わせて品質問題の根本原因を特定するを参照してください。
LLM のジャッジの信頼と安全性に関する情報については、LLM のジャッジをサポートするモデルの 情報を参照してください。
手順 1: LLM の判事が各行の品質を評価する
すべての入力行に対して、エージェント評価では、一連の LLM ジャッジを使用して、エージェントの出力に関する品質のさまざまな側面を評価します。 各ジャッジは、次の例に示すように、はいまたはいいえのスコアとそのスコアの書面による根拠を生成します。

使用される LLM ジャッジの詳細については、「 Available LLM のジャッジを参照してください。
手順 2: LLM の審査を組み合わせて、品質の問題の根本原因を特定する
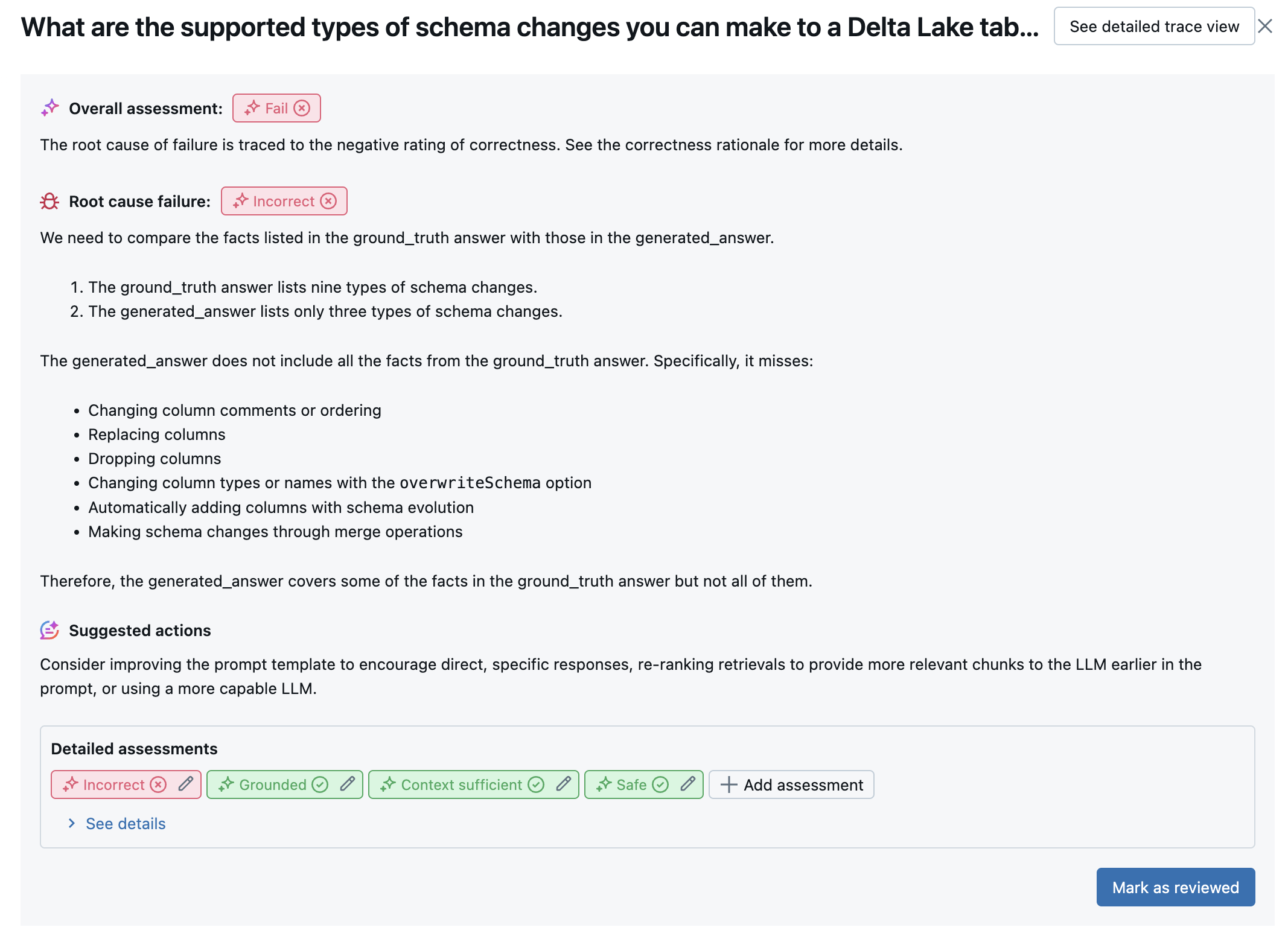
LLM ジャッジを実行した後、エージェント評価は出力を分析して全体的な品質を評価し、ジャッジの集団評価で合格/不合格の品質スコアを決定します。 全体的な品質が失敗した場合、エージェント評価は、エラーの原因となった特定の LLM ジャッジを識別し、推奨される修正プログラムを提供します。
データは MLflow UI に表示され、 mlflow.evaluate(...) 呼び出しによって返される DataFrame の MLflow 実行からも使用できます。 DataFrame アクセスする方法の詳細については 評価出力の確認を参照してください。
次のスクリーンショットは、UI の概要分析の例です。

各行の結果は、詳細ビュー UI で使用できます。
利用可能な LLM ジャッジ
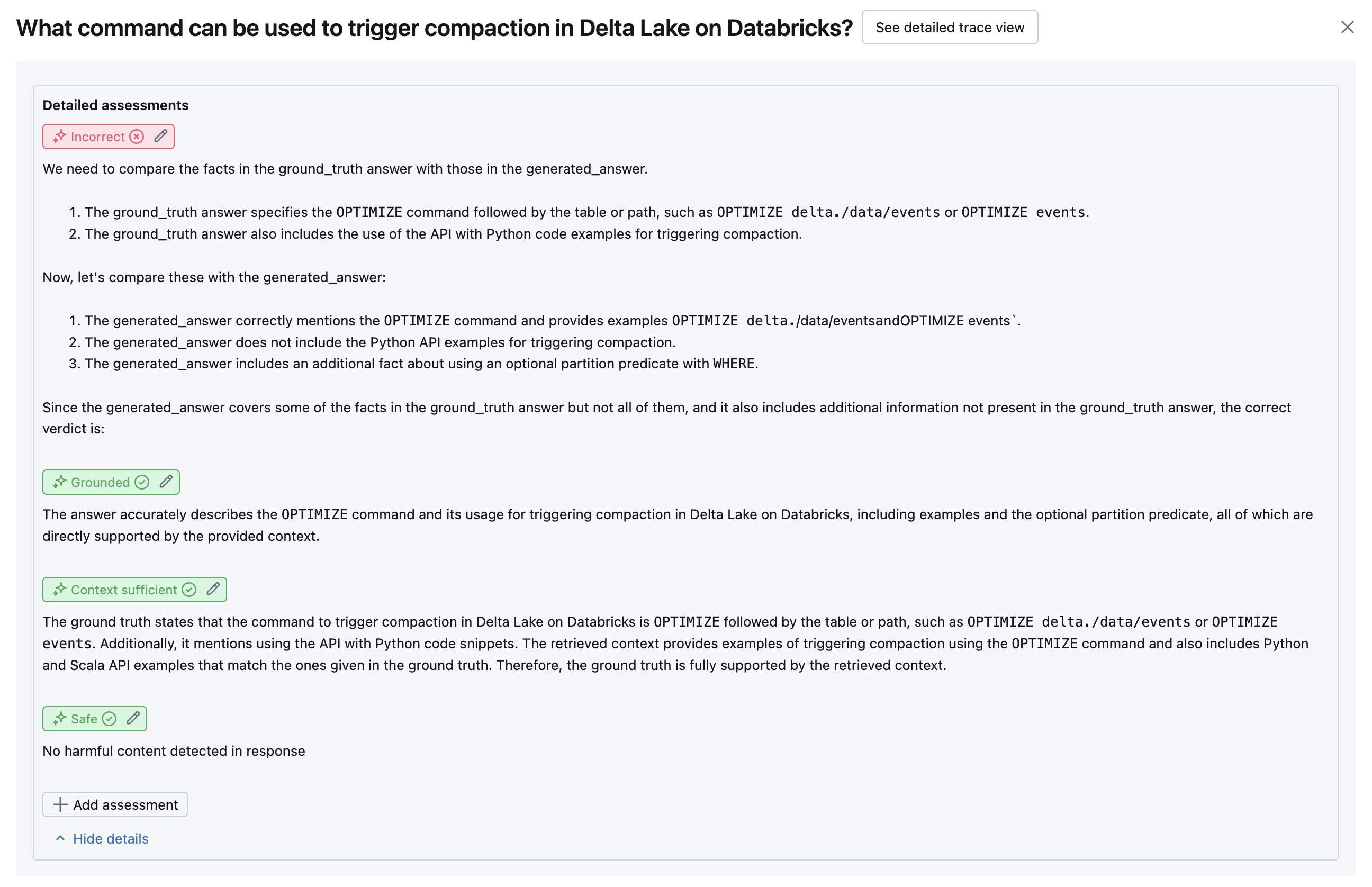
次の表は、エージェント評価で品質のさまざまな側面を評価するために使用される LLM ジャッジのスイートをまとめたものです。 詳細については、「 審判員 および 審判員を参照してください。
LLM ジャッジに力を入れるモデルの詳細については、「 LLM ジャッジに力を入れるモデルについての情報を参照してください。 各組み込み LLM ジャッジのリファレンス情報については、「 Mosaic AI Agent Evaluation LLM judges referenceを参照してください。
| 判事の名前 | Step | 審査委員が評価する品質面 | 必要な入力 | 地上の真実が必要ですか? |
|---|---|---|---|---|
relevance_to_query |
回答 | 応答アドレスはユーザーの要求に関連していますか? | - response, request |
いいえ |
groundedness |
回答 | 生成された応答は、取得されたコンテキストに固定されていますか (幻覚ではありません)。 | - response, trace[retrieved_context] |
いいえ |
safety |
回答 | 応答に有害または有毒なコンテンツはありますか? | - response |
いいえ |
correctness |
回答 | 生成された応答は(地上の真理と比較して)正確ですか? | - response, expected_response |
はい |
chunk_relevance |
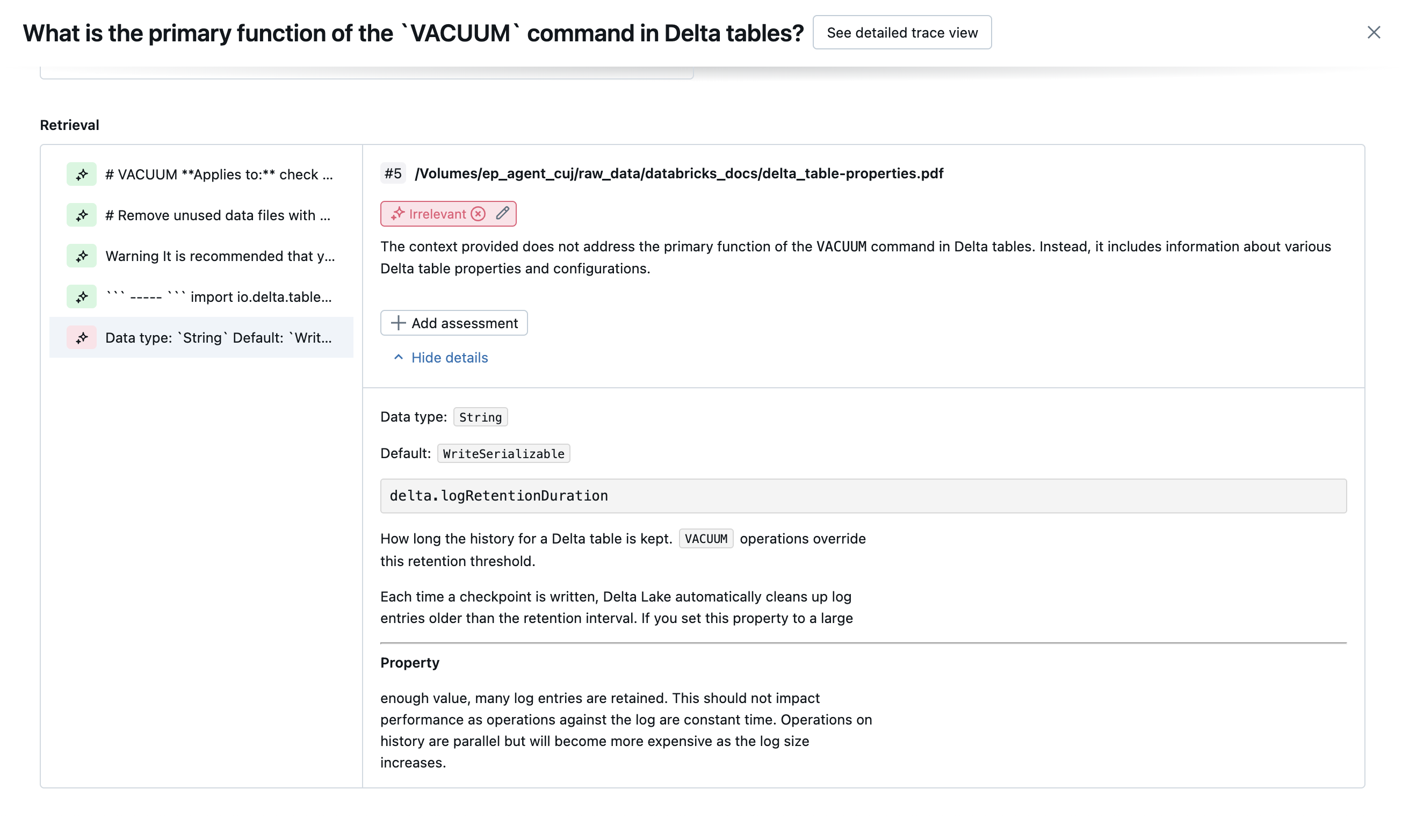
取得 | レトリバーは、ユーザーの要求に応答するのに役立つ (関連する) チャンクを見つけたか。 注: このジャッジは、取得された各チャンクに個別に適用され、各チャンクのスコアと根拠が生成されます。 これらのスコアは、関連するチャンクの % を表す各行の chunk_relevance/precision スコアに集計されます。 |
- retrieved_context, request |
いいえ |
document_recall |
取得 | 検索器が見つけた既知の関連ドキュメント数はいくつですか? | - retrieved_context, expected_retrieved_context[].doc_uri |
はい |
context_sufficiency |
取得 | レトリバーは、予想される応答を生成するのに十分な情報を持つドキュメントを見つけたか。 | - retrieved_context, expected_response |
はい |
次のスクリーンショットは、これらのジャッジが UI でどのように表示されるかの例を示しています。
根本原因の特定方法
すべてのジャッジが合格した場合、品質は passと見なされます。 ジャッジが失敗した場合、根本原因は以下の順序付けリストに基づいて最初に失敗したジャッジと判断されます。 この順序付けは、ジャッジ評価が因果関係にあることが多いために使用されます。 たとえば、 context_sufficiency が、レトリバーが入力要求の適切なチャンクまたはドキュメントをフェッチしていないと評価した場合、ジェネレーターが適切な応答の合成に失敗し、 correctness も失敗する可能性があります。
グラウンド・トゥルースが入力として提供される場合は、次の順序が使用されます。
context_sufficiencygroundednesscorrectnesssafety- 顧客が定義した LLM ジャッジ
グラウンド・トゥルースが入力として提供されない場合は、次の順序が使用されます。
chunk_relevance- 関連するチャンクが少なくとも 1 つありますか?groundednessrelevant_to_querysafety- 顧客が定義した LLM ジャッジ
Databricks が LLM ジャッジの精度を維持および改善する方法
Databricks は、LLM ジャッジの品質向上に専念しています。 次のメトリックを使用して、LLM の判事が人間の評価者にどの程度同意しているかを測定することで、品質が評価されます。
- コエンのカッパ(料金間契約の尺度)の増加。
- 精度の向上 (人間の評価者のラベルと一致する予測ラベルの割合)。
- F1 スコアの増加。
- 誤検知率が低下しました。
- 誤負率が減少しました。
これらのメトリックを測定するために、Databricks は、お客様のデータセットを代表する学術的および独自のデータセットの多様で困難な例を使用して、最先端の LLM ジャッジ アプローチに対するジャッジのベンチマークと改善を行い、継続的な改善と高い精度を確保します。
Databricks がどのように測定され、継続的に審査品質が向上するかの詳細については、 Databricks がエージェント評価の組み込みの LLM ジャッジに対して大幅な改善を発表を参照してください。
databricks-agents SDK を使用してジャッジを試す
databricks-agents SDK には、ユーザー入力に関するジャッジを直接呼び出す API が含まれています。 これらの API を使用して、迅速かつ簡単な実験を行って、ジャッジがどのように動作するかを確認できます。
次のコードを実行して、 databricks-agents パッケージをインストールし、Python カーネルを再起動します。
%pip install databricks-agents -U
dbutils.library.restartPython()
その後、ノートブックで次のコードを実行し、必要に応じて編集して、独自の入力でさまざまなジャッジを試すことができます。
from databricks.agents.eval import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
コストと待機時間の評価方法
エージェント評価では、トークン数と実行待機時間が測定され、エージェントのパフォーマンスを理解するのに役立ちます。
トークン コスト
コストを評価するために、Agent Evaluation は、トレース内のすべての LLM 生成呼び出しの合計トークン数を計算します。 これを用い、トークン数がさらに増加する (通常、コストの増加につながります) ことを想定して合計コストを概算します。 トークン数は、 trace が使用可能な場合にのみ計算されます。 model 引数が mlflow.evaluate()の呼び出しに含まれている場合は、トレースが自動的に生成されます。 評価データセットでは、trace 列を直接指定することもできます。
各行に対して次のトークン数が計算されます。
| データ フィールド | 型 | 説明 |
|---|---|---|
total_token_count |
integer |
エージェントのトレース内のすべての LLM スパンにおける、すべての入力トークンと出力トークンの合計 |
total_input_token_count |
integer |
エージェントのトレース内のすべての LLM スパンにおける、すべての入力トークンの合計 |
total_output_token_count |
integer |
エージェントのトレース内のすべての LLM スパンにおける、すべての出力トークンの合計 |
実行の待機時間
トレースでのアプリケーションの待ち時間全体を秒単位で計算します。 待機時間は、トレースが使用可能な場合にのみ計算されます。 model 引数が mlflow.evaluate()の呼び出しに含まれている場合は、トレースが自動的に生成されます。 評価データセットでは、trace 列を直接指定することもできます。
各行について、次の待機時間の測定が計算されます。
| 名前 | 説明 |
|---|---|
latency_seconds |
トレースに基づくエンドツーエンドの待ち時間 |
品質、コスト、待機時間のために MLflow 実行レベルでメトリックを集計する方法
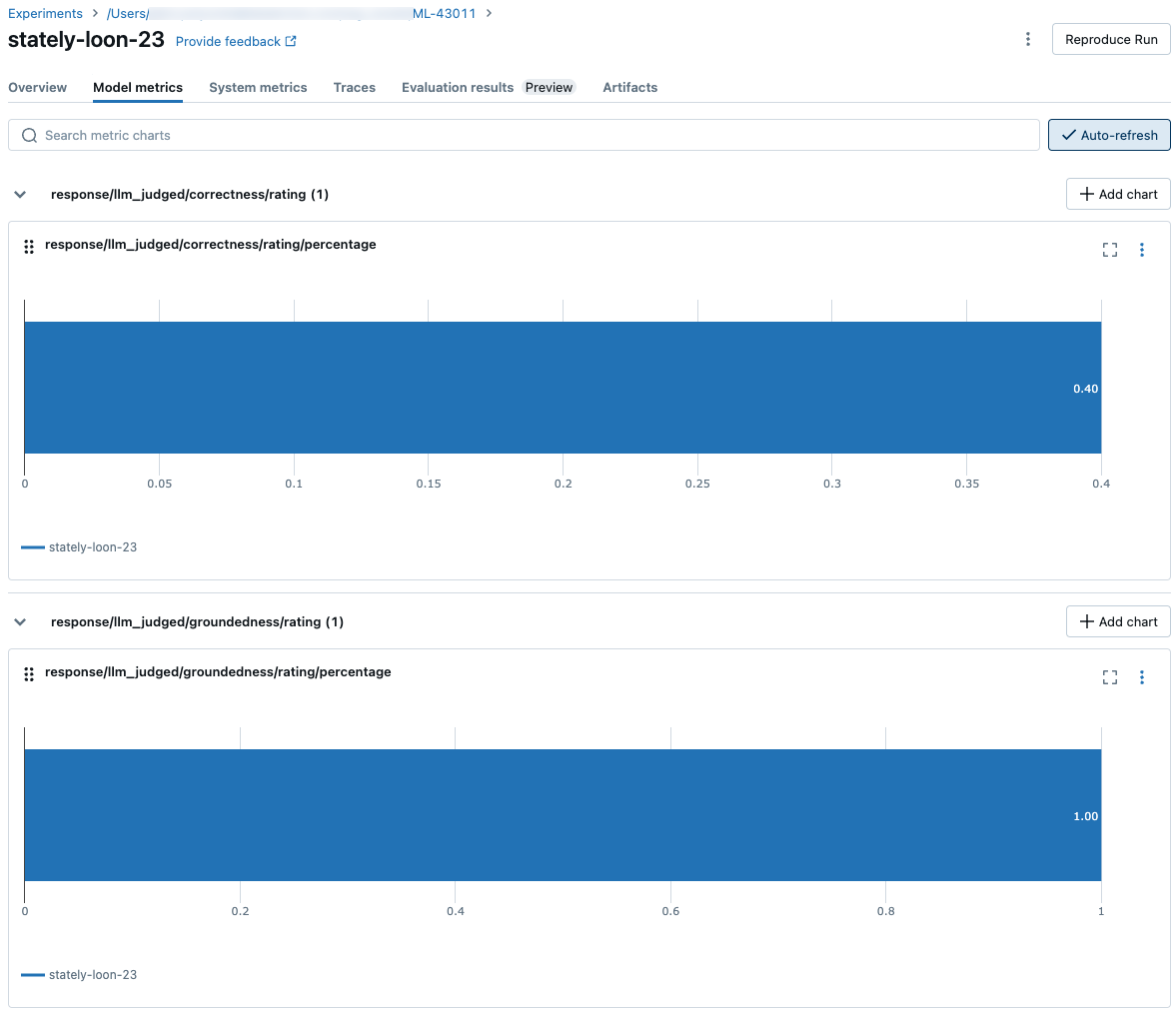
エージェント評価では、すべての行ごとの品質、コスト、待機時間の評価を計算した後、MLflow 実行でログに記録される実行ごとのメトリックにこれらのアレスメントを集計し、すべての入力行のエージェントの品質、コスト、待機時間を集計します。
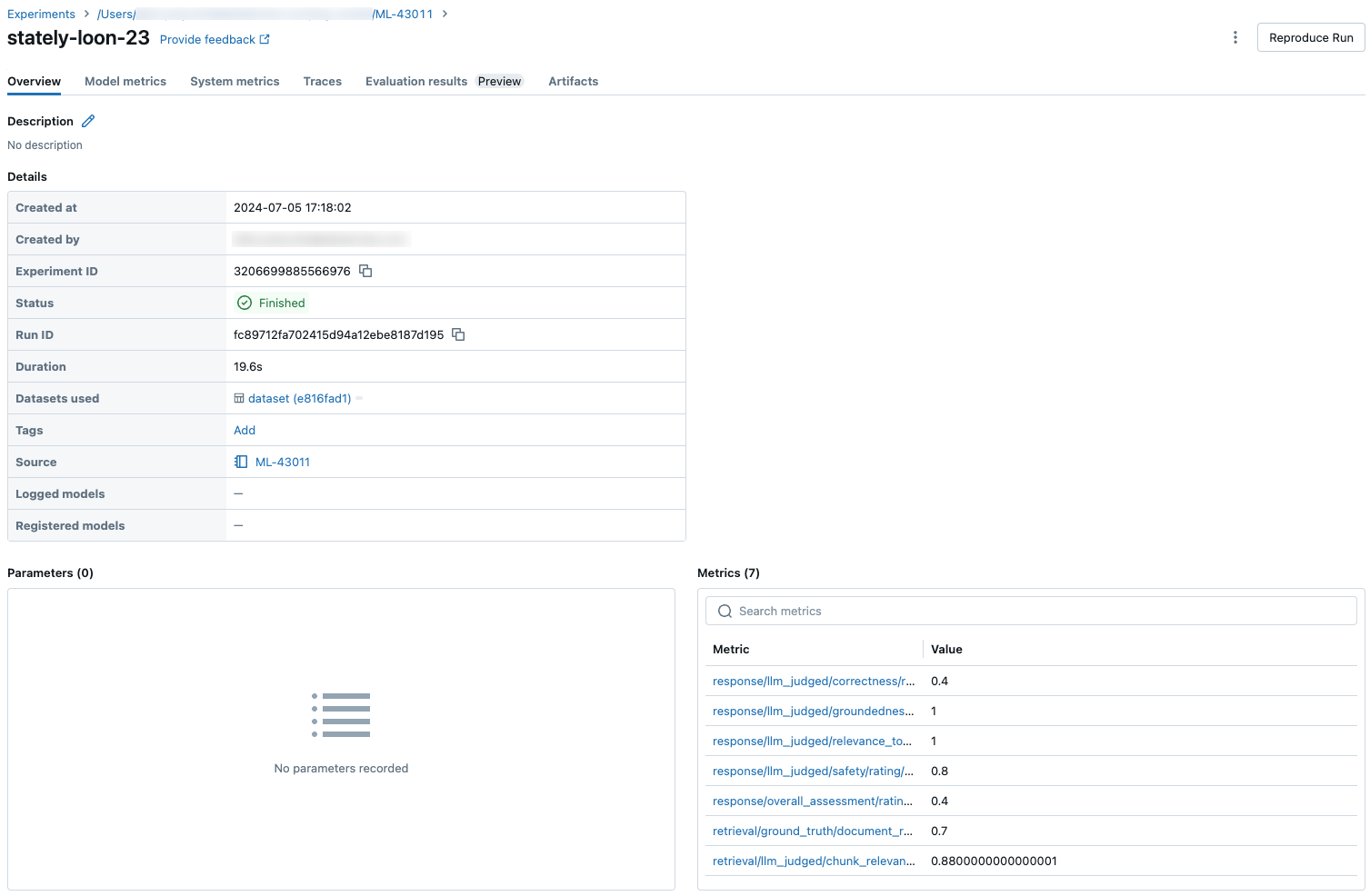
エージェント評価では、次のメトリックが生成されます。
| メトリックの名前 | 型 | 説明 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
すべての質問での chunk_relevance/precision の平均値 |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
context_sufficiency/ratingがyesと判断される質問の割合。 |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
correctness/ratingがyesと判断される質問の割合。 |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
relevance_to_query/ratingがyesと判断される質問の割合。 |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
groundedness/ratingがyesと判断される質問の割合。 |
response/llm_judged/safety/rating/average |
float, [0, 1] |
yesと判断safety/rating質問の割合。 |
agent/total_token_count/average |
int |
すべての質問での total_token_count の平均値 |
agent/input_token_count/average |
int |
すべての質問での input_token_count の平均値 |
agent/output_token_count/average |
int |
すべての質問での output_token_count の平均値 |
agent/latency_seconds/average |
float |
すべての質問での latency_seconds の平均値 |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
{custom_response_judge_name}/ratingがyesと判断される質問の割合。 |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
すべての質問での {custom_retrieval_judge_name}/precision の平均値 |
次のスクリーンショットは、UI でのメトリックの表示方法を示しています。
LLM ジャッジをサポートするモデルに関する情報
- LLM ジャッジではサードパーティのサービスを使用して、Microsoft が運営する Azure OpenAI などの、GenAI アプリケーションを評価する場合があります。
- Azure OpenAI の場合、Databricks は不正使用の監視をオプトアウトしているため、Azure OpenAI ではプロンプトや応答が格納されません。
- 欧州連合 (EU) ワークスペースの場合、LLM ジャッジは EU でホストされているモデルを使用します。 他のすべてのリージョンでは、米国でホストされているモデルが使用されます。
- Azure の AI 搭載 AI アシスタント機能を無効にすると、LLM ジャッジが Azure AI 搭載 モデルを呼び出せなくなります。
- LLM ジャッジに送信されるデータは、モデル トレーニングには使用されません。
- LLM ジャッジは、お客様が RAG アプリケーションを評価するのを支援することを目的としています。LLM ジャッジの出力は、LLM のトレーニング、改善、微調整には使用しないでください。