エンドポイントを提供するモデルで AI ゲートウェイを設定します
この記事では、モデルサービングエンドポイント上でMosaic AI Gateway を構成する方法について説明します。
要件
- 外部モデルがサポートされるリージョンまたはプロビジョニング スループットがサポートされるリージョンの Databricks ワークスペース。
- エンドポイントを提供するモデル。
- 外部モデルのエンドポイントを作成するには、「エンドポイントを提供する外部モデルを作成する」の手順 1 と 2 を実行します。
- プロビジョニング済みスループットのエンドポイントを作成するには、「プロビジョニング済みスループット基盤モデル API を参照してください。
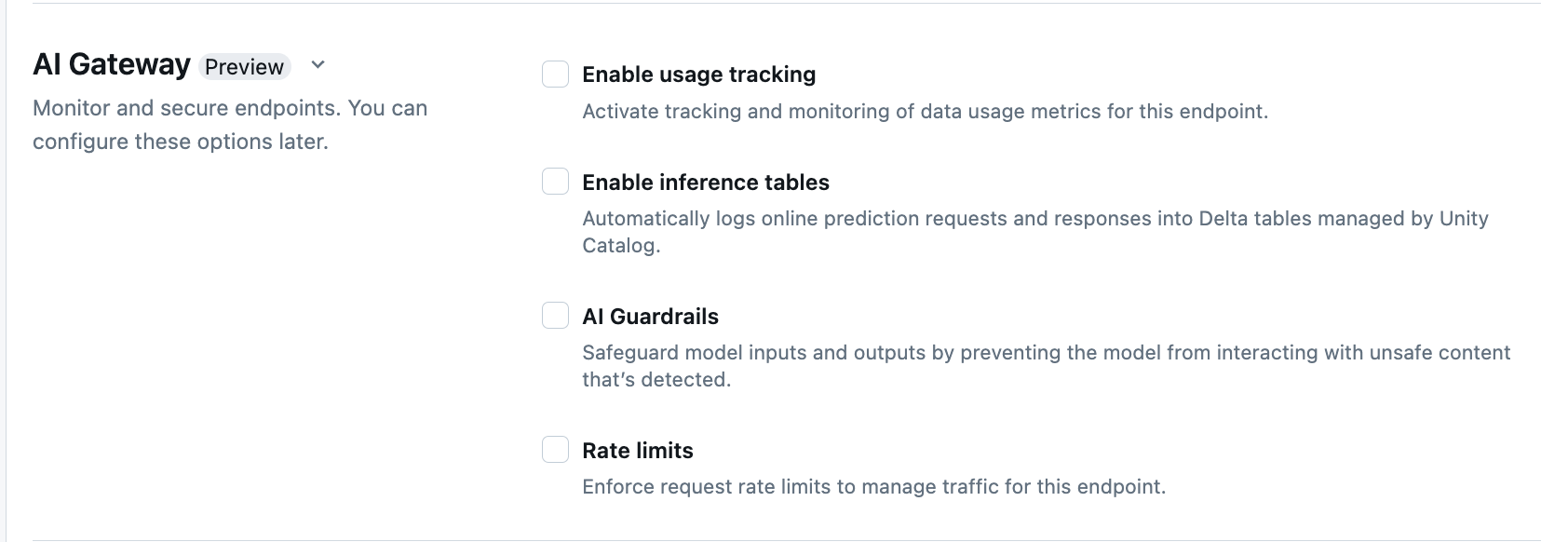
UI を使用して AI ゲートウェイを構成する
このセクションでは、サービス UI を使用してエンドポイントの作成時に AI ゲートウェイを構成する方法について説明します。 これをプログラムで行う場合は、 Notebook の例を参照してください。
エンドポイント作成ページの AI Gateway セクションでは、AI Gateway の機能を個別に構成できます。 外部モデル サービング エンドポイントとプロビジョニング スループット エンドポイントで利用できる機能については、サポートされている機能 をご参照ください。
| 機能 | 有効にする方法 | 詳細 |
|---|---|---|
| 使用状況の追跡 | 使用可能な使用状況の追跡 を選択し、データ使用状況メトリックの追跡と監視を有効にします。 | - Unity カタログを有効にする必要があります。 - アカウント管理者は、システム テーブルを使用する前に、サービング システム テーブル スキーマを有効にする必要があります。 system.serving.endpoint_usage でエンドポイントへの各要求のトークン数を取り込み、system.serving.served_entities で各基盤モデルのメタデータを格納します。- Usage トラッキング テーブル スキーマを参照する - エンドポイントを管理するユーザーが使用状況のトラッキングを有効にする必要がありますが、 served_entities テーブルまたは endpoint_usage テーブルを閲覧または照会する権限があるのはアカウント管理者だけです。 システム テーブルへのアクセスを許可するを参照ください。- トークン数がモデルによって返されない場合には、入力トークンと出力トークンの数は ( text_length+1)/4 と推定されます。 |
| ペイロードのログ | 可能な推論テーブル を選択して、エンドポイントからの要求と応答を Unity カタログによって管理される Delta テーブルに自動的に記録します。 | - 指定したカタログ スキーマで Unity カタログを有効にして、CREATE_TABLE アクセス権限を持っている必要があります。AI Gatewayによって有効化された推論テーブル - は、カスタムモデルを提供するエンドポイント用に作成された推論テーブル とは異なるスキーマを持ちます。 AI ゲートウェイ対応推論テーブル スキーマを参照してください。 - エンドポイントのクエリを実行してから 1 時間以内に、ペイロード ログ データがこれらのテーブルに追加されます。 - 1 MB (メガバイト)を超えるペイロードはログには記録されません。 - 応答ペイロードは、返されたすべてのチャンクの応答を集約します。 - ストリーミングはサポートされています。 ストリーミング シナリオでは、応答ペイロードは返されたチャンクの応答を集計します。 |
| AI ガードレール | UI の AI Guardrails の構成を参照してください。 | - ガードレールは、モデルの入力と出力で検出された安全でない有害なコンテンツとモデルのやり取りを防ぎます。 - 出力ガードレールは、埋め込みモデルやストリーミングではサポートされません。 |
| 転送率の制限 | 要求 制限を適用して ユーザーごとに、またエンドポイントごとにエンドポイントのトラフィックを管理できます | - レート制限は、1 分あたりのクエリ数 (QPM) で定義します。 - 既定値は、ユーザーごとおよびエンドポイントごとの両方で制限なしです。 |
| トラフィックのルーティング | エンドポイントでトラフィック ルーティングを構成するには、「複数の外部モデルをエンドポイントに接続する」を参照してください。 |
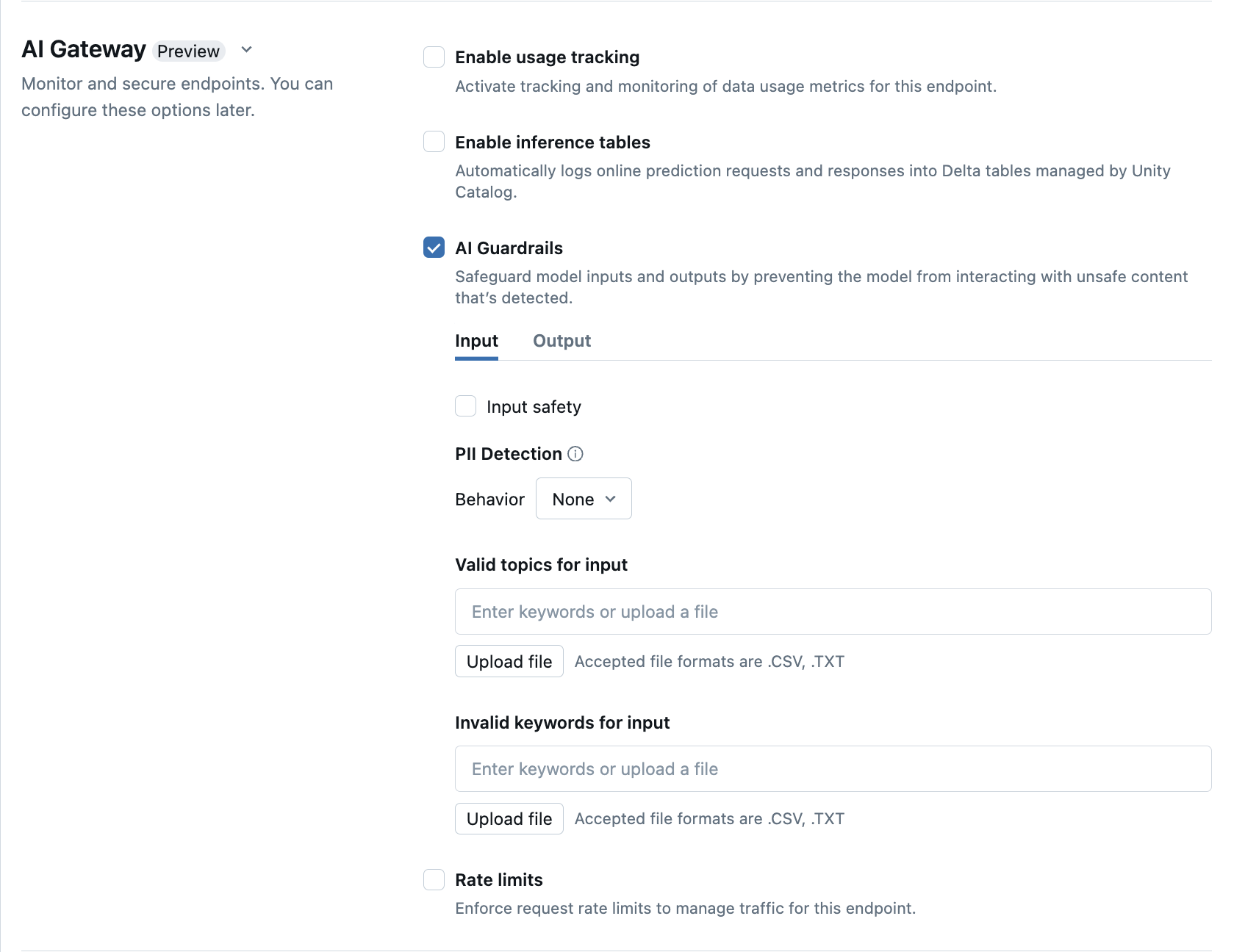
UI で AI Guardrails を構成する
次の表に、 サポートされているガードレールを構成する方法を示しています。
| ガードレール | 有効にする方法 | 詳細 |
|---|---|---|
| 安全性 | 安全性を選択すると、セーフガードが有効になり、モデルが安全で有害なコンテンツとやり取りできなくなります。 | |
| 個人を特定できる情報 (PII) の検出 | PII 検出を選択して、名前、住所、クレジット カード番号など、 PII データを検出します。 | |
| 有効なトピック | このフィールドにトピックを直接入力ができます。 複数のエントリがある場合には、各トピックの後で Enter キーを必ず押してください。 .csv または .txt ファイルをアップロードできます。 |
最大 50 個の有効なトピックの指定ができます。 各トピックは、100 文字を超えないようにしてください。 |
| 無効なキーワード | このフィールドにトピックを直接入力ができます。 複数のエントリがある場合には、各トピックの後で Enter キーを必ず押してください。 .csv または .txt ファイルをアップロードできます。 |
最大 50 個の無効なキーワードの指定ができます。 各キーワード (keyword)は 100 文字を超えないようにしてください。 |
使用状況追跡テーブルスキーマ
system.serving.served_entities 利用状況追跡システムテーブルのスキーマは以下の通りです:
| 列名 | 説明 | Type |
|---|---|---|
served_entity_id |
提供されるエンティティの一意のID。 | STRING |
account_id |
差分共有の顧客アカウント ID。 | STRING |
workspace_id |
サービス エンドポイントの顧客ワークスペース ID。 | STRING |
created_by |
作成者のID。 | STRING |
endpoint_name |
Web サービス エンドポイントの名前。 | STRING |
endpoint_id |
サービス エンドポイントの一意の ID。 | STRING |
served_entity_name |
提供されるエンティティの名前。 | STRING |
entity_type |
提供されるエンティティの型。 FEATURE_SPEC、EXTERNAL_MODEL、FOUNDATION_MODEL、または CUSTOM_MODEL にすることができます。 |
STRING |
entity_name |
エンティティの基礎となる名前。 ユーザー指定の名前の served_entity_name とは異なります。 たとえば、 entity_name は Unity カタログ モデルの名前です。 |
STRING |
entity_version |
提供されるエンティティのバージョン。 | STRING |
endpoint_config_version |
エンドポイント構成のバージョン。 | INT |
task |
タスクの種類。 llm/v1/chat、llm/v1/completions、または llm/v1/embeddings を指定できます。 |
STRING |
external_model_config |
外部モデルの構成。 たとえば、{Provider: OpenAI} のように指定します。 |
STRUCT |
foundation_model_config |
基盤モデルの構成。 たとえば、{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} にします。 |
STRUCT |
custom_model_config |
カスタム モデルの構成。 たとえば、{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } にします。 |
STRUCT |
feature_spec_config |
機能仕様の構成。 たとえば、{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } のように指定します。 |
STRUCT |
change_time |
提供されたエンティティの変更のタイムスタンプ。 | timestamp |
endpoint_delete_time |
エンティティ削除のタイムスタンプ。 エンドポイントは、提供されたエンティティのコンテナーです。 エンドポイント削除後、提供されたエンティティも削除されます。 | timestamp |
system.serving.endpoint_usage 利用状況追跡システムテーブルのスキーマは以下の通りです:
| 列名 | 説明 | Type |
|---|---|---|
account_id |
お客様のアカウント ID | STRING |
workspace_id |
サービス エンドポイントの顧客ワークスペース ID。 | STRING |
client_request_id |
モデル サービス要求本文で指定できる要求識別子をユーザーが指定しました。 | STRING |
databricks_request_id |
Azure Databricks によって生成された要求識別子は、要求を処理するすべてのモデルにアタッチされます。 | STRING |
requester |
サービス エンドポイントの呼び出し要求にアクセス許可が使用されるユーザーまたはサービス プリンシパルの ID。 | STRING |
status_code |
モデルから返された HTTP 状態コード。 | INTEGER |
request_time |
サーバーが要求を受信した時刻 | timestamp |
input_token_count |
入力トークンの数。 | LONG |
output_token_count |
出力トークンの数。 | LONG |
input_character_count |
入力文字列またはプロンプトの文字数。 | LONG |
output_character_count |
応答の出力文字列の文字数。 | LONG |
usage_context |
エンドポイントを呼び出すエンドユーザーまたは顧客アプリケーションの識別子を含む、ユーザーが提供したマップ。 「usage_context を使用して使用状況を詳細に定義する」を参照してください。 | MAP |
request_streaming |
要求がストリーム モードであるかどうか。 | BOOLEAN |
served_entity_id |
エンドポイントとサービスエンティティに関する情報を参照するために、 system.serving.served_entities ディメンション テーブルと結合するために使用される一意の ID。 |
STRING |
usage_context を使用して使用状況を詳細に定義する
使用状況の追跡を有効にして外部モデルにクエリを実行する場合は、usage_context パラメーターに型 Map[String, String] を指定できます。 利用コンテキスト マッピングは、usage_context 列の使用状況追跡テーブルに表示されます。 usage_contextマップ サイズは 10 KiB を超えることはできません。
アカウント管理者は、利用コンテキストに基づいてさまざまな行を集計して分析情報を取得し、この情報をペイロード ログ テーブルの情報と結合できます。 たとえば、エンド ユーザーのコスト属性を追跡するために、end_user_to_charge に usage_context を追加できます。
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
エンドポイントでの AI ゲートウェイ機能を更新
AIゲートウェイの機能は、以前に有効になっていたエンドポイントおよび有効になっていなかったエンドポイントを提供するモデルで更新できます。 AI Gateway 構成の更新プログラムの適用には約 20 ~ 40 秒かかりますが、レート制限の更新には最大で 60 秒かかることがあります。
サービス UI を使用して、エンドポイントを提供するモデルの AI ゲートウェイ機能を更新する方法を次に示します。
エンドポイント ページの Gateway セクションで、有効になっている機能を確認できます。 これらの機能を更新するには、AI ゲートウェイ 編集をクリックします。

ノートブックの例
次のノートブックは、Databricks Mosaic AI Gateway の機能をプログラムで有効にして使用し、プロバイダーからモデルを管理する方法が示されています。 REST API の詳細については、次を参照してください。