PowerShell を使用して SQL Server にある複数のテーブルから Azure SQL Database にデータを増分読み込みする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、SQL Server データベースにある複数のテーブルから Azure SQL Database に差分データを読み込むパイプラインを使用して Azure データ ファクトリを作成します。
このチュートリアルでは、以下の手順を実行します。
- ソース データ ストアとターゲット データ ストアを準備します。
- データ ファクトリを作成します。
- セルフホステッド統合ランタイムを作成します。
- 統合ランタイムをインストールします。
- リンクされたサービスを作成します。
- ソース データセット、シンク データセット、および基準値データセットを作成します。
- パイプラインを作成、実行、監視します。
- 結果を確認します。
- ソース テーブルのデータを追加または更新します。
- パイプラインを再実行して監視します。
- 最終結果を確認します。
概要
このソリューションを作成するための重要な手順を次に示します。
基準値列を選択する。
ソース データ ストアのテーブルごとに、いずれか 1 つの列を選択します。この列は、実行ごとに新しいレコードまたは更新されたレコードを特定する目的で使用されます。 通常、行が作成または更新されたときに常にデータが増える列を選択します (last_modify_time、ID など)。 この列の最大値が基準値として使用されます。
基準値を格納するためのデータ ストアを準備する。
このチュートリアルでは、SQL データベースに基準値を格納します。
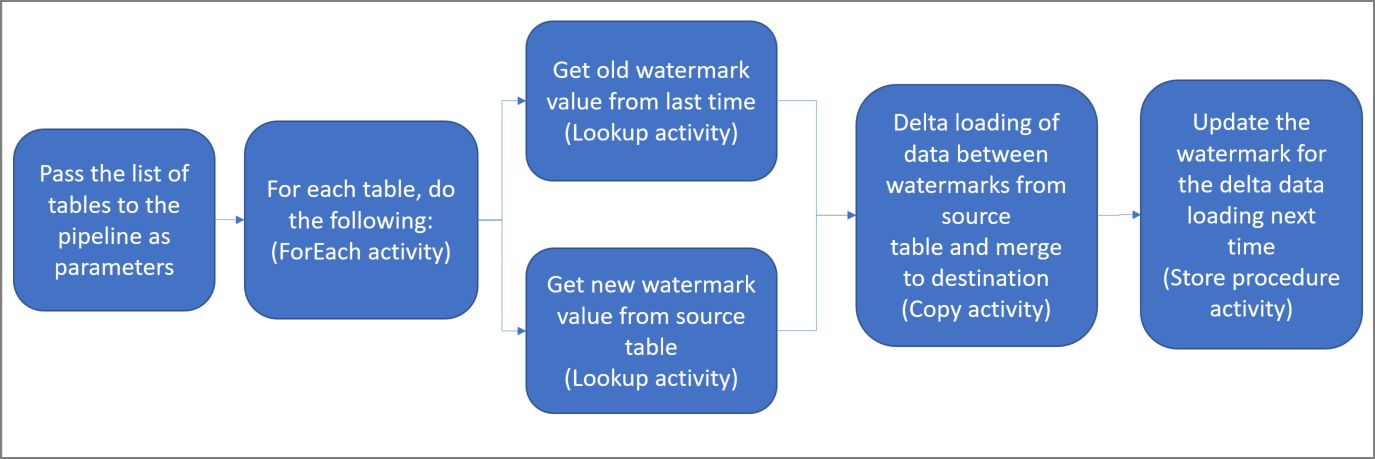
次のアクティビティを含んだパイプラインを作成する。
パイプラインにパラメーターとして渡された一連のソース テーブル名を反復処理する ForEach アクティビティを作成する。 このアクティビティが、ソース テーブルごとに次のアクティビティを呼び出して各テーブルの差分読み込みを実行します。
2 つのルックアップ アクティビティを作成する。 1 つ目のルックアップ アクティビティは、前回の基準値を取得するために使用します。 2 つ目のルックアップ アクティビティは、新しい基準値を取得するために使用します。 これらの基準値は、コピー アクティビティに渡されます。
コピー アクティビティを作成する。これは基準値列の値がかつての基準値より大きく、かつ新しい基準値以下の行をソース データ ストアからコピーするアクティビティです。 その差分データが、ソース データ ストアから新しいファイルとして Azure BLOB ストレージにコピーされます。
ストアド プロシージャ― アクティビティを作成する。これはパイプラインの次回実行に備えて基準値を更新するためのアクティビティです。
ソリューションの概略図を次に示します。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
- SQL Server。 このチュートリアルでは、SQL Server データベースをソース データ ストアとして使用します。
- Azure SQL データベース。 シンク データ ストアとして Azure SQL Database のデータベースを使用します。 SQL データベースがない場合の作成手順については、Azure SQL Database のデータベースの作成に関するページを参照してください。
SQL Server データベースにソース テーブルを作成する
SQL Server Management Studio (SSMS) または Azure Data Studio を開き、SQL Server データベースに接続します。
サーバー エクスプローラー (SSMS) または [接続] ペイン (Azure Data Studio) でデータベースを右クリックし、 [新しいクエリ] を選択します。
データベースに対して次の SQL コマンドを実行し、
customer_tableおよびproject_tableという名前のテーブルを作成します。create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Azure SQL Database にターゲット テーブルを作成する
SQL Server Management Studio (SSMS) または Azure Data Studio を開き、SQL Server データベースに接続します。
サーバー エクスプローラー (SSMS) または [接続] ペイン (Azure Data Studio) でデータベースを右クリックし、 [新しいクエリ] を選択します。
データベースに対して次の SQL コマンドを実行し、
customer_tableおよびproject_tableという名前のテーブルを作成します。create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
高基準値の格納用としてもう 1 つテーブルを Azure SQL Database に作成する
データベースに対して次の SQL コマンドを実行し、基準値の格納先として
watermarktableという名前のテーブルを作成します。create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );両方のソース テーブルの初期基準値を基準値テーブルに挿入します。
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Azure SQL Database にストアド プロシージャを作成する
次のコマンドを実行して、データベースにストアド プロシージャを作成します。 パイプラインの実行後は都度、このストアド プロシージャによって基準値が更新されます。
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Azure SQL Database にデータ型と新たなストアド プロシージャを作成する
次のクエリを実行して、2 つのストアド プロシージャと 2 つのデータ型をデータベースに作成します。 それらは、ソース テーブルから宛先テーブルにデータをマージするために使用されます。
作業工程を簡単に始められるように、差分データをテーブル変数を介して渡すこのようなストアド プロシージャを直接使用し、それらを宛先ストアにマージします。 テーブル変数には、"多数" の差分行 (100 を超える行) が格納されることが想定されていない点に注意してください。
多数の差分行を宛先ストアにマージする必要がある場合は、まずコピー アクティビティを使用してすべての差分データを宛先ストアの一時的な "ステージング" テーブルにコピーしてから、テーブル変数を使用せずに独自のストアド プロシージャを構築し、"ステージング" テーブルから "最終的な" テーブルにマージすることをお勧めします。
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
「Azure PowerShell のインストールおよび構成」の手順に従って、最新の Azure PowerShell モジュールをインストールしてください。
Data Factory の作成
後で PowerShell コマンドで使用できるように、リソース グループ名の変数を定義します。 次のコマンド テキストを PowerShell にコピーし、Azure リソース グループの名前を二重引用符で囲んで指定してコマンドを実行します。 たとえば
"adfrg"です。$resourceGroupName = "ADFTutorialResourceGroup";リソース グループが既に存在する場合は、上書きされないようにすることができます。
$resourceGroupName変数に別の値を割り当てて、コマンドをもう一度実行します。データ ファクトリの場所の変数を定義します。
$location = "East US"Azure リソース グループを作成するには、次のコマンドを実行します。
New-AzResourceGroup $resourceGroupName $locationリソース グループが既に存在する場合は、上書きされないようにすることができます。
$resourceGroupName変数に別の値を割り当てて、コマンドをもう一度実行します。データ ファクトリ名の変数を定義します。
重要
データ ファクトリ名は、グローバルに一意になるように更新してください。 たとえば、ADFIncMultiCopyTutorialFactorySP1127 とします。
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";データ ファクトリを作成するには、次の Set-AzDataFactoryV2 コマンドレットを実行します。
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
以下の点に注意してください。
データ ファクトリの名前はグローバルに一意にする必要があります。 次のエラーが発生した場合は、名前を変更してからもう一度実行してください。
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Data Factory インスタンスを作成するには、Azure へのサインインに使用するユーザー アカウントが、共同作成者または所有者ロールのメンバーであるか、Azure サブスクリプションの管理者である必要があります。
現在 Data Factory が利用できる Azure リージョンの一覧については、次のページで目的のリージョンを選択し、 [分析] を展開して [Data Factory] を探してください。リージョン別の利用可能な製品 データ ファクトリで使用するデータ ストア (Azure Storage、SQL Database、SQL Managed Instance など) とコンピューティング (Azure HDInsight など) は他のリージョンに配置できます。
自己ホスト型統合ランタイムを作成する
このセクションでは、セルフホステッド統合ランタイムを作成し、SQL Server データベースがあるオンプレミスのマシンに関連付けます。 セルフホステッド統合ランタイムは、マシンの SQL Server から Azure SQL Database にデータをコピーするコンポーネントです。
統合ランタイムの名前に使用する変数を作成します。 一意の名前を使用し、その名前をメモしておきます。 このチュートリアルの後の方で、それを使用します。
$integrationRuntimeName = "ADFTutorialIR"セルフホステッド統合ランタイムを作成します。
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName出力例を次に示します。
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIR作成された統合ランタイムの状態を取得するために、次のコマンドを実行します。 [状態] プロパティの値が [NeedRegistration] に設定されていることを確認します。
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Status出力例を次に示します。
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>次のコマンドを実行して、クラウドの Azure Data Factory サービスにセルフホステッド統合ランタイムを登録するために使用される認証キーを取得します。
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-Json出力例を次に示します。
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }次の手順でマシンにインストールするセルフホステッド統合ランタイムを登録するために使用するいずれかのキーをコピーします (二重引用符は除外します)。
統合ランタイム ツールをインストールする
既にマシンに統合ランタイムがインストールされている場合は、 [プログラムの追加と削除] を使用してそれをアンインストールします。
セルフホステッド統合ランタイムをローカルの Windows マシンにダウンロードします。 インストールを実行します。
[Welcome to Microsoft Integration Runtime Setup](Microsoft Integration Runtime セットアップへようこそ) ページで [次へ] を選択します。
[使用許諾契約書] ページで使用条件とライセンス契約に同意し、 [次へ] を選択します。
[インストール先フォルダー] ページで [次へ] を選択します。
[Ready to install Microsoft Integration Runtime](Microsoft Integration Runtime のインストール準備完了) ページで [インストール] を選択します。
[Completed the Microsoft Integration Runtime Setup](Microsoft Integration Runtime セットアップの完了) ページで [完了] を選択します。
[統合ランタイム (セルフホステッド) の登録] ページで、前のセクションで保存したキーを貼り付け、 [登録] を選択します。
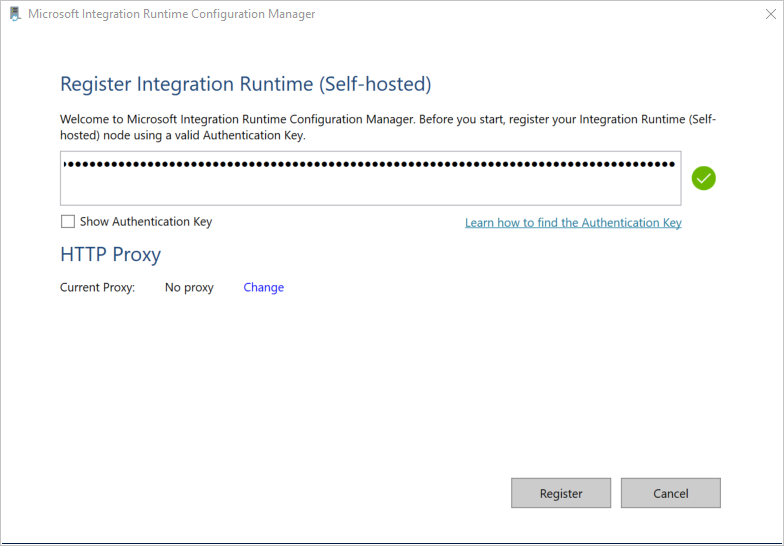
[新しい統合ランタイム (セルフホステッド) ノード] ページで [完了] を選択します。
セルフホステッド統合ランタイムが正常に登録されると、次のメッセージが表示されます。
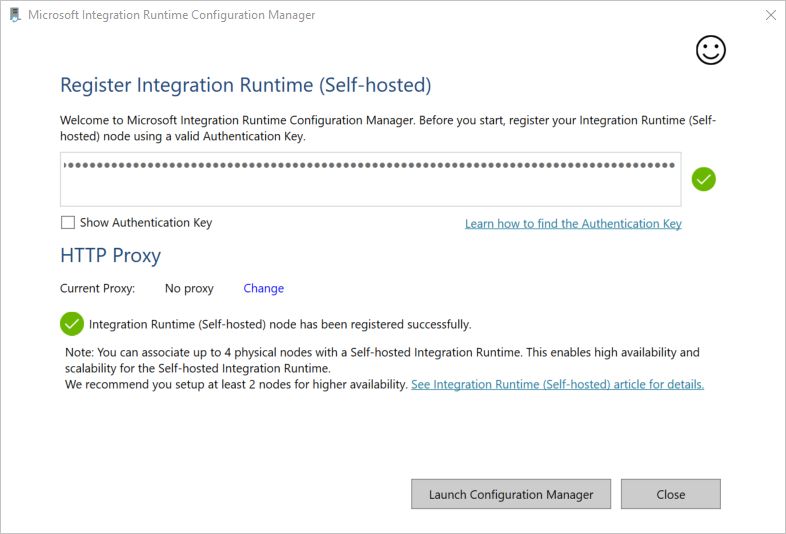
[統合ランタイム (セルフホステッド) の登録] ページで [構成マネージャーの起動] を選択します。
ノードがクラウド サービスに接続されると、次のページが表示されます。
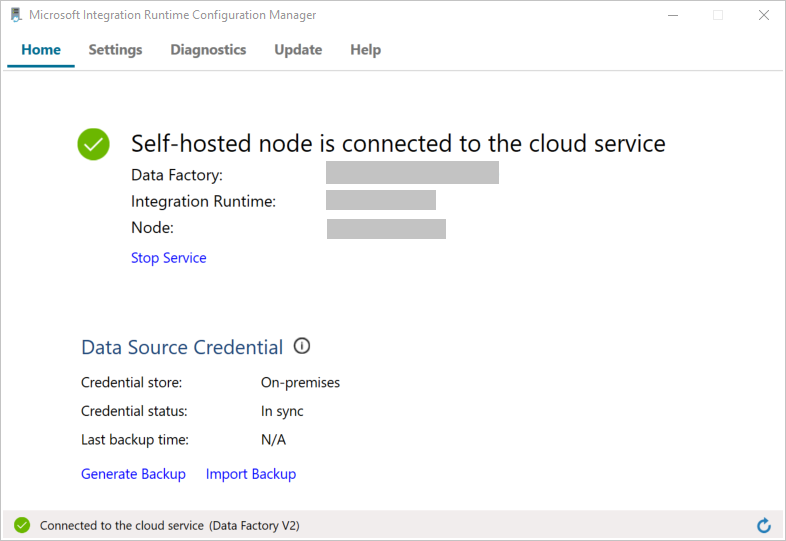
ここで、SQL Server データベースへの接続をテストします。
![[診断] タブ](includes/media/data-factory-create-install-integration-runtime/config-manager-diagnostics-tab.png)
a. [構成マネージャー] ページで、 [診断] タブに移動します。
b. [データ ソースの種類] として [SqlServer] を選択します。
c. サーバー名を入力します。
d. データベース名を入力します。
e. 認証モードを選択します。
f. ユーザー名を入力します。
g. ユーザー名に関連付けられているパスワードを入力します。
h. 統合ランタイムから SQL Server に接続できることを確認するために、 [テスト] を選択します。 接続が成功すると、緑色のチェック マークが表示されます。 接続が失敗した場合は、エラー メッセージが表示されます。 問題を修正し、統合ランタイムから SQL Server に接続できるようにします。
Note
認証の種類、サーバー、データベース、ユーザー、およびパスワードの値をメモしておきます。 このチュートリアルの後の方で使用します。
リンクされたサービスを作成します
データ ストアおよびコンピューティング サービスをデータ ファクトリにリンクするには、リンクされたサービスをデータ ファクトリに作成します。 このセクションでは、SQL Server データベースと、Azure SQL Database のデータベースに対するリンクされたサービスを作成します。
SQL Server のリンクされたサービスを作成する
この手順では、SQL Server データベースをデータ ファクトリにリンクします。
次の内容を記述した SqlServerLinkedService.json という名前の JSON ファイルを C:\ADFTutorials\IncCopyMultiTableTutorial フォルダー (まだ存在しない場合はローカル フォルダーを作成してください) に作成します。 SQL Server への接続に使用する認証に基づいて、右側のセクションを選択します。
重要
SQL Server への接続に使用する認証に基づいて、右側のセクションを選択します。
SQL 認証を使用する場合は、次の JSON 定義をコピーします。
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Windows 認証を使用する場合は、次の JSON 定義をコピーします。
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }重要
- SQL Server への接続に使用する認証に基づいて、右側のセクションを選択します。
- <integration runtime name> は、実際の統合ランタイムの名前に置き換えます。
- <servername>、<databasename>、<username>、および <password> を実際の SQL Server インスタンスの値に置き換えてからファイルを保存してください。
- ユーザー アカウントまたはサーバー名にスラッシュ文字 (
\) を使用する必要がある場合は、エスケープ文字 (\) を使用します。 たとえばmydomain\\myuserです。
PowerShell で次のコマンドを実行して、C:\ADFTutorials\IncCopyMultiTableTutorial フォルダーに切り替えます。
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Set-AzDataFactoryV2LinkedService コマンドレットを実行して、リンクされたサービス AzureStorageLinkedService を作成します。 次の例では、ResourceGroupName パラメーターと DataFactoryName パラメーターの値を渡しています。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"出力例を次に示します。
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
SQL Database のリンクされたサービスを作成する
次の内容を記述した AzureSQLDatabaseLinkedService.json という名前の JSON ファイルを C:\ADFTutorials\IncCopyMultiTableTutorial フォルダーに作成します (ADF フォルダーが存在しない場合は作成してください)。<servername>、<database name>、<user name>、<password> を実際の SQL Server データベースの名前、データベースの名前、ユーザー名、パスワードに置き換えてからファイルを保存してください。
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }PowerShell で Set-AzDataFactoryV2LinkedService コマンドレットを実行して、リンクされたサービス AzureSQLDatabaseLinkedService を作成します。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"出力例を次に示します。
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
データセットを作成する
この手順では、データ ソース、データの宛先、および基準値の格納場所を表すデータセットを作成します。
ソース データセットを作成する
以下の内容を記述した SourceDataset.json という名前の JSON ファイルを同じフォルダー内に作成します。
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }このパイプライン内のコピー アクティビティは、テーブル全体を読み込むことはせずに、SQL クエリを使用してデータを読み込みます。
Set-AzDataFactoryV2Dataset コマンドレットを実行して、データセット SourceDataset を作成します。
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"このコマンドレットの出力例を次に示します。
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
シンク データセットを作成する
次の内容を記述した SinkDataset.json という名前の JSON ファイルを同じフォルダー内に作成します。 tableName 要素は、実行時にパイプラインによって動的に設定されます。 パイプライン内の ForEach アクティビティは、一連のテーブル名を反復処理しながら、各イテレーションの中でこのデータセットにテーブル名を渡します。
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Set-AzDataFactoryV2Dataset コマンドレットを実行して、データセット SinkDataset を作成します。
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"このコマンドレットの出力例を次に示します。
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
基準値用のデータセットを作成する
この手順では、高基準値を格納するためのデータセットを作成します。
以下の内容を記述した WatermarkDataset.json という名前の JSON ファイルを同じフォルダー内に作成します。
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Set-AzDataFactoryV2Dataset コマンドレットを実行して、データセット WatermarkDataset を作成します。
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"このコマンドレットの出力例を次に示します。
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
パイプラインを作成する
このパイプラインは、一連のテーブル名をパラメーターとして受け取ります。 ForEach アクティビティは、一連のテーブル名を反復処理しながら、次の操作を実行します。
ルックアップ アクティビティを使用して古い基準値 (初期値または前回のイテレーションで使用された値) を取得します。
ルックアップ アクティビティを使用して新しい基準値 (ソース テーブルの基準値列の最大値) を取得します。
コピー アクティビティを使用して、この 2 つの基準値の間に存在するデータをソース データベースからターゲット データベースにコピーします。
ストアド プロシージャ アクティビティを使用して古い基準値を更新します。この値が、次のイテレーションの最初のステップで使用されます。
パイプラインを作成する
次の内容を記述した IncrementalCopyPipeline.json という名前の JSON ファイルを同じフォルダー内に作成します。
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Set-AzDataFactoryV2Pipeline コマンドレットを実行して、パイプライン IncrementalCopyPipeline を作成します。
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"出力例を次に示します。
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
パイプラインを実行する
次の内容を記述した Parameters.json という名前のパラメーター ファイルを同じフォルダーに作成します。
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Invoke-AzDataFactoryV2Pipeline コマンドレットを使って IncrementalCopyPipeline パイプラインを実行します。 プレースホルダーはそれぞれ実際のリソース グループとデータ ファクトリ名に置き換えてください。
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
パイプラインの監視
Azure portal にサインインします。
[すべてのサービス] を選択し、キーワード "データ ファクトリ" で検索して、 [データ ファクトリ] を選択します。
データ ファクトリの一覧から目的のデータ ファクトリを探して選択し、[データ ファクトリ] ページを開きます。
[データ ファクトリ] ページの [Open Azure Data Factory Studio] タイルで [開く] を選択して、別のタブで Azure Data Factory を起動します。
Azure Data Factory のホームページの左側で [モニター] を選択します。
すべてのパイプラインの実行とその状態を確認できます。 次の例では、パイプラインの実行が、成功状態であることに注目してください。 パイプラインに渡されたパラメーターを確認するには、 [パラメーター] 列のリンクを選択します。 エラーが発生した場合は、 [エラー] 列にリンクが表示されます。

[アクション] 列のリンクを選択すると、そのパイプラインに関するすべてのアクティビティの実行が表示されます。
再度パイプラインの実行ビューに移動するには、 [すべてのパイプラインの実行] を選択します。
結果の確認
SQL Server Management Studio からターゲット SQL データベースに対して次のクエリを実行し、ソース テーブルからターゲット テーブルにデータがコピーされていることを確かめます。
クエリ
select * from customer_table
出力
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
クエリ
select * from project_table
出力
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
クエリ
select * from watermarktable
出力
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
2 つのテーブルの基準値が更新されたことがわかります。
ソース テーブルにデータを追加する
コピー元の SQL Server データベースに次のクエリを実行して、customer_table 内の既存の行を更新します。 project_table に新しい行を挿入します。
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
パイプラインを再実行する
今度は、次の PowerShell コマンドを実行してパイプラインを再実行します。
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"「パイプラインの監視」セクションの手順に従ってパイプラインの実行を監視します。 パイプラインが進行中の状態にあるとき、 [アクション] には、パイプラインの実行をキャンセルするためのアクション リンクが別途表示されています。
パイプラインの実行に成功するまで、 [最新の情報に更新] を選択して一覧を更新します。
必要に応じて、 [アクション] の [View Activity Runs](アクティビティの実行の表示) リンクを選択すると、このパイプラインの実行に関連付けられているアクティビティの実行がすべて表示されます。
最終結果を確認する
SQL Server Management Studio からターゲット データベースに対して次のクエリを実行し、更新されたデータや新しいデータがソース テーブルからターゲット テーブルにコピーされていることを確かめます。
クエリ
select * from customer_table
出力
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
PersonID 3 を見ると、Name と LastModifytime が新しい値であることがわかります。
クエリ
select * from project_table
出力
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
project_table に NewProject というエントリが追加されていることがわかります。
クエリ
select * from watermarktable
出力
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
2 つのテーブルの基準値が更新されたことがわかります。
関連するコンテンツ
このチュートリアルでは、以下の手順を実行しました。
- ソース データ ストアとターゲット データ ストアを準備します。
- データ ファクトリを作成します。
- 自己ホスト型統合ランタイム (IR) を作成します。
- 統合ランタイムをインストールします。
- リンクされたサービスを作成します。
- ソース データセット、シンク データセット、および基準値データセットを作成します。
- パイプラインを作成、実行、監視します。
- 結果を確認します。
- ソース テーブルのデータを追加または更新します。
- パイプラインを再実行して監視します。
- 最終結果を確認します。
次のチュートリアルに進み、Azure 上の Spark クラスターを使ってデータを変換する方法について学習しましょう。