Databricks ノートブックを別のノートブックから実行する
重要
ノートブックのオーケストレーションでは、Databricks ジョブを使用します。 コードのモジュール化シナリオでは、ワークスペース ファイルを使用します。 この記事で説明する手法は、Databricks ジョブを使用してユース ケースを実装できない場合 (動的なパラメータ セットでノートブックをループする場合など)、またはワークスペース ファイルにアクセスできない場合にのみ使用してください。 詳細については、「ワークフローのスケジュールと調整」と「共有コード」を参照してください。
%run と dbutils.notebook.run() の比較
%run コマンドを使用すると、ノートブック内に別のノートブックを含めることができます。 %run を使用すると、たとえば、補助的な関数を別のノートブックに入れて、コードをモジュール化できます。 また、分析にステップを実装するノートブックの連結にも使用できます。 %run を使用すると、呼び出されたノートブックがすぐに実行され、その中で定義されている関数と変数を呼び出し元のノートブックで使用できるようになります。
dbutils.notebook API は、%run を補完するものです。これは、ノートブックに対してパラメーターを渡して値を返すことができるためです。 これを使用すると、依存関係を含む複雑なワークフローとパイプラインを作成できます。 たとえば、ディレクトリ内のファイルの一覧を取得し、それらの名前を別のノートブックに渡すことができますが、これは、%run ではできません。 また、戻り値に基づいて if-then-else ワークフローを作成したり、相対パスを使用して他のノートブックを呼び出したりすることもできます。
%run とは異なり、dbutils.notebook.run() メソッドではノートブックを実行する新しいジョブを開始します。
これらのメソッドは、すべての dbutils API と同様に、Python と Scala でのみ使用できます。 ただし、dbutils.notebook.run() を使用すると、R ノートブックを呼び出すことができます。
%run を使用してノートブックをインポートする
次の例では、1 つめのノートブックで関数 reverse が定義されています。これは、%run マジックを使用して shared-code-notebook を実行した後に、2 つめのノートブックで使用できます。
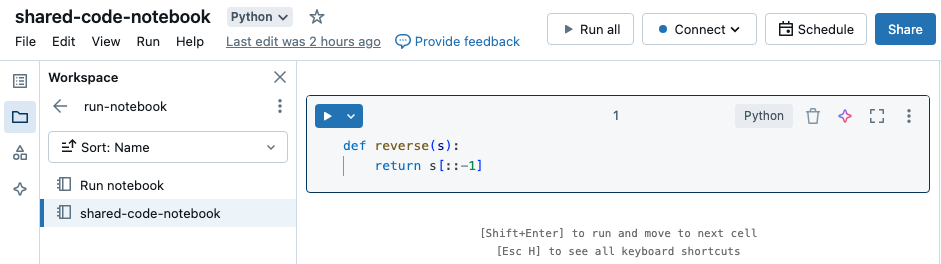
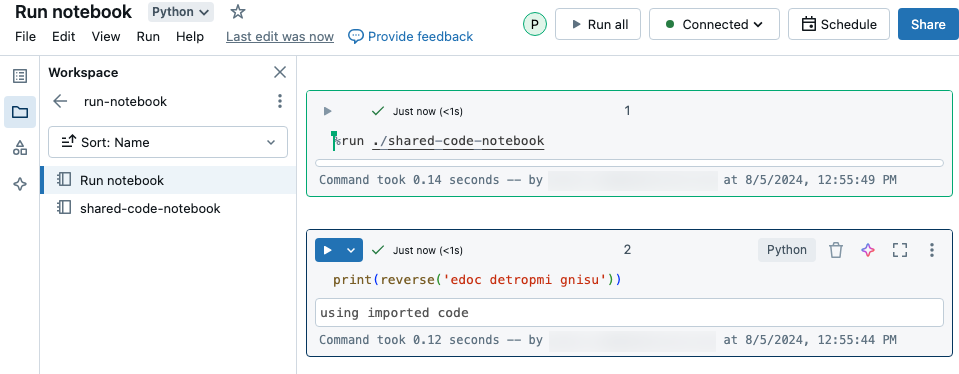
これらのノートブックはどちらもワークスペース内の同じディレクトリ内にあるため、./shared-code-notebook でプレフィックス ./ を使用して、現在実行中のノートブックに対して相対的にパスを解決する必要があることを示します。 %run ./dir/notebook のようにノートブックをディレクトリに整理することも、%run /Users/username@organization.com/directory/notebook のように絶対パスを使用することもできます。
注意
%runはセル内に単独で存在している必要があります。このコマンドでノートブック全体がインラインで実行されるからです。%runを使用して Python ファイルを実行し、そのファイル内で定義されているエンティティをノートブックにimportすることはできません。 Python ファイルからインポートするには、ファイルを使用してコードをモジュール化する方法に関する記事を参照してください。 または、そのファイルをパッケージして Python ライブラリを作成し、その Python ライブラリから Azure Databricks ライブラリを作成します。ノートブックの実行に使用するクラスターにこのライブラリをインストールする必要があります。%runを使用して、ウィジェットを含むノートブックを実行する場合、既定では、指定したノートブックがウィジェットの既定値で実行されます。 値をウィジェットに渡すこともできます。「%run で Databricks ウィジェットを使用する」をご覧ください。
dbutils.notebook API
dbutils.notebook API で使用できるメソッドは run と exit です。 パラメーターと戻り値はどちらも文字列でなければなりません。
run(path: String, timeout_seconds: int, arguments: Map): String
ノートブックを実行し、その終了値を返します。 このメソッドでは、すぐに実行される一時的なジョブを開始します。
timeout_seconds パラメーターで実行のタイムアウトを制御します (0 はタイムアウトがないことを意味します)。run の呼び出しは、指定された時間内に終了しないと例外がスローされます。 Azure Databricks がダウンしたまま 10 分を超えると、timeout_seconds に関係なく、ノートブックの実行は失敗します。
arguments パラメーターでは、ターゲット ノートブックのウィジェットの値を設定します。 具体的には、実行しているノートブックに A という名前のウィジェットがあり、引数パラメーターの一部としてキーと値のペア ("A": "B") を run() の呼び出しに渡す場合、ウィジェット A の値を取得すると "B" が返されます。 ウィジェットの作成と操作の手順については、「Databricks ウィジェット」の記事を参照してください。
注意
argumentsパラメーターには、ラテン文字 (ASCII 文字セット) のみを使用できます。 非 ASCII 文字を使用すると、エラーが返されます。dbutils.notebookAPI を使用して作成されたジョブは、30 日以内に完了する必要があります。
run 使用法
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
run 例
foo という名前のウィジェットを含み、そのウィジェットの値を出力する、workflows という名前のノートブックがあるとします。
dbutils.widgets.text("foo", "fooDefault", "fooEmptyLabel")
print(dbutils.widgets.get("foo"))
dbutils.notebook.run("workflows", 60, {"foo": "bar"}) を実行すると、次の結果が生成されます。
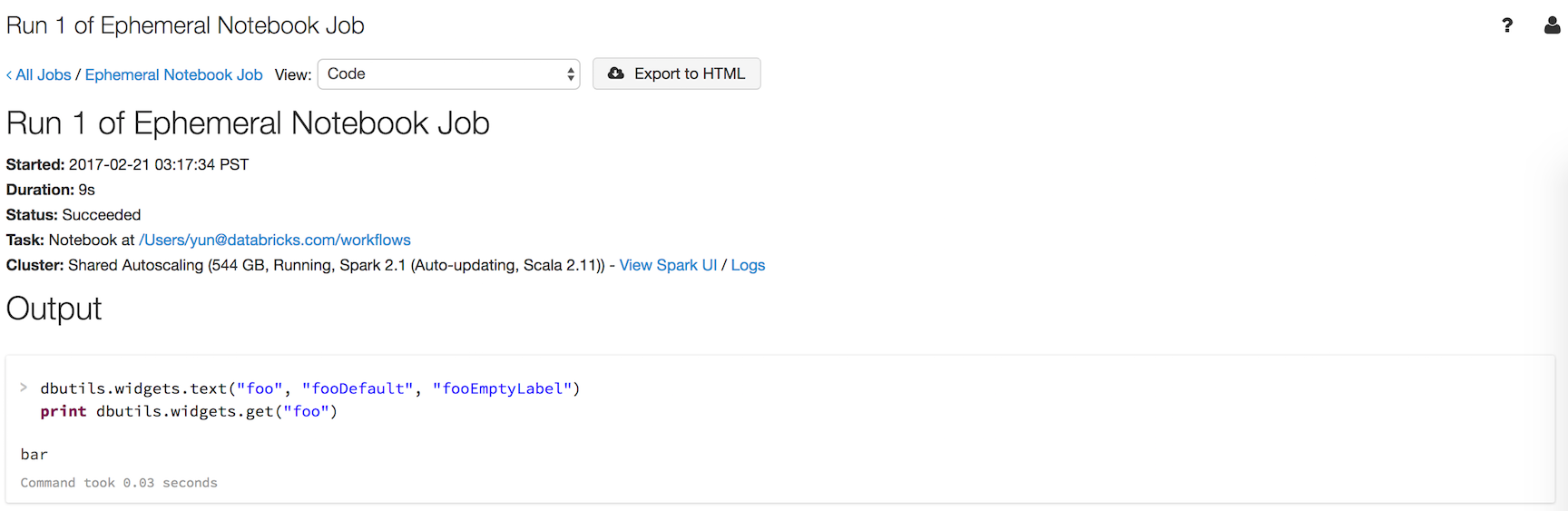
このウィジェットには、既定ではなく、dbutils.notebook.run() を使用して渡した値 "bar" が含まれていました。
exit(value: String): void 値を指定してノートブックを終了します。 run メソッドを使用してノートブックを呼び出す場合、これが返される値になります。
dbutils.notebook.exit("returnValue")
ジョブで dbutils.notebook.exit を呼び出すと、ノートブックは正常に完了します。 ジョブを失敗させるには、例外をスローします。
例
次の例では、DataImportNotebook に引数を渡し、DataImportNotebook からの結果に基づいて、異なるノートブック (DataCleaningNotebook または ErrorHandlingNotebook) を実行します。
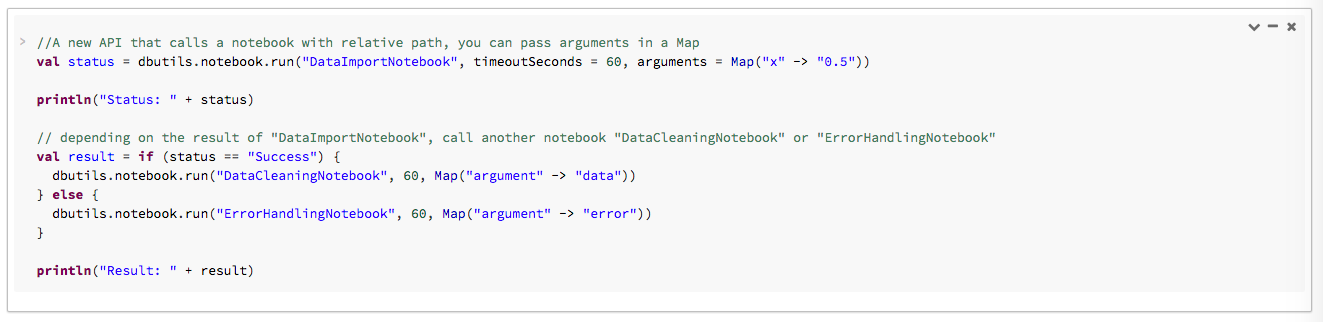
このコードを実行すると、実行中のノートブックへのリンクを含むテーブルが表示されます。

実行の詳細を表示するには、テーブル内の [Start time] リンクをクリックします。 実行が完了した場合は、[End time] リンクをクリックして実行の詳細を表示することもできます。
構造化データを渡す
このセクションでは、ノートブック間で構造化データを渡す方法について説明します。
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
エラーを処理する
このセクションでは、エラーを処理する方法について説明します。
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
複数のノートブックを同時に実行する
複数のノートブックを同時に実行するには、標準の Scala と Python のコンストラクトを使用します。たとえば、スレッド (Scala、Python) やフューチャ (Scala、Python) です。 ノートブック例には、これらのコンストラクトの使用方法が記載されています。
- 次の 4 つのノートブックをダウンロードします。 ノートブックは Scala で記述されています。
- ワークスペース内の 1 つのフォルダーにノートブックをインポートします。
- 同時に実行するノートブックを実行します。