マッピング データ フローを使用して Delta Lake のデータを変換する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory を初めて使用する場合は、「Azure Data Factory の概要」を参照してください。
このチュートリアルでは、Azure Data Lake Storage (ADLS) Gen2 内のデータを分析して変換し、Delta Lake に格納することができるデータ フローを、データ フロー キャンバスを使用して作成します。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料の Azure アカウントを作成してください。
- Azure ストレージ アカウント。 ADLS ストレージを、ソースとシンクのデータ ストアとして使用します。 ストレージ アカウントがない場合の作成手順については、Azure のストレージ アカウントの作成に関するページを参照してください。
このチュートリアルで変換するファイルは MoviesDB.csv です (こちらで入手できます)。 GitHub からファイルを取得するには、コンテンツを任意のテキスト エディターにコピーして、.csv ファイルとしてローカルに保存します。 ファイルをご自分のストレージ アカウントにアップロードするには、Azure portal を使用した BLOB のアップロードに関するページを参照してください。 各例では、'sample-data' という名前のコンテナーを参照しています。
Data Factory の作成
この手順では、データ ファクトリを作成し、Data Factory UX を開いて、データ ファクトリにパイプラインを作成します。
Microsoft Edge または Google Chrome を開きます。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
a. [Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
b. [新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
[バージョン] で、 [V2] を選択します。
[場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリによって使用されるデータ ストア (Azure Storage、SQL Database など) やコンピューティング (Azure HDInsight など) は、他のリージョンに存在していてもかまいません。
[作成] を選択します
作成が完了すると、その旨が通知センターに表示されます。 [リソースに移動] を選択して、Data factory ページに移動します。
[Author & Monitor]\(作成と監視\) を選択して、別のタブで Data Factory (UI) を起動します。
データ フロー アクティビティが含まれるパイプラインの作成
この手順では、データ フロー アクティビティが含まれるパイプラインを作成します。
ホーム ページで [調整] を選択します。
パイプラインの [全般] タブで、パイプラインの名前として「DeltaLake」と入力します。
[アクティビティ] ウィンドウで、 [移動と変換] アコーディオンを展開します。 ウィンドウから Data Flow アクティビティをパイプライン キャンバスにドラッグ アンド ドロップします。
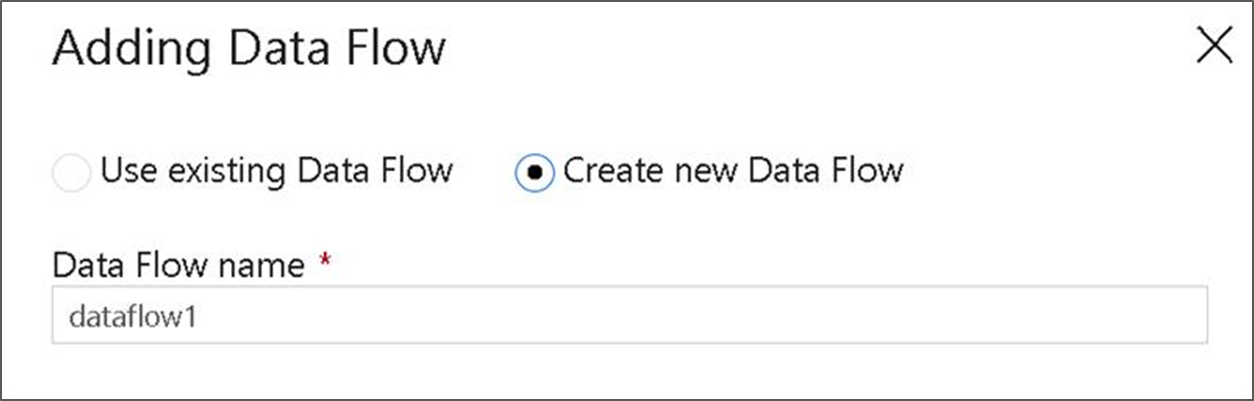
[Data Flow の追加] ポップアップで、 [新しい Data Flow の作成] を選択し、データ フローに DeltaLake という名前を付けます。 完了したら [完了] を選択します。
パイプライン キャンバスの上部のバーで、 [Data Flow のデバッグ] スライダーをオンにスライドします。 デバッグ モードを使用すると、ライブ Spark クラスターに対する変換ロジックの対話型テストが可能になります。 Data Flow クラスターのウォームアップには 5 から 7 分かかるため、ユーザーが Data Flow の開発を計画している場合は、最初にデバッグを有効にすることをお勧めします。 詳細については、デバッグ モードに関するページを参照してください。
![[データ フローのデバッグ] のスライダーを示すスクリーンショット。](media/tutorial-data-flow/dataflow1.png)
データ フロー キャンバスでの変換ロジックの作成
このチュートリアルでは、2 つのデータ フローを生成します。 最初のデータ フローは、映画の CSV ファイルから新しい Delta Lake を生成するためにシンクする単純なソースです。 最後に、Delta Lake の更新データに追従するフロー デザインを作成します。

チュートリアルの目標
- 前提条件の MoviesCSV データセット ソースを使用し、そこから新しい Delta Lake を形成します。
- 1988 年の映画の評価を '1' に更新するためのロジックを作成します。
- 1950 年のすべてのムービーを削除します。
- 1960 年のムービーを複製して 2021 年用の新しいムービーを挿入します。
空のデータ フロー キャンバスから開始する
データ フロー エディター ウィンドウの上部にある [ソース変換] を選択し、次に、[ソース設定] ウィンドウの [データ セット] プロパティの横にある [+ 新規] を選択します。
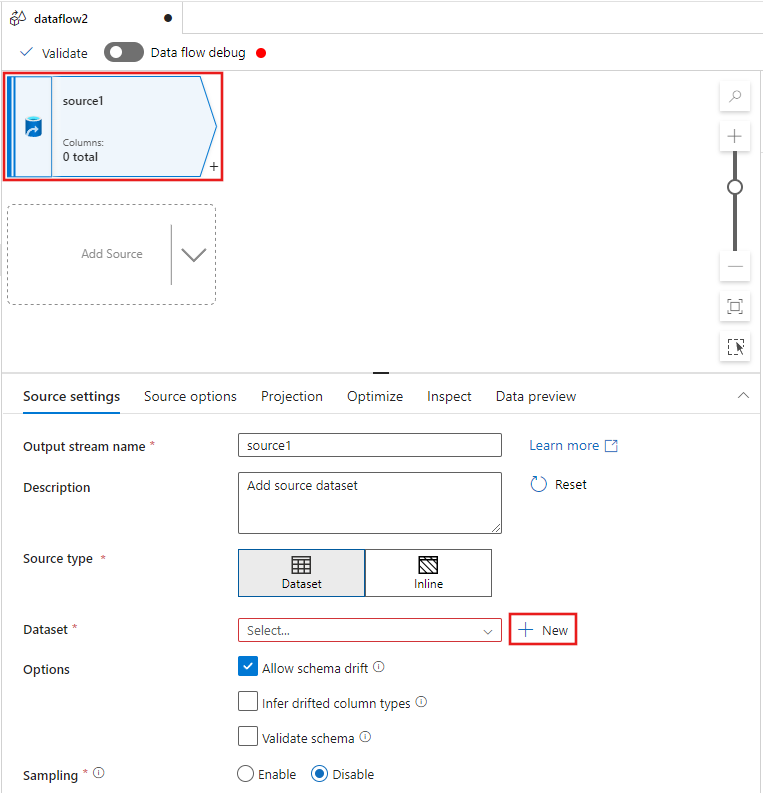
表示された [新しいデータセット] ウィンドウから [Azure Data Lake Storage Gen2] を選択し、次に [続行]を選択します。
![[新しいデータセット] ウィンドウで [Azure Data Lake Storage Gen2] を選択する場所を示すスクリーンショット。](media/tutorial-data-flow-delta-lake/select-azure-data-lake-storage-gen2.png)
データセットの種類には [DelimitedText] を選択し、もう一度 [続行] を選択します。

データセットに 「MoviesCSV」 という名前を付け、 [リンク サービス] で [+ 新規] を選択して、新しくファイルにリンク サービスを作成します。
「前提条件」セクションで先に作成したストレージ アカウントの詳細を入力し、そこでアップロードした MoviesCSV ファイルを参照し選択します。
リンク サービスを追加した後、[第一行をヘッダーとして選択] チェック ボックスをオンにし、[OK] を選択してソースを追加します。
データ フロー設定ウィンドウの [プロジェクション] タブに移動し、[データ型の検出] を選択します。
次に、データ フロー エディター ウィンドウのソースの後にある + を選択し、下にスクロールして、[宛先] セクションの下にある [シンク] を選択し、新しいシンクをデータ フローに追加します。
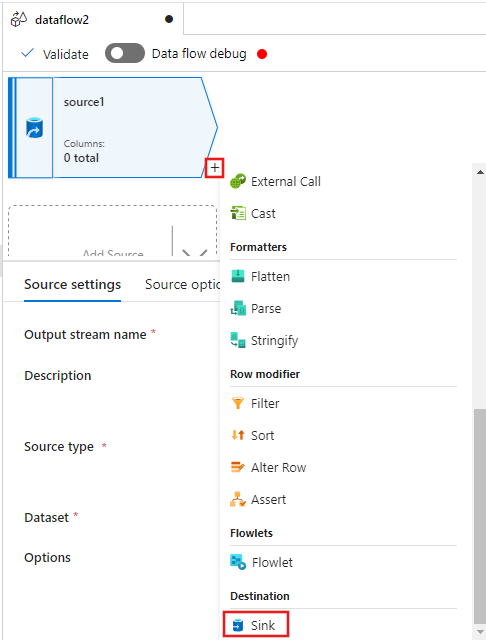
シンクの追加後に表示されるシンク設定の [シンク] タブで、[シンクの種類] に [インライン]を選択し、次に [インライン データセットの種類] では [Delta] を選択します。 次に、[リンク サービス] の [Azure Data Lake Storage Gen2] を選択します。
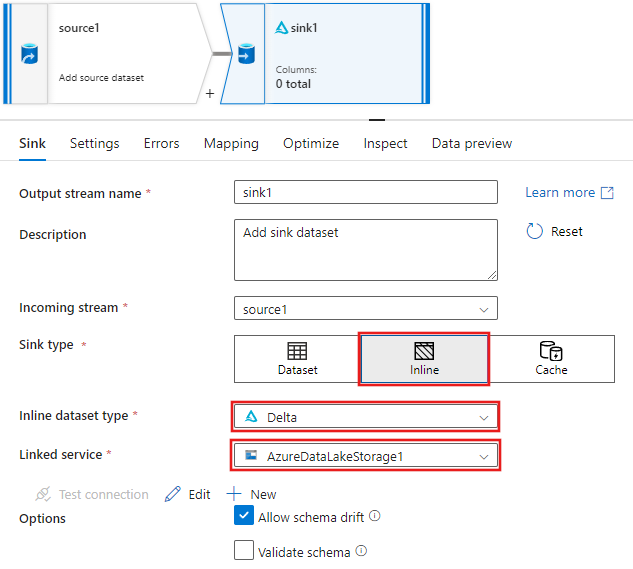
サービスに Delta Lake を作成させたいストレージ コンテナー内のフォルダー名を選択します。
最後に、パイプライン デザイナーに戻り、[デバッグ] をクリックして、キャンバス上のこのデータ フロー アクティビティだけを使用し、デバッグ モードでパイプラインを実行します。 これにより、Azure Data Lake Storage Gen2 の中に新しい Delta Lake が生成されます。
次に、画面の左側にある [ファクトリ リソース] メニューから + を選択して新しいリソースを追加した後で、[データ フロー] を選択します。
前と同様に、ソースとして MoviesCSV ファイルを再度選択し、[プロジェクション] タブから [データ型の検出] を選択します。
ここでは、ソースを作成した後に、データ フロー エディター ウィンドウで + を選択し、ソースにフィルター変換を追加します。
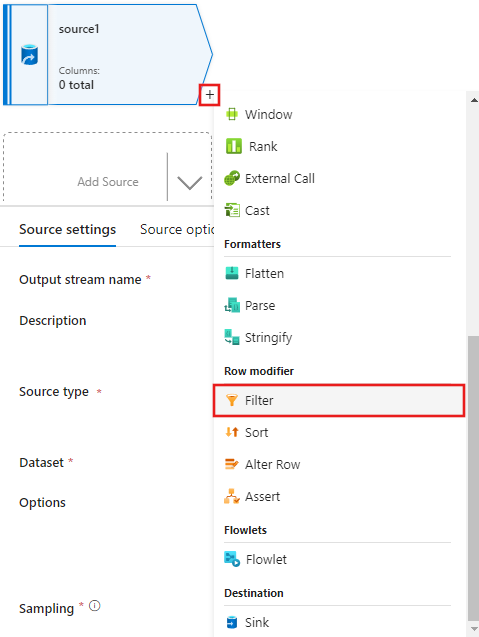
1950、1960、1988 に一致する映画行のみを許可する [フィルター 設定] ウィンドウに、[フィルター オン] 条件を追加します。
![データセットの [年] 列でフィルターを追加する場所を示すスクリーンショット。](media/tutorial-data-flow-delta-lake/add-year-filter.png)
次に、[派生列] 変換を追加して、1988 年の各映画の評価を '1' に更新します。

Update, insert, delete, and upsertポリシーは、行の変更変換で作成されます。 派生列の後に、行の変更変換を追加します。変更行ポリシーは、次のようになります。

変更行の種類ごとに適切なポリシーを設定したので、シンク変換に適切な更新ルールが設定されたことを確認します
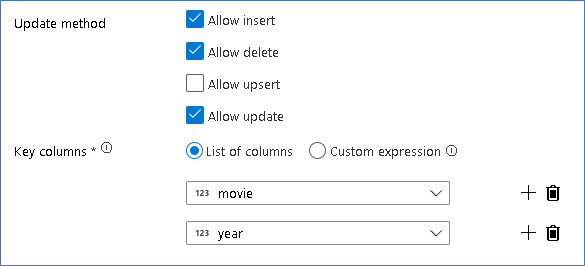
ここでは、Azure Data Lake Storage Gen2 データ レイクへの Delta Lake シンクを使用し、さらに挿入、更新、削除を許可します。
キー列は、映画の主キー列と年列で構成される複合キーであることに、注意してください。 これは、1960 年行を複製して仮の 2021 年ムービーを作成したためです。 こうして一意性を提供することによって、既存の行を検索するときの競合が回避されます。
完成したサンプルのダウンロード
レイクで行を更新または削除するためのデータ フローを使用する、Delta パイプラインのサンプル ソリューションをこちらで確認できます。
関連するコンテンツ
データ フローの式言語の詳細を確認します。