データ フローの監視
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ フローの作成とデバッグが完了したら、データ フローをスケジュールし、そのスケジュールに基づいて、パイプラインのコンテキスト内でデータ フローを実行する必要があります。 パイプラインをスケジュールするときは、トリガーを使用します。 パイプラインからのデータ フローをテストおよびデバッグする場合は、ツール バー リボンの [デバッグ] ボタンまたはパイプライン ビルダーの [今すぐトリガー] オプションを使用して、単一実行を行い、パイプライン コンテキスト内でデータ フローをテストできます。
パイプラインを実行するときは、パイプラインとその中に含まれるすべてのアクティビティ (データ フロー アクティビティなど) を監視できます。 左側の UI パネル内にある監視アイコンを選択します。 次のような画面が表示されます。 強調表示されているアイコンを使用すると、パイプライン内のアクティビティ (データ フロー アクティビティなど) にドリルダウンできます。
実行時間や状態など、このレベルでの統計も表示されます。 アクティビティ レベルの実行 ID は、パイプライン レベルの実行 ID とは異なります。 以前のレベルの実行 ID は、パイプラインの実行 ID です。 眼鏡を選択すると、データ フローの実行に関する詳細が示されます。

グラフィカルなノード監視ビューを開いているときは、表示専用のシンプルなバージョンのデータ フロー グラフが表示されます。 変換ステージ ラベルが含まれる大きなグラフ ノードの詳細ビューを表示するには、キャンバスの右側にあるズーム スライダーを使用します。 右側の検索ボタンを使用して、グラフでデータ フロー ロジックの一部を検索することもできます。
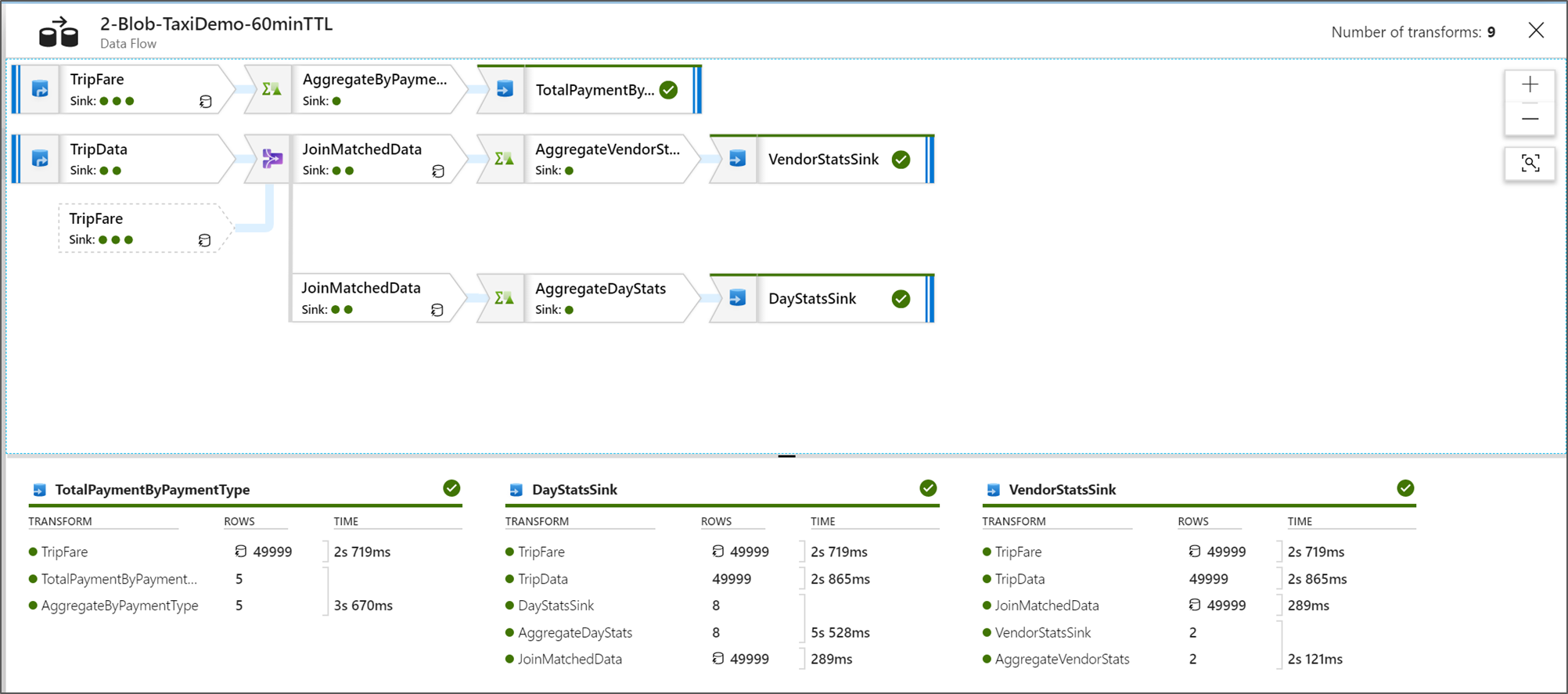
データ フローの実行プランの表示
Data Flow が Spark で実行されると、データ フロー全体に基づいて、最適なコード パスが決定されます。 実行パスが別のスケールアウト ノードやデータ パーティション上に出現する場合もあります。 したがって、監視グラフでは、変換の実行パスを考慮して、フローのデザインが表示されています。 個々のノードを選択すると、クラスター上で同時に実行されたコードを表す "ステージ" が表示されます。 表示されるタイミングとカウントは、デザイン内の個々のステップではなく、それらのグループまたはステージを表しています。
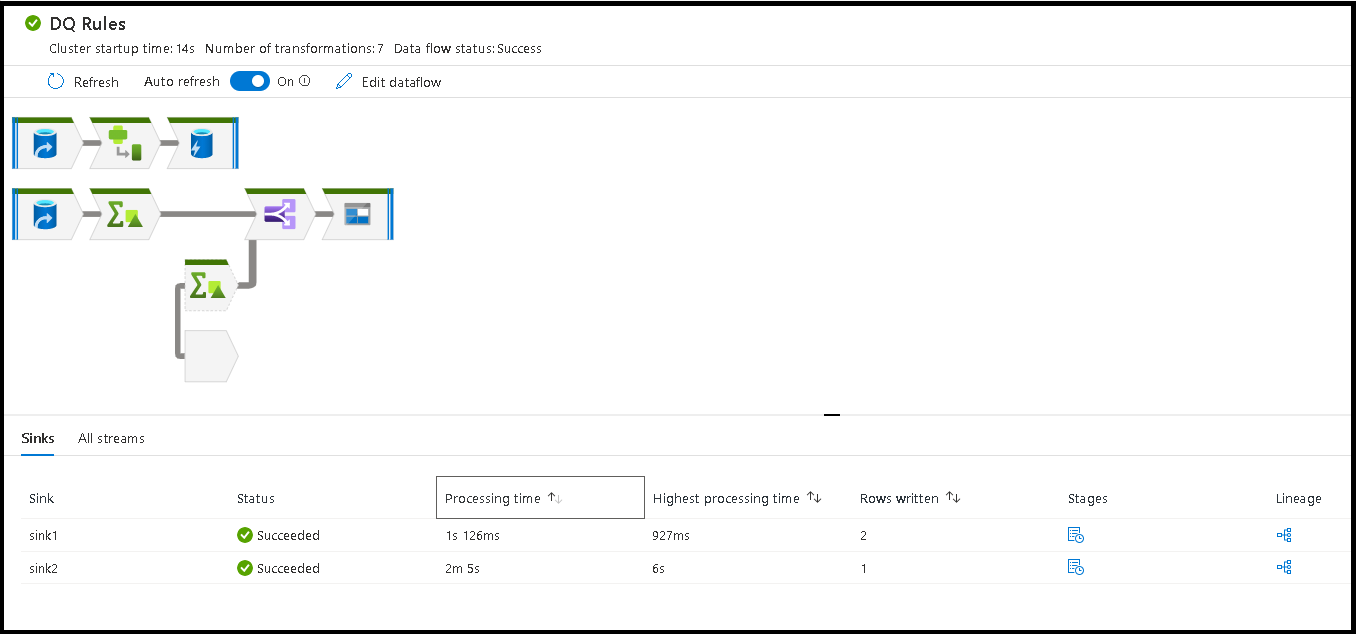
監視ウィンドウ内の空間を選択すると、下部のウィンドウ内の統計に、各シンクのタイミングと行数、および変換系列のシンク データの基になる変換が表示されます。
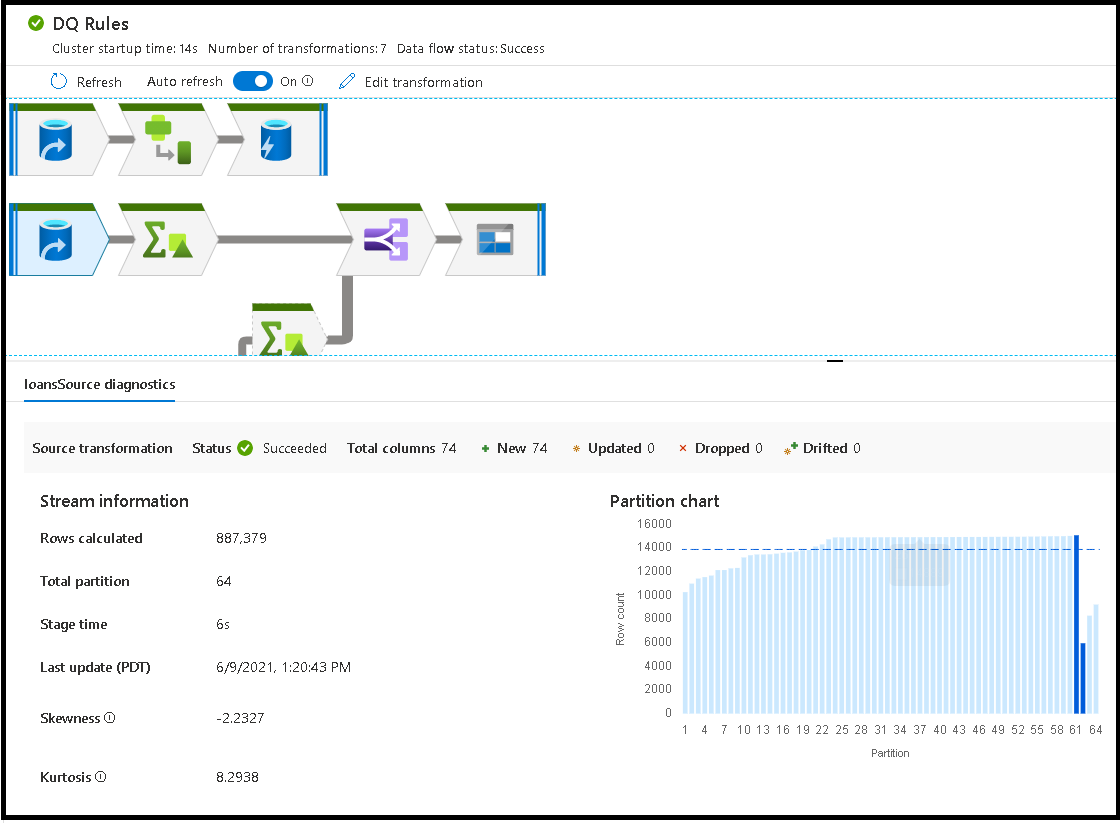
個々の変換を選択すると、パーティションの統計、列数、歪度 (パーティション全体で分散されたデータの均等さ)、尖度 (データのスパイクの程度) を示す追加のフィードバックが右側のパネルに表示されます。
"処理時間" で並べ替えると、データ フローで最も時間がかかったステージを特定するのに役立ちます。
各ステージ内で最も時間がかかった変換を見つけるには、"処理時間の上限" の順に並べ替えます。
また、"書き込まれた行数" で並べ替えると、データ フロー内で最も多くのデータを書き込んでいるストリームを識別できます。
ノード ビュー内で [シンク] を選択すると、列の系列が表示されます。 データ フローを通じてシンクのランドに列が累積される方法には、3 種類あります。 これらは次のとおりです。
- 計算:列は、条件付き処理、またはデータ フローの式内で使用しますが、シンク内には置かないでください。
- 派生: 列は、フロー内で生成した新しい列です。つまり、ソース内には存在していなかったものです
- マップ: 列は、ソースから発生しており、シンク フィールドにマッピングされています
- データ フローの状態:実行の現在の状態
- クラスターの起動時間:データ フロー実行のための JIT Spark コンピューティング環境を取得する時間
- 変換の数:フロー内で実行されている変換ステップの数
![スクリーンショットに、[更新] オプションが示されています。](media/data-flow/monitornew.png)
合計シンク処理時間と変換処理時間
各変換ステージには、そのステージを完了するまでの合計時間と、各パーティションの実行時間の合計が含まれます。 [シンク] を選択すると、"シンク処理時間" が表示されます。 この時間には、変換時間の合計に "加えて"、データを保存先ストアに書き込むために要した I/O 時間が含まれます。 シンク処理時間と変換の合計との違いは、データを書き込むための I/O 時間です。
また、パイプラインの監視ビューでデータ フロー アクティビティからの JSON 出力を開くと、各パーティション変換手順の詳細なタイミングも確認できます。 JSON には各パーティションのミリ秒のタイミングが含まれていますが、UX 監視ビューには各パーティションを加算した集計時間が示されます。
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
シンク処理時間
マップでシンク変換アイコンを選択すると、右側のスライドイン パネルの下部に "後処理時間" という追加のデータ ポイントが表示されます。 これは、データが読み込まれ、変換され、書き込まれた "後に"、Spark クラスターでジョブを実行するために費やされた時間です。 この時間には、接続プールの終了、ドライバーのシャットダウン、ファイルの削除、ファイルの結合などが含まれます。フローで "ファイルの移動" や "1 つのファイルへの出力" などの操作を実行すると、後処理時間の値が増加することがあります。
- ステージ書き込み期間: Synapse SQL のステージング場所にデータを書き込む時間
- テーブル操作 SQL 期間: 一時テーブルからターゲット テーブルへのデータ移動にかかった時間
- 事前 SQL 期間と事後 SQL 期間: 事前および事後のSQL コマンドの実行にかかった時間
- 事前コマンド期間と事後コマンド期間: ファイル ベースのソースまたはシンクに対するすべての事前および事後の操作の実行にかかった時間。 たとえば、処理後にファイルを移動または削除します。
- マージ期間: ファイルのマージにかかった時間。1 つのファイルに書き込むとき、または "列データとしてのファイル名" が使用されるときに、ファイル ベースのシンクにファイルのマージが使用されます。 このメトリックでかなりの時間がかかる場合は、これらのオプションを使用しないようにしてください。
- ステージ時間: ステージとして操作を完了するための Spark 内部での合計所要時間。
- 一時的なステージング テーブル: データ フローがデータベース内のデータをステージングする場合に使用する一時テーブルの名前。
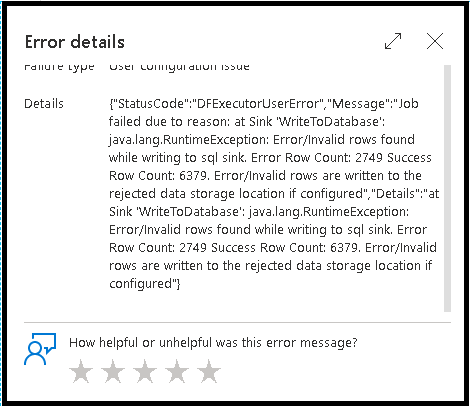
エラー行数
データ フロー シンクでエラー行の処理を有効にすると、監視出力に反映されます。 シンクを [エラー発生時に成功を報告] に設定した場合、シンク監視ノードを選択すると、監視出力に、成功および失敗した行の数が表示されます。
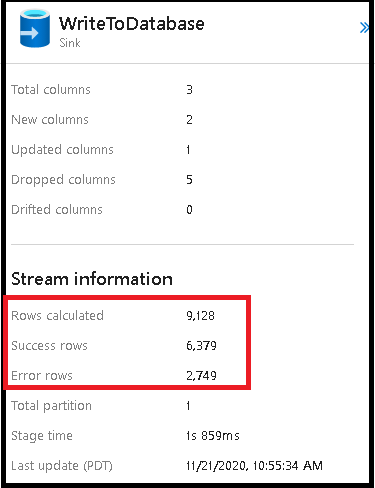
[エラー発生時に失敗を報告] を選択すると、同じ出力がアクティビティ監視出力テキストにのみ表示されます。 これは、データ フロー アクティビティが実行の失敗を返したので、詳細な監視ビューを利用できないためです。
監視アイコン
このアイコンは、変換データが既にクラスターにキャッシュされており、タイミングと実行パスでそのことが考慮されていることを示します。
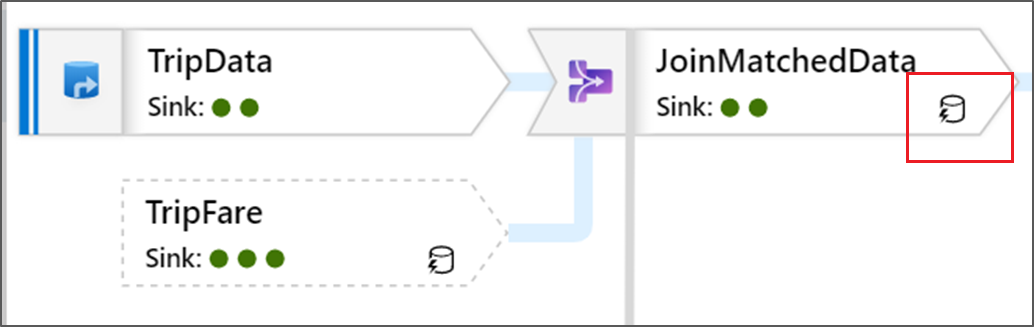
変換内には、緑色の円のアイコンも表示されます。 これは、データ送信先のシンク数のカウントを示しています。