Azure Data Factory および Azure Synapse Analytics での Excel ファイル形式
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Excel ファイルを解析する場合は、この記事に従ってください。 このサービスは ".xls" と ".xlsx" の両方に対応しています。
Excel 形式は、Amazon S3、Amazon S3 Compatible Storage、Azure Blob、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Azure Files、ファイル システム、FTP、Google Cloud Storage、HDFS、HTTP、Oracle Cloud Storage、SFTP の各コネクタでサポートされます。 これはソースとしてはサポートされていますが、シンクとしてはサポートされていません。
Note
".xls" 形式は、HTTP の使用中にはサポートされません。
データセットのプロパティ
データセットを定義するために使用できるセクションとプロパティの完全な一覧については、データセットに関する記事をご覧ください。 このセクションでは、Excel データセットでサポートされるプロパティの一覧を示します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、Excel に設定する必要があります。 | はい |
| location | ファイルの場所の設定。 ファイル ベースの各コネクタには、固有の場所の種類と location でサポートされるプロパティがあります。 |
はい |
| sheetName | データを読み取る Excel ワークシートの名前。 |
sheetName または sheetIndex を指定します |
| sheetIndex | データを読み取る Excel ワークシートのインデックス (0 から開始)。 |
sheetName または sheetIndex を指定します |
| range | 特定のワークシート内で選択データを見つけるセル範囲。例: - 指定なし: 空ではない最初の行と列からワークシート全体を表として読み取ります - A3: 特定のセルから始まる表を読み取り、下にあるすべての行と右にあるすべての列を動的に検出します- A3:H5: この固定範囲を表として読み取ります- A3:A3: この単一セルを読み取ります |
いいえ |
| firstRowAsHeader | 指定したワークシート (または範囲) 内の先頭行を、列名を含んだヘッダー行として扱うかどうかを指定します。 使用できる値は true と false (既定値) です。 |
いいえ |
| nullValue | null 値の文字列表現を指定します。 既定値は空の文字列です。 |
いいえ |
| compression | ファイル圧縮を構成するためのプロパティのグループ。 アクティビティの実行中に圧縮/圧縮解除を行う場合は、このセクションを構成します。 | いいえ |
| type ( compression の下にあります) |
JSON ファイルの読み取り/書き込みに使用される圧縮コーデックです。 使用できる値は、bzip2、gzip、deflate、ZipDeflate、TarGzip、Tar、snappy、または lz4 です。 既定では圧縮されません。 現在、Copy アクティビティでは "snappy" と "lz4" がサポートされておらず、マッピング データ フローでは "ZipDeflate"、"TarGzip"、"Tar" がサポートされていないことに注意してください。 コピー アクティビティを使用して ZipDeflate ファイルを展開し、ファイルベースのシンク データ ストアに書き込むと、 <path specified in dataset>/<folder named as source zip file>/ フォルダーにファイルが抽出されることに注意してください。 |
いいえ。 |
| level ( compression の下にあります) |
圧縮率です。 使用できる値は、Optimal または Fastest です。 - 最速: 圧縮操作は可能な限り短時間で完了しますが、生成ファイルが最適に圧縮されない場合があります。 - Optimal:圧縮操作で最適に圧縮されますが、操作が完了するまでに時間がかかる場合があります。 詳細については、 圧縮レベル に関するトピックをご覧ください。 |
いいえ |
Azure Blob Storage 上の Excel データセットの例を次に示します。
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。 このセクションでは、Excel ソースでサポートされるプロパティの一覧を示します。
ソースとしての Excel
Copy アクティビティの *source* セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティを ExcelSource に設定する必要があります。 | はい |
| storeSettings | データ ストアからデータを読み取る方法を指定するプロパティのグループ。 ファイル ベースの各コネクタには、storeSettings に、固有のサポートされる読み取り設定があります。 |
いいえ |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Mapping Data Flow のプロパティ
マッピング データ フローでは、次のデータ ストアで Excel 形式を読み取ることができます: Azure Blob Storage、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2、Amazon S3、および SFTP。 Excel ファイルは、Excel データセットまたはインライン データセットを使用して参照できます。
ソースのプロパティ
次の表に、Excel ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、[ソース オプション] タブで編集できます。インライン データセットを使用する場合は追加のファイル設定が表示されます。これは、「データセットのプロパティ」セクションで説明したプロパティと同じものです。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| ワイルド カードのパス | ワイルドカードのパスに一致するすべてのファイルが処理されます。 データセットで設定されているフォルダーとファイル パスはオーバーライドされます。 | no | String[] | wildcardPaths |
| パーティションのルート パス | パーティション分割されたファイル データについては、パーティション フォルダーを列として読み取るためにパーティションのルート パスを入力できます | no | String | partitionRootPath |
| ファイルの一覧 | 処理するファイルを一覧表示しているテキスト ファイルをソースが指しているかどうか | no |
true または false |
fileList |
| ファイル名を格納する列 | ソース ファイル名とパスを使用して新しい列を作成します | no | String | rowUrlColumn |
| 完了後 | 処理後にファイルを削除または移動します。 ファイル パスはコンテナー ルートから始まります | no | 削除: true または false 移動: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 最終更新日時でフィルター処理 | 最後に変更された日時に基づいてファイルをフィルター処理する場合に選択 | no | Timestamp | modifiedAfter modifiedBefore |
| [Allow no files found](ファイルの未検出を許可) | true の場合、ファイルが見つからない場合でもエラーはスローされない | no |
true または false |
ignoreNoFilesFound |
ソースの例
次の図は、データセット モードを使用したマッピング データ フローにおける Excel ソースの構成例です。
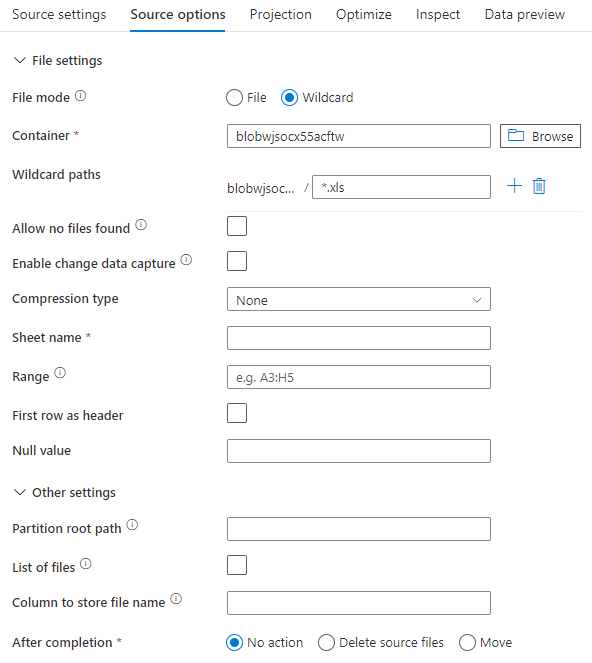
関連付けられているデータ フロー スクリプトは次のとおりです。
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
インライン データセットを使用する場合、マッピング データ フローに次のソース オプションが表示されます。
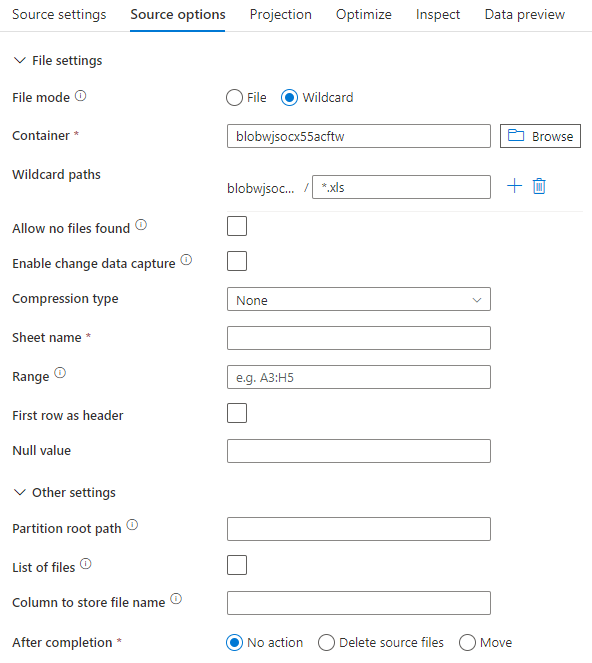
関連付けられているデータ フロー スクリプトは次のとおりです。
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Note
マッピング データ フローは、読み取り保護の Excel ファイルをサポートしていません。これは、これらのファイルには、機密性に関する通知が含まれている場合や、コンテンツへのアクセスを制限する特定のアクセス制限が強制されている場合があるためです。
非常に大きな Excel ファイルの処理
Excel コネクタは、Copy アクティビティのストリーミング読み取りをサポートしていないため、データを読み取る前にファイル全体をメモリに読み込む必要があります。 スキーマをインポートしたり、データをプレビューしたり、Excel データセットを更新したりするには、HTTP 要求タイムアウト (100 秒) 前にデータを返す必要があります。 大きな Excel ファイルの場合、これらの操作がその時間枠内に完了しない可能性があり、タイムアウト エラーが発生します。 大きなサイズの Excel ファイル (>100 MB) を別のデータ ストアに移動する場合は、次のいずれかのオプションを使用してこの制限を回避できます。
- セルフホステッド統合ランタイム (SHIR) を使用し、Copy アクティビティを使用して、大きな Excel ファイルを SHIR を使用して別のデータ ストアに移動します。
- 大きなファイル Excel 複数の小さなファイルに分割した後、Copy アクティビティを使用して、ファイルを含むフォルダーを移動します。
- データフロー アクティビティを使用して、大きな Excel ファイルを別のデータ ストアに移動します。 データフローでは、Excel のストリーミング読み取りをサポートしており、大きなファイルをすばやく移動/転送できます。
- 大きな Excel ファイルを CSV 形式に手動で変換した後、Copy アクティビティを使用してそのファイルを移動します。