Azure Data Factory で Hive アクティビティを使用して Azure Virtual Network のデータを変換する
適用対象:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure PowerShell を使用して Data Factory パイプラインを作成します。このパイプラインで、Azure Virtual Network (VNet) にある HDInsight クラスター上の Hive アクティビティを使用してデータを変換します。 このチュートリアルでは、以下の手順を実行します。
- データ ファクトリを作成します。
- セルフホステッド統合ランタイムを作成して設定します
- リンクされたサービスを作成してデプロイします。
- Hive アクティビティが含まれたパイプラインを作成してデプロイします。
- パイプラインの実行を開始します。
- パイプラインの実行を監視します
- 出力を検証します。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
Note
Azure を操作するには、Azure Az PowerShell モジュールを使用することをお勧めします。 作業を始めるには、「Azure PowerShell をインストールする」を参照してください。 Az PowerShell モジュールに移行する方法については、「AzureRM から Az への Azure PowerShell の移行」を参照してください。
Azure Storage アカウント。 Hive スクリプトを作成し、Azure ストレージにアップロードします。 Hive スクリプトからの出力は、このストレージ アカウントに格納されます。 このサンプルでは、この Azure ストレージ アカウントがプライマリ ストレージとして HDInsight クラスターによって使用されます。
Azure Virtual Network。 Azure 仮想ネットワークを持っていない場合は、こちらの手順に従って作成してください。 このサンプルでは、HDInsight は Azure 仮想ネットワーク内にあります。 Azure Virtual Network の構成例を次に示します。
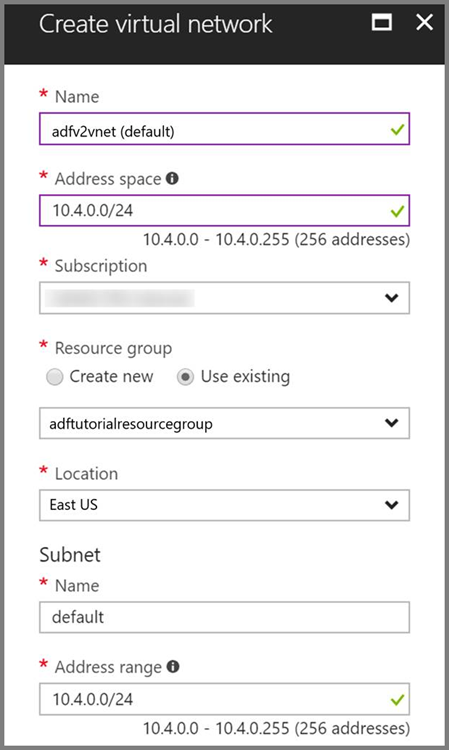
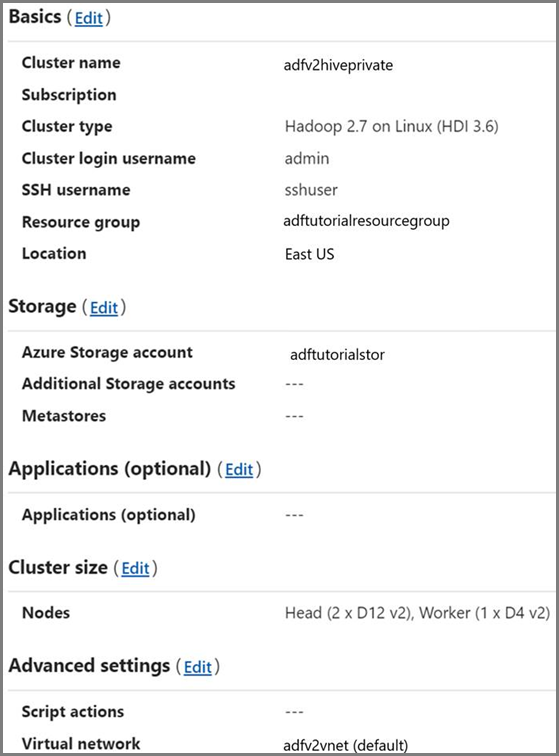
HDInsight クラスター。 HDInsight クラスターを作成し、前の手順で作成した仮想ネットワークに参加させます。手順については、「Azure Virtual Network を使用した Azure HDInsight の拡張」を参照してください。 仮想ネットワークでの HDInsight の構成例を次に示します。
Azure PowerShell。 Azure PowerShell のインストールと構成の方法に関するページに記載されている手順に従います。
Hive スクリプトを BLOB ストレージ アカウントにアップロードする
次の内容で、hivescript.hql という名前の Hive SQL ファイルを作成します。
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableAzure BLOB ストレージで、adftutorial という名前のコンテナーを作成します (存在しない場合)。
hivescripts という名前のフォルダーを作成します。
hivescript.hql ファイルを hivescripts サブフォルダーにアップロードします。
Data Factory の作成
リソース グループ名を設定します。 このチュートリアルの一環として、リソース グループを作成します。 ただし、既存のリソース グループを使用してもかまいません。
$resourceGroupName = "ADFTutorialResourceGroup"データ ファクトリ名を指定します。 名前はグローバルに一意である必要があります。
$dataFactoryName = "MyDataFactory09142017"パイプラインの名前を指定します。
$pipelineName = "MyHivePipeline" #セルフホステッド統合ランタイムの名前を指定します。 セルフホステッド統合ランタイムは、Data Factory が VNet 内のリソース (Azure SQL Database など) にアクセスする必要がある場合に必要になります。
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"PowerShellを起動します。 Azure PowerShell は、このクイックスタートが終わるまで開いたままにしておいてください。 Azure PowerShell を閉じて再度開いた場合は、これらのコマンドをもう一度実行する必要があります。 現在 Data Factory が利用できる Azure リージョンの一覧については、次のページで目的のリージョンを選択し、 [分析] を展開して [Data Factory] を探してください。リージョン別の利用可能な製品 データ ファクトリで使用するデータ ストア (Azure Storage、Azure SQL Database など) やコンピューティング (HDInsight など) は他のリージョンに配置できます。
次のコマンドを実行して、Azure Portal へのサインインに使用するユーザー名とパスワードを入力します。
Connect-AzAccount次のコマンドを実行して、このアカウントのすべてのサブスクリプションを表示します。
Get-AzSubscription次のコマンドを実行して、使用するサブスクリプションを選択します。 SubscriptionId は、実際の Azure サブスクリプションの ID に置き換えてください。
Select-AzSubscription -SubscriptionId "<SubscriptionId>"リソース グループを作成します。サブスクリプションにまだ ADFTutorialResourceGroup が存在しない場合は作成します。
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"データ ファクトリを作成します。
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupName次のコマンドを実行して、出力を表示します。
$df
セルフホステッド IR を作成する
このセクションでは、セルフホステッド統合ランタイムを作成し、HDInsight クラスターがある Azure 仮想ネットワーク内の Azure VM に関連付けます。
セルフホステッド統合ランタイムを作成します。 他の統合ランタイムと競合しない一意の名前を使用してください。
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHostedこのコマンドでは、セルフホステッド統合ランタイムの論理登録が作成されます。
PowerShell を使用して、セルフホステッド統合ランタイムを登録するための認証キーを取得します。 セルフホステッド統合ランタイムの登録に使用するいずれかのキーをコピーします。
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-Json出力例を次に示します。
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }AuthKey1 の値をメモしておきます。引用符は含めません。
Azure VM を作成し、HDInsight クラスターが含まれている仮想ネットワークに参加させます。 詳細については、仮想マシンの作成方法に関するページを参照してください。 Azure 仮想ネットワークに参加させます。
Azure VM で、セルフホステッド統合ランタイムをダウンロードします。 前の手順で取得した認証キーを使用して、セルフホステッド統合ランタイムを手動で登録します。
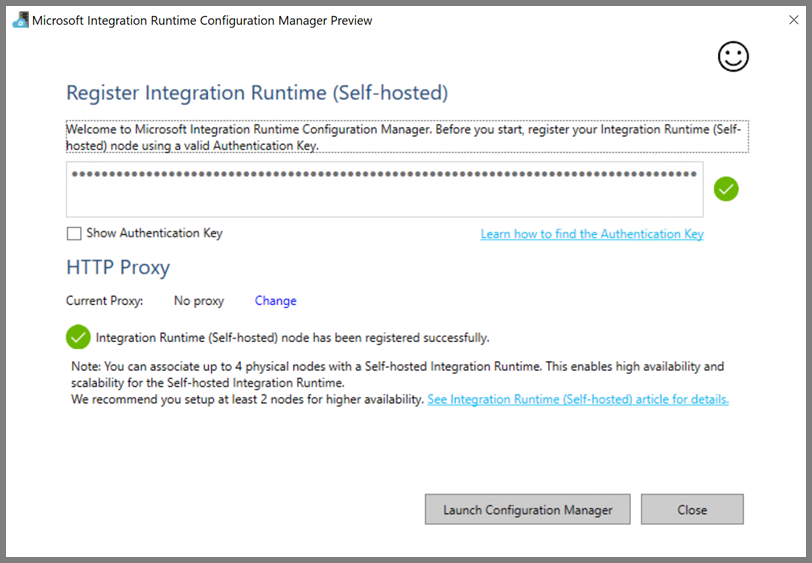
セルフホステッド統合ランタイムが正常に登録されると、次のメッセージが表示されます。
ノードがクラウド サービスに接続されると、次のページが表示されます。
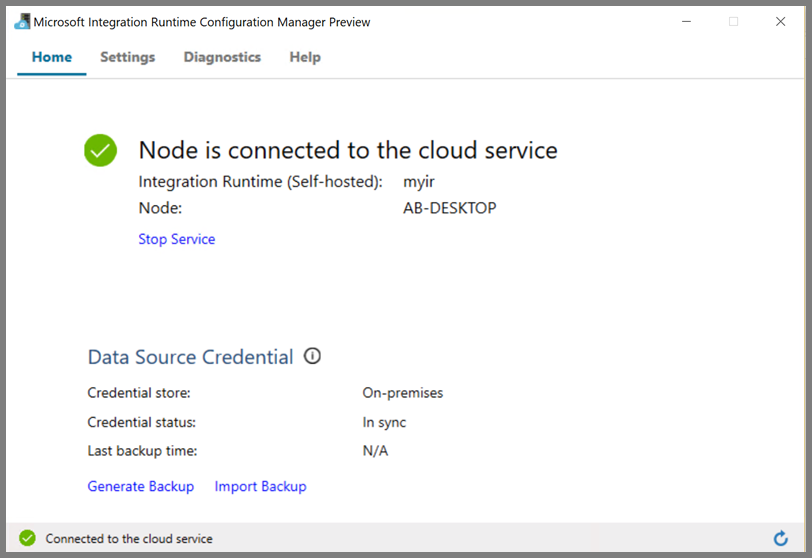
リンクされたサービスを作成する
このセクションでは、次の 2 つのリンクされたサービスを作成してデプロイします。
- Azure ストレージ アカウントをデータ ファクトリにリンクする、Azure Storage のリンクされたサービス。 このストレージは、HDInsight クラスターによって使用されるプライマリ ストレージです。 ここでは、Hive スクリプトとスクリプトの出力を保持するためにも、この Azure ストレージ アカウントを使用します。
- HDInsight のリンクされたサービス。 Hive スクリプトは、実行のために、Azure Data Factory によってこの HDInsight クラスターに送信されます。
Azure Storage のリンクされたサービス
任意のエディターを使用して JSON ファイルを作成し、Azure Storage のリンクされたサービスから次の JSON 定義をコピーして、ファイルを MyStorageLinkedService.json として保存します。
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
<accountname> と <accountkey> を Azure ストレージ アカウントの名前とキーに置き換えます。
HDInsight のリンクされたサービス
任意のエディターを使用して JSON ファイルを作成し、Azure HDInsight のリンクされたサービスから次の JSON 定義をコピーして、ファイルを MyHDInsightLinkedService.json として保存します。
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
リンクされたサービスの定義で、以下のプロパティの値を更新します。
userName。 クラスターの作成時に指定したクラスター ログイン ユーザーの名前。
password。 ユーザーのパスワードです。
clusterUri。 HDInsight クラスターの URL を次の形式で指定します:
https://<clustername>.azurehdinsight.net。 この記事では、インターネット経由でクラスターにアクセスできることが前提となっています。 たとえば、https://clustername.azurehdinsight.netでクラスターに接続できます。 このアドレスではパブリック ゲートウェイが使用されていますが、ネットワーク セキュリティ グループ (NSG) またはユーザー定義ルート (UDR) を使用してインターネットからのアクセスが制限されている場合は、このゲートウェイを使用できません。 Data Factory が Azure Virtual Network の HDInsight クラスターにジョブを送信するには、HDInsight によって使用されるゲートウェイのプライベート IP アドレスに URL を解決できるように、Azure Virtual Network を構成する必要があります。Azure Portal で、HDInsight がある仮想ネットワークを開きます。 名前が
nic-gateway-0で始まるネットワーク インターフェイスを開きます。 そのプライベート IP アドレスをメモしておきます。 たとえば、10.6.0.15 です。Azure 仮想ネットワークに DNS サーバーがある場合は、HDInsight クラスターの URL
https://<clustername>.azurehdinsight.netを10.6.0.15に解決できるように、DNS レコードを更新します。 これが推奨される方法です。 Azure 仮想ネットワークに DNS サーバーがない場合は、セルフホステッド統合ランタイム ノードとして登録されているすべての VM の hosts ファイル (C:\Windows\System32\drivers\etc) を編集し、次のようなエントリを追加することで、一時的にこれを回避することができます。10.6.0.15 myHDIClusterName.azurehdinsight.net
リンクされたサービスを作成します
PowerShell で、JSON ファイルを作成したフォルダーに移動し、次のコマンドを実行して、リンクされたサービスをデプロイします。
PowerShell で、JSON ファイルを作成したフォルダーに移動します。
次のコマンドを実行して、Azure Storage のリンクされたサービスを作成します。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"次のコマンドを実行して、Azure HDInsight のリンクされたサービスを作成します。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
パイプラインを作成する
この手順では、Hive アクティビティがある新しいパイプラインを作成します。 このアクティビティでは、Hive スクリプトを実行してサンプル テーブルからデータを返し、定義されたパスに保存します。 任意のエディターで JSON ファイルを作成し、パイプライン定義から次の JSON 定義をコピーして、MyHivePipeline.json として保存します。
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
以下の点に注意してください。
- scriptPath は、MyStorageLinkedService に使用した Azure ストレージ アカウントの Hive スクリプトへのパスを示します。 パスの大文字と小文字は区別されます。
- Output は、Hive スクリプトで使用される引数です。
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/の形式で、Azure ストレージ上の既存のフォルダーを指定します。 パスの大文字と小文字は区別されます。
JSON ファイルを作成したフォルダーに移動し、次のコマンドを実行して、パイプラインをデプロイします。
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
パイプラインを開始する
パイプラインの実行を開始します。 将来の監視のために、パイプラインの実行の ID もキャプチャされます。
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineName次のスクリプトを実行し、パイプラインの実行の状態を、完了するまで継続的にチェックします。
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"サンプル実行の出力結果を次に示します。
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"outputfolderフォルダーで、Hive クエリの結果として新しいファイルが作成されていることを確認します。次のサンプル出力のようになっているはずです。8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
関連するコンテンツ
このチュートリアルでは、以下の手順を実行しました。
- データ ファクトリを作成します。
- セルフホステッド統合ランタイムを作成して設定します
- リンクされたサービスを作成してデプロイします。
- Hive アクティビティが含まれたパイプラインを作成してデプロイします。
- パイプラインの実行を開始します。
- パイプラインの実行を監視します
- 出力を検証します。
次のチュートリアルに進み、Azure 上の Spark クラスターを使ってデータを変換する方法について学習しましょう。