マッピング データ フローでの変換を解析する
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
変換解析を使用して、データ内のテキスト列を解析します。このテキスト列は、ドキュメント形式の文字列です。 現在サポートされている解析可能な埋め込みドキュメントの種類は、JSON、XML、区切りテキストです。
構成
変換解析の構成パネルで、最初に、インラインで解析する列に含まれているデータの種類を選択します。 変換解析には、次の構成設定も含まれています。

列
派生列や集計と同様に、列プロパティでは、ドロップダウン ピッカーから選択して既存の列を変更できます。 または、ここに新しい列の名前を入力することもできます。 ADF により、解析されたソース データがこの列に格納されます。 ほとんどの場合は、受信する埋め込みドキュメント文字列フィールドを解析する新しい列を定義します。
Expression
式ビルダーを使用して、解析対象のソースを設定します。 ソースの設定は、解析する自己完結型データが含まれたソース列を選択するだけで簡単に行うことができます。または、解析するための複雑な式を作成することもできます。
式の例
ソース文字列データ:
chrome|steel|plastic- 式:
(desc1 as string, desc2 as string, desc3 as string)
- 式:
ソース JSON データ:
{"ts":1409318650332,"userId":"309","sessionId":1879,"page":"NextSong","auth":"Logged In","method":"PUT","status":200,"level":"free","itemInSession":2,"registration":1384448}- 式:
(level as string, registration as long)
- 式:
ソースの入れ子になった JSON データ:
{"car" : {"model" : "camaro", "year" : 1989}, "color" : "white", "transmission" : "v8"}- 式:
(car as (model as string, year as integer), color as string, transmission as string)
- 式:
ソース XML データ:
<Customers><Customer>122</Customer><CompanyName>Great Lakes Food Market</CompanyName></Customers>- 式:
(Customers as (Customer as integer, CompanyName as string))
- 式:
属性データを含むソース XML:
<cars><car model="camaro"><year>1989</year></car></cars>- 式:
(cars as (car as ({@model} as string, year as integer)))
- 式:
予約文字を使用する数式:
{ "best-score": { "section 1": 1234 } }best-scoreの '-' 文字は減算演算として解釈されるため、上記の式は機能しません。 次のような場合は、JSON エンジンにテキストを文字どおりに解釈するように指示するため、かっこ表記を含む変数を使用します。var bestScore = data["best-score"]; { bestScore : { "section 1": 1234 } }
注: 複合型からの属性 (特に、@model) の抽出でエラーが発生した場合、対応策として、複合型を文字列に変換して、@ 記号を削除 (特に、replace(toString(your_xml_string_parsed_column_name.cars.car),'@','') ) し、JSON 変換解析アクティビティを使用します。
出力列の種類
ここでは、1 つの列に書き込まれる、解析からのターゲット出力スキーマを構成します。 解析から出力のスキーマを設定する最も簡単な方法は、式ビルダーの右上にある [型の検出] ボタンを選択する方法です。 ADF は、解析する文字列フィールドからスキーマの自動検出を試み、出力式で設定しようとします。
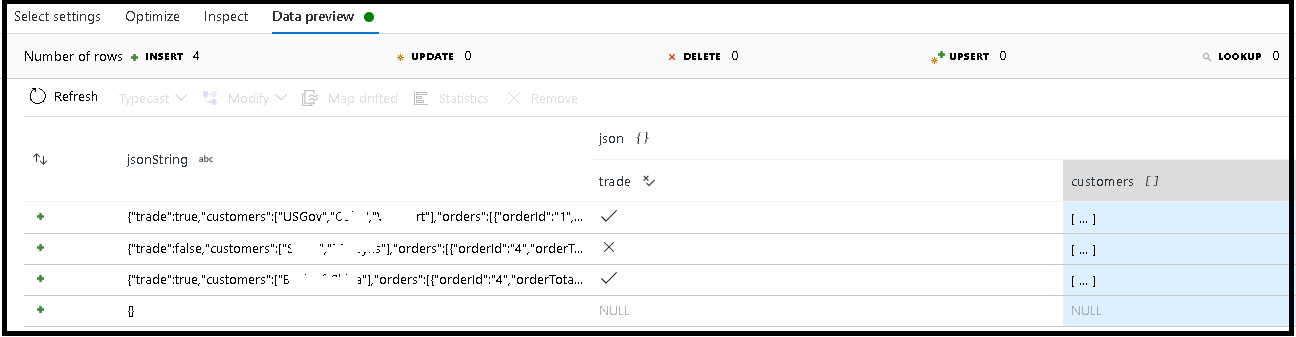
この例では、受信フィールド "jsonString" の解析を定義しています。これはプレーンテキストですが、JSON 構造体として書式設定されています。 次のスキーマを使用して、解析結果を JSON として "json" という名前の新しい列に格納します。
(trade as boolean, customers as string[])
[検査] タブと [データのプレビュー] を参照して、出力が適切にマッピングされていることを確認します。
派生列アクティビティを使用して階層データ (つまり、式フィールドの your_complex_column_name.car.model) を抽出します
使用例
source(output(
name as string,
location as string,
satellites as string[],
goods as (trade as boolean, customers as string[], orders as (orderId as string, orderTotal as double, shipped as (orderItems as (itemName as string, itemQty as string)[]))[])
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
documentForm: 'documentPerLine') ~> JsonSource
source(output(
movieId as string,
title as string,
genres as string
),
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false) ~> CsvSource
JsonSource derive(jsonString = toString(goods)) ~> StringifyJson
StringifyJson parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json',
documentForm: 'arrayOfDocuments') ~> ParseJson
CsvSource derive(csvString = 'Id|name|year\n\'1\'|\'test1\'|\'1999\'') ~> CsvString
CsvString parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv
ParseJson select(mapColumn(
jsonString,
json
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedJson
ParseCsv select(mapColumn(
csvString,
csv
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> KeepStringAndParsedCsv
データ フローのスクリプト
構文
例
parse(json = jsonString ? (trade as boolean,
customers as string[]),
format: 'json|XML|delimited',
documentForm: 'singleDocument') ~> ParseJson
parse(csv = csvString ? (id as integer,
name as string,
year as string),
format: 'delimited',
columnNamesAsHeader: true,
columnDelimiter: '|',
nullValue: '',
documentForm: 'documentPerLine') ~> ParseCsv