ジョブ システム テーブル リファレンス
Note
lakeflow スキーマは、以前は workflow と呼れていました。 両方のスキーマの内容は同じです。 lakeflow スキーマを表示するには、個別に有効にする必要があります。
この記事では、lakeflow システム テーブルを使用してアカウント内のジョブを監視する方法のリファレンスです。 これらのテーブルには、同じクラウド リージョン内にデプロイされたアカウント内のすべてのワークスペースのレコードが含まれます。 別のリージョンのレコードを表示するには、そのリージョンにデプロイされているワークスペースのテーブルを表示する必要があります。
要件
system.lakeflowスキーマは、アカウント管理者が有効にする必要があります。「システム テーブル スキーマを有効にする」を参照してください。- これらのシステム テーブルにアクセスするには、ユーザーは次のいずれかを行う必要があります。
- メタストア管理者とアカウント管理者の両方であるか、または
- システム スキーマに対する
USE権限とSELECT権限を持つ。 システム テーブルへのアクセス権の付与を参照してください。
利用可能な仕事のテーブル
ジョブ関連のすべてのシステム テーブルは、system.lakeflow スキーマに含まれます。 現在、このスキーマによって、次の 4 つのテーブルがホストされています。
| 表 | Description | ストリーミングをサポート | 無料の保持期間 | グローバルデータまたは地域データを含む |
|---|---|---|---|---|
| jobs (パブリック プレビュー) | アカウントで作成されたすべてのジョブを追跡します | はい | 365 日 | 地域 |
| 作業タスク (パブリック プレビュー) | アカウントで実行されるすべてのジョブ タスクを追跡します | はい | 365 日 | 地域 |
| job_run_timeline (パブリック プレビュー) | ジョブの実行と関連メタデータを追跡します | はい | 365 日 | 地域 |
| job_task_run_timeline (パブリック プレビュー) | ジョブ タスクの実行と関連メタデータを追跡します | はい | 365 日 | 地域 |
詳細なスキーマ リファレンス
次のセクションでは、ジョブ関連の各システム テーブルのスキーマ参照について説明します。
ジョブテーブルスキーマ
jobs テーブルは、緩やかに変化するディメンション テーブル (SCD2) です。 行が変更されると、新しい行が出力され、前の行が論理的に置き換えられます。
テーブルのパス: system.lakeflow.jobs
| 列名 | データ型 | Description | 注記 |
|---|---|---|---|
account_id |
string | このジョブが属するアカウントの ID | |
workspace_id |
string | このジョブが属するワークスペースの ID | |
job_id |
string | ジョブの ID | 1つのワークスペース内でのみ一意である |
name |
string | ジョブのユーザー指定の名前 | |
description |
string | ジョブのユーザー指定の説明 | カスタマー マネージド キーが構成されている場合、このフィールドは空になります。 2024 年 8 月下旬より前に出力された行には設定されません |
creator_id |
string | ジョブを作成したプリンシパルの ID | |
tags |
string | このジョブに関連付けられているユーザー指定のカスタム タグ | |
change_time |
timestamp | ジョブが最後に変更された日時 | +00:00 (UTC) として記録されたタイムゾーン |
delete_time |
timestamp | ジョブがユーザーによって削除された時刻 | +00:00 (UTC) として記録されたタイムゾーン |
run_as |
string | ジョブの実行に使用されるアクセス許可を持つユーザーまたはサービス プリンシパルの ID |
クエリの例
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
ジョブのタスク テーブル スキーマ
ジョブ タスク テーブルは、緩やかに変化するディメンション テーブル (SCD2) です。 行が変更されると、新しい行が出力され、前の行が論理的に置き換えられます。
テーブル パス: system.lakeflow.job_tasks
| 列名 | データ型 | Description | 注記 |
|---|---|---|---|
account_id |
string | このジョブが属するアカウントの ID | |
workspace_id |
string | このジョブが属するワークスペースの ID | |
job_id |
string | ジョブの ID | 1 つのワークスペース内でのみ唯一 |
task_key |
string | ジョブ内のタスクの参照キー | 1つのジョブ内でのみユニーク |
depends_on_keys |
配列 | このタスクのすべてのアップストリーム依存関係のタスク キー | |
change_time |
timestamp | タスクが最後に変更された時刻 | +00:00 (UTC) として記録されたタイムゾーン |
delete_time |
timestamp | ユーザーがタスクを削除した時刻 | +00:00 (UTC) として記録されたタイムゾーン |
クエリの例
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
ジョブ実行のタイムライン テーブル スキーマ
ジョブ実行タイムライン テーブルは変更不可であり、作成時に完了します。
テーブル パス: system.lakeflow.job_run_timeline
| 列名 | データ型 | Description | 注記 |
|---|---|---|---|
account_id |
string | このジョブが属するアカウントの ID | |
workspace_id |
string | このジョブが属するワークスペースの ID | |
job_id |
string | ジョブの ID | このキーは、1 つのワークスペース内でのみ一意です |
run_id |
string | ジョブ実行の ID | |
period_start_time |
timestamp | 実行の開始時刻または期間 | タイムゾーン情報は、値の末尾に UTC を表す +00:00 で記録されます。 |
period_end_time |
timestamp | 実行または期間の終了日時 | タイムゾーン情報は、値の末尾に UTC を表す +00:00 で記録されます。 |
trigger_type |
string | 実行を起動できるトリガーの種類 | 使用可能な値については、「トリガーの種類の値」を参照してください。 |
run_type |
string | ジョブ実行の種類 | 参照可能な値については、「実行タイプの値」をご覧ください。 |
run_name |
string | このジョブ実行に関連付けられているユーザー指定の実行名 | |
compute_ids |
配列 | 親ジョブ実行のジョブ コンピューティング ID を含む配列 | WORKFLOW_RUN 実行の種類で使用されるジョブ クラスターを識別するために使用します。 その他のコンピューティング情報については、 job_task_run_timeline の表を参照してください。2024 年 8 月下旬より前に出力された行には設定されません |
result_state |
string | ジョブ実行の結果 | 使用可能な値については、結果の状態値 を参照してください。 |
termination_code |
string | ジョブ実行の終了コード | 使用可能な値については、「終了コード値」を参照してください。 2024 年 8 月下旬より前に出力された行には設定されません |
job_parameters |
map | ジョブ実行で使用されるジョブ レベルのパラメーター | このフィールドには、非推奨の notebook_params 設定は含まれません。 2024 年 8 月下旬より前に出力された行には設定されません |
クエリの例
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
ジョブ タスク実行のタイムライン テーブル スキーマ
ジョブ タスク実行タイムライン テーブルは変更不可であり、作成時に完了します。
テーブル パス: system.lakeflow.job_task_run_timeline
| 列名 | データ型 | Description | 注記 |
|---|---|---|---|
account_id |
string | このジョブが属するアカウントの ID | |
workspace_id |
string | このジョブが属するワークスペースの ID | |
job_id |
string | ジョブの ID | ひとつのワークスペース内でのみ一意です |
run_id |
string | タスク実行の ID | |
job_run_id |
string | ジョブ実行の ID | 2024 年 8 月下旬より前に出力された行には設定されません |
parent_run_id |
string | 親実行の ID | 2024 年 8 月下旬より前に出力された行には設定されません |
period_start_time |
timestamp | タスクまたは期間の開始時刻 | タイムゾーン情報は、値の末尾に UTC を表す +00:00 で記録されます。 |
period_end_time |
timestamp | タスクまたは期間の終了時刻 | タイムゾーン情報は、値の末尾に UTC を表す +00:00 で記録されます。 |
task_key |
string | ジョブ内のタスクの参照キー | このキーは、1 つのジョブ内でのみ一意です |
compute_ids |
配列 | compute_ids配列には、ジョブ タスクによって使用されるジョブ クラスター、対話型クラスター、および SQL ウェアハウスの ID が含まれています | |
result_state |
string | ジョブタスクの実行結果 | 使用可能な値については、「結果の状態値」を参照してください。 |
termination_code |
string | タスク実行の終了コード | 使用可能な値については、「終了コード値」を参照してください。 2024年8月下旬より前に出力された行は未入力です |
一般的な結合パターン
次のセクションでは、ジョブ システム テーブルでよく使用される結合パターンを強調表示するサンプル クエリを示します。
ジョブテーブルとジョブ実行タイムラインテーブルを結合する
ジョブ名を使用してジョブ実行をエンリッチする
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
ジョブ実行タイムラインと使用状況テーブルを結合する
ジョブ実行メタデータを使用して各ログをエンリッチする
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
ジョブ実行あたりのコストを計算する
このクエリは、billing.usage システム テーブルと結合して、ジョブの実行あたりのコストを計算します。
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
SUBMIT_RUN ジョブの使用状況ログを取得する
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
ジョブ タスクの実行タイムラインとクラスター テーブルを結合する
クラスター メタデータを使用してジョブ タスクの実行を強化する
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
汎用コンピューティングで実行されているジョブを検索する
このクエリは、compute.clusters システム テーブルと結合し、Jobs Compute ではなく All-Purpose Compute で実行されている最近のジョブを返します。
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
ジョブ監視ダッシュボード
次のダッシュボードでは、システム テーブルを使用して、ジョブと運用の正常性の監視を開始できます。 これには、ジョブ パフォーマンスの追跡、障害の監視、リソース使用率などの一般的なユース ケースが含まれます。
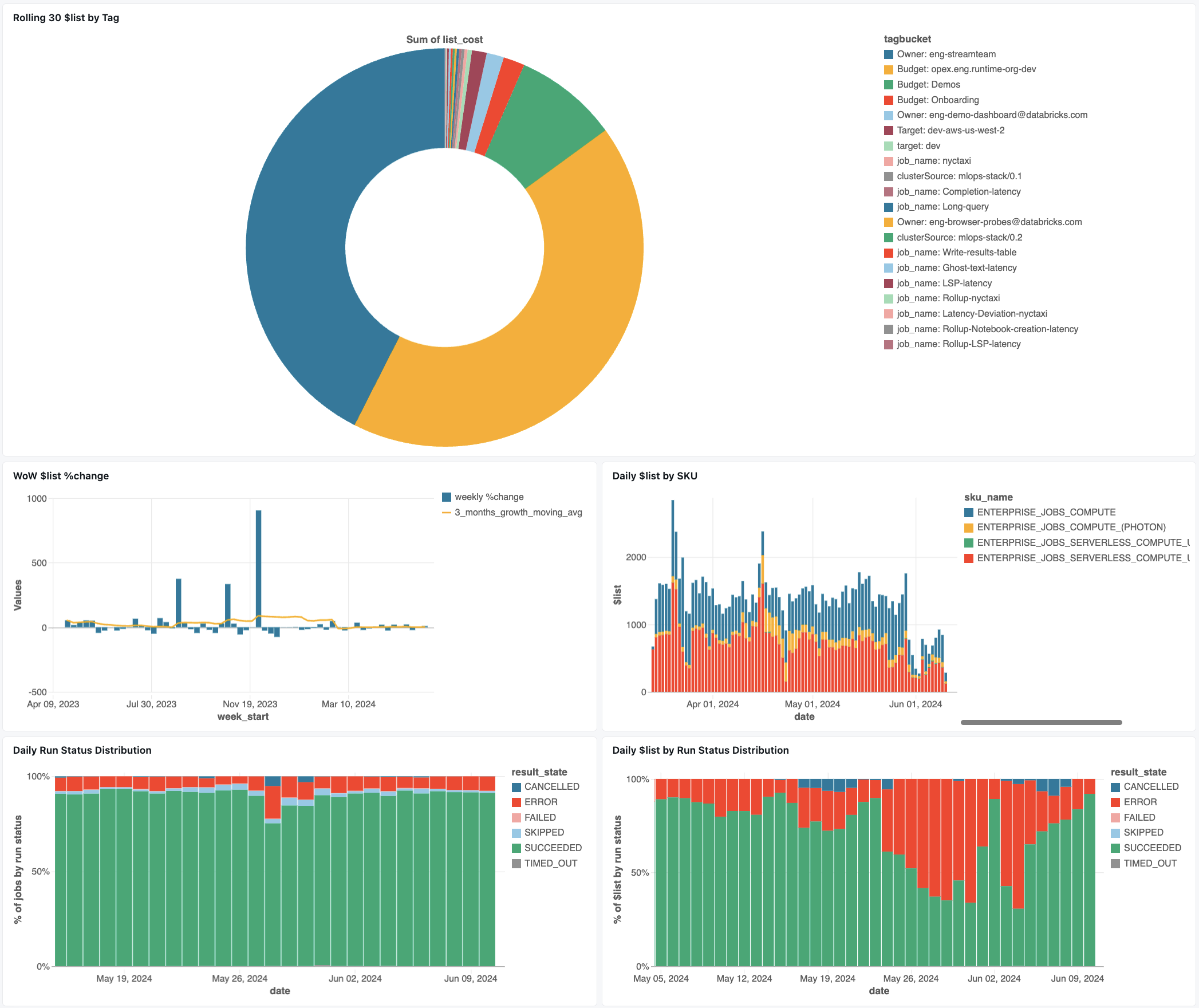
ダッシュボードのダウンロードの詳細については、「システム テーブル を使用したジョブ コスト & パフォーマンスの監視」を参照してください。
トラブルシューティング
ジョブが lakeflow.jobs テーブルにログに記録されていない
ジョブがシステム テーブルに表示されない場合:
- 過去 365 日間にジョブが変更されませんでした
- スキーマに存在するジョブのフィールドを変更して、新しいレコードを出力します。
- ジョブが別のリージョンで作成されました
- 最近のジョブ作成(テーブルの遅延)
job_run_timeline テーブルに表示されるジョブが見つかりません
すべてのジョブ実行がどこでも表示されるわけではありません。 JOB_RUN エントリはすべてのジョブ関連テーブルに表示されますが、WORKFLOW_RUN (ノートブック ワークフローの実行) は job_run_timeline にのみ記録され、SUBMIT_RUN (1 回限りの実行) は両方のタイムライン テーブルにのみ記録されます。 これらの実行は、jobs や job_tasksなどの他のジョブ システム テーブルには入力されません。
各種類の実行が表示され、アクセス可能な場所の詳細は、下記の表「実行の種類」をご覧ください。
ジョブ実行が billing.usage テーブルに表示されない
system.billing.usageでは、usage_metadata.job_id は、ジョブ コンピューティングまたはサーバーレス コンピューティングで実行されるジョブに対してのみ設定されます。
さらに、WORKFLOW_RUN ジョブには、system.billing.usageに独自の usage_metadata.job_id や usage_metadata.job_run_id 属性はありません。
代わりに、コンピューティング使用量は、それらをトリガーした親ノートブックに起因します。
つまり、ノートブックがワークフロー実行を起動すると、すべてのコンピューティング コストが、個別のワークフロー ジョブとしてではなく、親ノートブックの使用状況の下に表示されます。
詳細については、「使用状況メタデータ リファレンス」を参照してください。
汎用コンピューティングで実行されているジョブのコストを計算する
100% の精度では、専用コンピューティングで実行されるジョブの正確なコスト計算はできません。 対話型 (万能) コンピューティングでジョブを実行する場合、ノートブック、SQL クエリ、その他のジョブなどの複数のワークロードは、多くの場合、同じコンピューティング リソースで同時に実行されます。 クラスター リソースは共有されるため、コンピューティング コストと個々のジョブ実行の間に直接 1 対 1 のマッピングはありません。
正確なジョブ コストの追跡のために、Databricks では、専用のジョブ コンピューティングまたはサーバーレス コンピューティングでジョブを実行することをお勧めします。ここで、usage_metadata.job_id と usage_metadata.job_run_id により正確なコスト属性が可能になります。
万能コンピューティングを使用する必要がある場合は、次のことができます。
usage_metadata.cluster_idに基づいて、クラスターの全体的な使用状況とsystem.billing.usageのコストを監視します。- ジョブ ランタイム メトリックを個別に追跡します。
- コスト見積もりは、共有リソースが原因で概算されることを検討してください。
コスト属性の詳細については、「使用状況メタデータ リファレンス」を参照してください。
参照値
次のセクションでは、ジョブ関連テーブルの選択列の参照を示します。
トリガーの種類の値
trigger_type 列に指定できる値は次のとおりです。
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Run の種類の値
run_type 列に指定できる値は次のとおりです。
| タイプ | Description | UI の場所 | API エンドポイント | システム テーブル |
|---|---|---|---|---|
JOB_RUN |
標準ジョブの実行 | ジョブとジョブ実行 UI | /jobs および /jobs/runs エンドポイント | ジョブ, job_tasks, job_run_timeline, job_task_run_timeline |
SUBMIT_RUN |
POST /jobs/runs/submit を使用した 1 回限りの実行 | ジョブ実行 UI のみ | /jobs/runs のエンドポイントのみ | job_run_timeline, job_task_run_timeline |
WORKFLOW_RUN |
ノートブック のワークフロー から実行を開始 | 非表示 | アクセス不可 | ジョブ実行タイムライン |
結果の状態値
result_state 列に指定できる値は次のとおりです。
| 州 | Description |
|---|---|
SUCCEEDED |
実行が正常に完了しました |
FAILED |
実行がエラーで完了しました |
SKIPPED |
条件が満たされていないため、実行されませんでした。 |
CANCELLED |
ユーザーの要求で実行が取り消されました |
TIMED_OUT |
タイムアウトに達した後、実行が停止されました |
ERROR |
実行がエラーで完了しました |
BLOCKED |
アップストリームの依存関係で実行がブロックされました |
終了コード値
termination_code 列に指定できる値は次のとおりです。
| 終了コード | Description |
|---|---|
SUCCESS |
実行が正常に完了しました |
CANCELLED |
実行は Databricks プラットフォームによって実行中に取り消されました。たとえば、最大実行時間を超えた場合 |
SKIPPED |
実行が実行されませんでした。たとえば、アップストリーム タスクの実行に失敗した場合、依存関係の種類の条件が満たされなかった場合、または実行する重要なタスクがなかった場合などです。 |
DRIVER_ERROR |
Spark ドライバーとの通信中に実行でエラーが発生しました |
CLUSTER_ERROR |
クラスター エラーが原因で実行に失敗しました |
REPOSITORY_CHECKOUT_FAILED |
サード パーティのサービスとの通信中にエラーが発生したため、チェックアウトを完了できませんでした |
INVALID_CLUSTER_REQUEST |
クラスターを起動するための無効な要求を発行したため、実行に失敗しました |
WORKSPACE_RUN_LIMIT_EXCEEDED |
ワークスペースは、同時実行中のジョブの最大数に達しました。 より大きな期間にわたって実行をスケジュールすることを検討する |
FEATURE_DISABLED |
ワークスペースで使用できない機能にアクセスしようとしたため、実行に失敗しました |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
クラスターの作成、開始、アップサイズの要求の数が、割り当てられたレート制限を超えています。 実行をより長い期間にわたって分散することを検討する。 |
STORAGE_ACCESS_ERROR |
顧客の BLOB ストレージにアクセスするときにエラーが発生したため、実行に失敗しました |
RUN_EXECUTION_ERROR |
タスクエラーで実行が完了しました |
UNAUTHORIZED_ERROR |
リソースへのアクセス中にアクセス許可の問題が発生したため、実行に失敗しました |
LIBRARY_INSTALLATION_ERROR |
ユーザーが要求したライブラリのインストール中に実行に失敗しました。 原因には、以下が含まれますが、これらに限定されません。指定されたライブラリが無効である、ライブラリをインストールするための十分なアクセス許可がない、などです。 |
MAX_CONCURRENT_RUNS_EXCEEDED |
スケジュールされた実行が、ジョブに対して設定された同時実行の最大数の制限を超えています |
MAX_SPARK_CONTEXTS_EXCEEDED |
実行は、作成するように構成されているコンテキストの最大数に既に達しているクラスターでスケジュールされます |
RESOURCE_NOT_FOUND |
実行に必要なリソースが存在しない |
INVALID_RUN_CONFIGURATION |
無効な構成が原因で実行に失敗しました |
CLOUD_FAILURE |
クラウド プロバイダーの問題が原因で実行に失敗しました |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
ジョブ レベルのキュー サイズ制限に達したため、実行がスキップされました |