マッピング データ フローでのアサート変換
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローは、Azure Data Factory および Azure Synapse Pipelines の両方で使用できます。 この記事は、マッピング データ フローに適用されます。 変換を初めて使用する場合は、概要の記事「マッピング データ フローを使用してデータを変換する」を参照してください。
アサート変換を使用すると、データ品質とデータ検証のためのカスタム ルールをマッピング データ フロー内に作成できます。 予想される値ドメインを値が満たしているかどうかを判断するルールを作成できます。 また、行の一意性をチェックするルールを作成することもできます。 アサート変換は、データの各行が一連の条件を満たすかどうかを判断するのに役立ちます。 アサート変換では、データ検証ルールが満たされていない場合のカスタム エラー メッセージを設定することもできます。
構成
アサート変換構成パネルで、アサートの種類を選択し、アサーションの一意の名前と省略可能な説明を指定し、式と省略可能なフィルターを定義します。 データ プレビュー ウィンドウには、アサーションに失敗した行が表示されます。 さらに、アサーションに失敗した行に対して、isError() と hasError() を使用して、ダウンストリームの各行タグをテストできます。
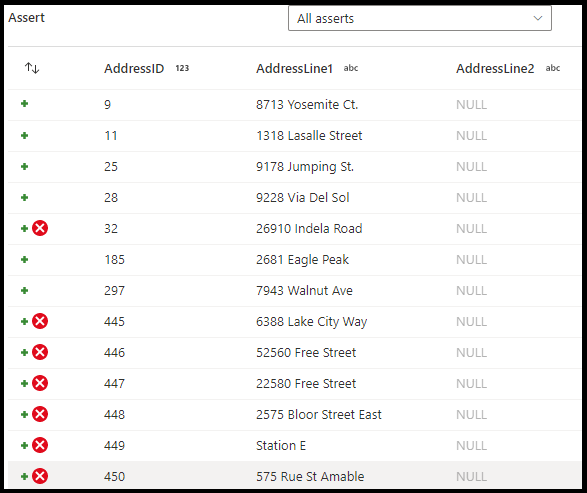
Assert の種類
- Expect true(true を予期): 式の結果はブール型の true の結果に評価される必要があります。 データ内のドメイン値の範囲を検証するには、この設定を使います。
- Expect unique(一意を予期): 列または式をデータ内の一意性ルールとして設定します。 重複する行にタグを付けするには、この設定を使います。
- Expect exists: このオプションは、2 つ目の着信ストリームを選んだ場合にのみ使用できます。 exists は、両方のストリームを調べ、指定した列または式に基づいて、両方のストリームに行が存在するかどうかを判断します。 Exists(存在) の 2 番目のストリームを追加するには、
Additional streamsを選択します。
データ フローの失敗
アサーション ルールが失敗したらすぐにデータ フロー アクティビティを失敗させる場合、fail data flow を選択します。
アサート ID
アサート ID は、アサーションの名前 (文字列) を入力するプロパティです。 後で hasError() を使ってデータ フローのダウンストリームで識別子を使ったり、アサーション失敗コードを出力したりできます。 アサート ID は、各データフロー内で一意である必要があります。
アサートの説明
アサーションの説明の文字列をここに入力します。 ここでは式と行コンテキスト列の値も使用できます。
フィルター
フィルターは省略可能なプロパティであり、式の値に基づいてアサーションをフィルター処理し、行のサブセットのみを取得できます。
Expression
各アサーションを評価するための式を入力します。 アサート変換ごとに複数のアサーションを使用できます。 アサーションの各種類には、アサーションが合格したかどうかをテストするために ADF が評価する必要がある式が必要です。
NUL を無視する
既定では、アサート変換の行アサーション評価には NULL が含まれます。 このプロパティを使用して、NULL を無視することを選択できます。
アサート行のエラーの転送
アサーションが失敗した場合は、必要に応じて、シンク変換の [エラー] タブを使用して、それらのエラー行を Azure のファイルに転送できます。 また、シンク変換には、エラー行を無視してアサーションに失敗した行をまったく出力しないオプションもあります。
例
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
データ フローのスクリプト
例
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1