データ フロー スニペットを使用して行の重複を除去し、null を見つける
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新たに試用を開始する方法については、こちらをご覧ください。
マッピング データ フロー内でコード スニペットを使用すると、データの重複除去や null のフィルター処理などの一般的なタスクを、簡単に実行できます。 この記事では、データ フロー スクリプト スニペットを使用して、簡単にそれらの関数をパイプラインに追加する方法について説明します。
パイプラインを作成する
[新しいパイプライン] を選択します。
データ フロー アクティビティを追加します。
[ソースの設定] タブを選択し、ソース変換を追加し、それをデータセットの 1 つに接続します。
![ソースの種類を追加する [ソースの設定] ペインのスクリーンショット。](media/data-flow/snippet-adf-2.png)
この重複除去と null チェックのスニペットでは、汎用パターンを使用し、データ フローのスキーマの誤差を利用します。 これらのスニペットは、お使いのデータセットのどのスキーマでも、定義済みのスキーマがないデータセットでも機能します。
データ フロー スクリプト (DFS) の [すべての列を使用する個別の行] セクションで、DistinctRows のコード スニペットをコピーします。
データ フロー スクリプトに関するドキュメントのページに移動し、個別の行のためのコード スニペットをコピーします。
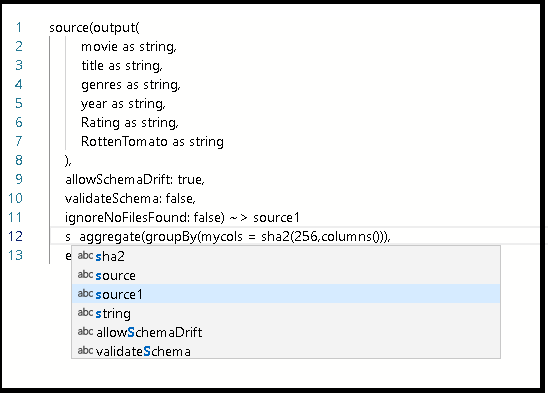
スクリプトで、
source1の定義の後に、Enter キーを押してからこのコード スニペットを貼り付けます。以下のいずれかを実行します。
貼り付けたコードの前に「source1」と入力することで、貼り付けたこのコード スニペットを、グラフ内に以前作成したソース変換に接続します。
または、グラフ内の新しい変換のノードから受信ストリームを選択しても、デザイナー内で新しい変換を接続できます。
![[Conditional split settings]\(条件付き分割設定\) ペインのスクリーンショット。](media/data-flow/snippet-adf-4.png)
これで、データ フローでは、すべての列値にわたって汎用のハッシュを適用してすべての行をグループ化する集計変換を使用して、ソースからの重複行の削除が行われます。
null がある行を含むストリームと、null がないもう 1 つのストリームにデータを分割するためのコード スニペットを追加します。 そのためには次を行います。
スニペットのライブラリに戻り、今回は、NULL チェック用のコードをコピーします。
b. データ フロー デザイナーで、 [スクリプト] をもう一度選択し、この新しい変換コードを下部に貼り付けます。 この操作により、貼り付けられたスニペットの前に、前の変換の名前を配置することで、スクリプトがその変換に接続されます。
データ フロー グラフはこれで次のようになるはずです。
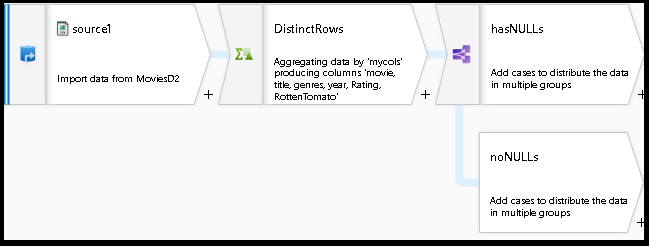
これで、データ フロー スクリプト ライブラリから既存のコード スニペットを取得し、それらを既存の設計に追加することで、汎用の重複除去と null チェックを備えた機能するデータ フローが作成されました。
関連するコンテンツ
- マッピング データ フローの変換を使用して、残りのデータ フロー ロジックを構築します。