シナリオに合った適切な統合ランタイム構成を選択する
統合ランタイムは、Azure Data Factory によって提供されるデータ統合ソリューションにとってインフラストラクチャの重要な部分です。 これには、ソリューションの設計開始時に既存のネットワーク構造とデータ ソースに適応する方法を十分に検討し、パフォーマンス、セキュリティ、コストを考慮することが必要です。
各種の統合ランタイムの比較
Azure Data Factory には、Azure 統合ランタイム、セルフホステッド統合ランタイム、Azure-SSIS 統合ランタイムという 3 種類の統合ランタイムがあります。 Azure 統合ランタイムでは、マネージド仮想ネットワークを有効にすることもできます。これにより、そのアーキテクチャがグローバル Azure 統合ランタイムとは異なるものになります。
次の表に、すべての統合ランタイムのいくつかの側面にある違いを示します。 実際のニーズに合わせて適切なものを選択できます。 Azure-SSIS 統合ランタイムについては、「Azure-SSIS 統合ランタイムを作成する」の記事を参照してください。
| 特徴量 | Azure 統合ランタイム | マネージド仮想ネットワークを使用する Azure 統合ランタイム | セルフホステッド統合ランタイム |
|---|---|---|---|
| マネージド コンピューティング | Y | Y | N |
| 自動スケール | Y | Y* | × |
| データフロー | Y | Y | N |
| オンプレミスのデータ アクセス | N | Y** | Y |
| Private Link/プライベート エンドポイント | N | Y*** | Y |
| カスタム コンポーネント/ドライバー | N | N | Y |
* Time-to-Live (TTL) が有効になっている場合、統合ランタイムのコンピューティング サイズは構成に従って予約され、自動スケーリングすることはできません。
** オンプレミス環境は、Express Route または VPN 経由で Azure に接続する必要があります。 カスタム コンポーネントとドライバーはサポートされていません。
*** プライベート エンドポイントは、Azure Data Factory サービスによって管理されます。
適切な種類の統合ランタイムを選択することが重要です。 データ統合の既存のアーキテクチャと要件に適している必要があるだけでなく、拡大するビジネス ニーズと将来のワークロードの増加にさらに対応する方法も検討する必要があります。 ただし、すべてに対応できる方法はありません。 次の考慮事項は、決定をナビゲートするのに役立ちます。
統合ランタイムとデータ ストアの場所はどこですか?
統合ランタイムの場所は、そのバックエンドのコンピューティングの場所を定義するほか、データの移動、アクティビティのディスパッチ、データ変換の実行が行われる場所を定義します。 パフォーマンスと伝送効率を向上させるには、統合ランタイムをデータ ソースまたはシンクの近くに配置する必要があります。- Azure 統合ランタイムは、いくつかのルールに基づいて最も適切な場所を自動的に検出します (自動解決とも呼ばれます)。 詳細については、「Azure IR の場所」を参照してください。
- マネージド仮想ネットワークを使用する Azure 統合ランタイムには、お使いのデータ ファクトリと同じリージョンがあります。 Azure 統合ランタイムのように自動解決することはできません。
- セルフホステッド統合ランタイムは、ローカル マシンまたは Azure 仮想マシンのリージョンにあります。
データ ストアはパブリックにアクセス可能ですか?
データ ストアにパブリックにアクセスできる場合、異なる種類の統合ランタイム間の違いは大きくありません。 ストアがファイアウォールの内側にあるか、オンプレミスや仮想ネットワークなどのプライベート ネットワーク内にある場合、マネージド仮想ネットワークを使用する Azure 統合ランタイムまたはセルフホステッド統合ランタイムを選択することをお勧めします。- マネージド仮想ネットワークを使用する Azure 統合ランタイムを使用して、ファイアウォールの内側またはプライベート ネットワーク内にあるデータ ストアにアクセスする場合、Private Link サービスやLoad Balancer など、追加のセットアップが必要です。 プライベート エンドポイントを使用して Data Factory マネージド VNet からオンプレミスの SQL Server にアクセスするに関するチュートリアルを例として参照できます。 データ ストアがオンプレミス環境にある場合は、オンプレミスを Express Route または S2S VPN 経由で Azure に接続する必要があります。
- セルフホステッド統合ランタイムは柔軟性がより高く、追加の設定、Express Route、VPN は必要ありません。 ただし、自分でマシンを提供し、保守する必要があります。
- また、Azure 統合ランタイムのパブリック IP アドレスをファイアウォールの許可リストに追加し、データ ストアへのアクセスを許可することもできますが、セキュリティで高度に保護された運用環境では望ましいソリューションではありません。
データ転送中にどのセキュリティ レベルが必要ですか?
機密性の高いデータを処理する必要がある場合は、たとえば、データ転送中の中間者攻撃から防御する必要があります。 その上で、プライベート エンドポイントと Private Link を使用して、データのセキュリティを確保することを選択できます。- マネージド仮想ネットワークを使用する Azure 統合ランタイムを使用する場合は、データ ストアに対してマネージド プライベート エンドポイントを作成できます。 プライベート エンドポイントは、マネージド仮想ネットワーク内の Azure Data Factory サービスによって保守されます。
- また、仮想ネットワークにプライベート エンドポイントを作成することもできます。セルフホステッド統合ランタイムでは、それらを使用してデータ ストアにアクセスできます。
- Azure 統合ランタイムでは、プライベート エンドポイントと Private Link はサポートされません。
どのレベルのメンテナンスを提供できますか?
インフラストラクチャ、サーバー、機器の保守は、企業の IT 部門にとって重要なタスクの 1 つです。 通常、多くの時間と労力がかかります。- Azure 統合ランタイムやマネージド仮想ネットワークを使用する Azure 統合ランタイムの更新、パッチ、バージョンなどのメンテナンスについて心配する必要はありません。 Azure Data Factory サービスで、すべてのメンテナンス作業が行われます。
- セルフホステッド統合ランタイムは顧客のマシンにインストールされるため、エンド ユーザーがメンテナンスを行う必要があります。 ただし、自動更新を有効にすると、更新があるたびにセルフホステッド統合ランタイムの最新バージョンを自動的に取得できます。 セルフホステッド統合ランタイムの自動更新を有効にし、バージョン コントロールを管理する方法については、セルフホステッド統合ランタイムの自動更新と期限切れ通知に関する記事を参照してください。 また、いくつかの一般的な問題の正常性チェックを行うために、セルフホステッド統合ランタイム用の診断ツールも提供しています。 診断ツールの詳細については、「セルフホステッド統合ランタイム診断ツール」の記事を参照してください。 さらに、Azure Monitor と Azure Log Analytics を明示的に使用して、そのデータを収集し、1 つのウィンドウでセルフホステッド統合ランタイムを監視できるようにすることをお勧めします。 手順については、「ログ分析収集用にセルフホステッド統合ランタイムを構成する」の記事で、この構成の詳細を確認してください。
どのようなコンカレンシー要件がありますか?
大規模データ移行などの大規模なデータを処理する場合、可能な限り効率と処理速度を向上させたいと考えています。 多くの場合、コンカレンシーがデータ統合の主要な要件です。- Azure 統合ランタイムには、すべての種類の統合ランタイムの中で最も高いコンカレンシー サポートがあります。 データ統合単位 (DIU) は、Azure Data Factory で実行する機能の単位です。 必要な数の DIU (例: コピー アクティビティ) を選択できます。 DIU の範囲内で、複数のアクティビティを同時に実行できます。 リージョン グループごとに、上限が異なります。 これらの制限の詳細については、 「Data Factory の制限」の記事を参照してください。
- マネージド仮想ネットワークを使用する Azure 統合ランタイムには、Azure 統合ランタイムと同様のメカニズムがありますが、アーキテクチャ上の制約があるため、サポートできるコンカレンシーは Azure 統合ランタイムよりも低くなります。
- セルフホステッド統合ランタイムが実行できる同時実行アクティビティは、マシンのサイズとクラスターのサイズによって異なります。 より高いコンカレンシーが必要な場合、より大規模なマシンを選択するか、クラスター内でより多くのセルフホステッド統合ノードを使用できます。
特定の機能が必要ですか?
統合ランタイムの種類には、いくつかの機能の違いがあります。- データフローは、Azure 統合ランタイムと、マネージド仮想ネットワークを使用する Azure 統合ランタイムによってサポートされます。 ただし、セルフホステッド統合ランタイムを使用してデータフローを実行することはできません。
- ODBC ドライバー、JVM、SQL Server 証明書などのカスタム コンポーネントをインストールする必要がある場合、セルフホステッド統合ランタイムしか選択できません。 カスタム コンポーネントは、Azure 統合ランタイム、またはマネージド仮想ネットワークを使用する Azure 統合ランタイムではサポートされません。
統合ランタイムのアーキテクチャ
各統合ランタイムの特性に基づいて、データ統合のビジネス ニーズを満たすには、さまざまなアーキテクチャが必要です。 参照として使用できる一般的なアーキテクチャを次に示します。
Azure 統合ランタイム
Azure 統合ランタイムは、Azure または Azure 以外のデータ ソースからデータを移動するために使用できる、フル マネージドの自動スケーリング コンピューティングです。
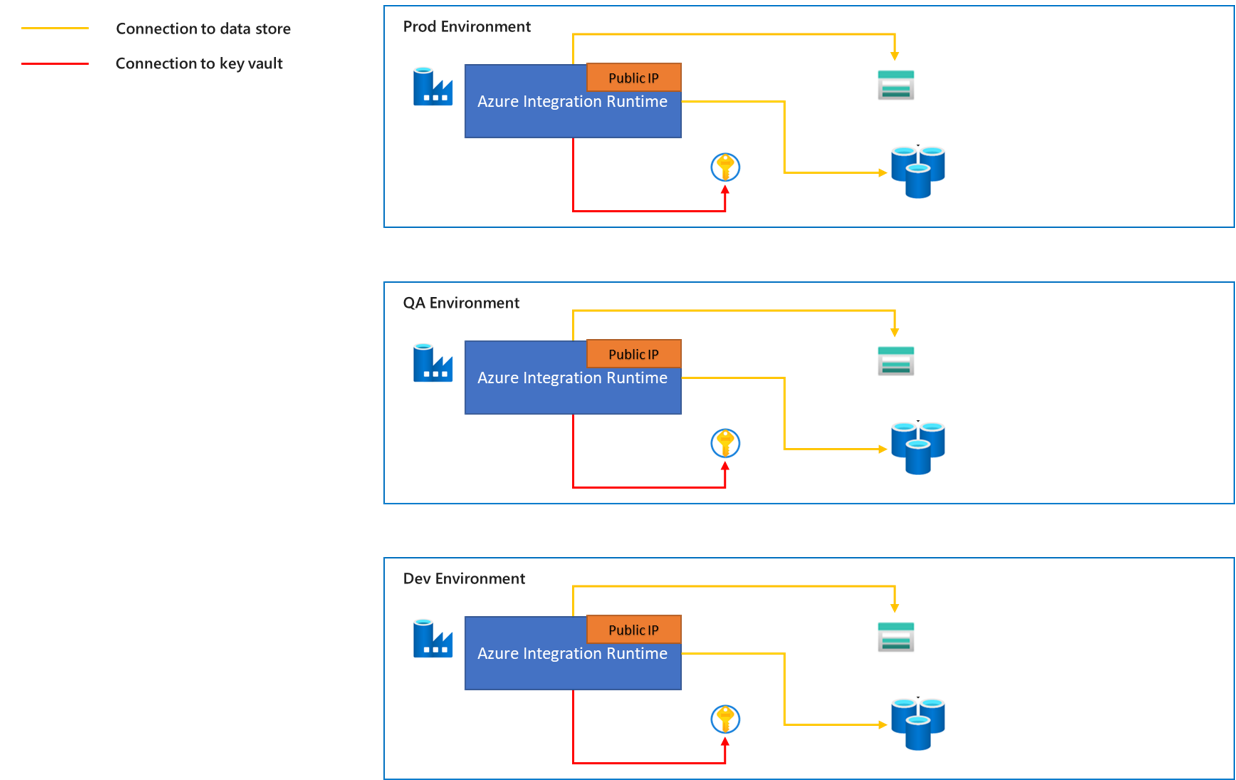
- Azure 統合ランタイムからデータ ストアへのトラフィックは、パブリック ネットワーク経由です。
- Azure 統合ランタイムにはさまざまな静的パブリック IP アドレスが用意されており、これらの IP アドレスはターゲット データ ストアのファイアウォールの許可リストに追加できます。 Azure 統合ランタイムのパブリック IP アドレスを取得する方法の詳細については、「Azure Integration Runtime の IP アドレス」の記事を参照してください。
- Azure 統合ランタイムは、データ ソースとデータ シンクのリージョンに応じて自動解決できます。 または、特定のリージョンを選択することもできます。 データ ソースまたはシンクに最も近いリージョンを選択することをお勧めします。これにより、実行パフォーマンスが向上します。 パフォーマンスに関する考慮事項の詳細については、 「Azure IR でのコピー アクティビティのトラブルシューティング」の記事を参照してください。
マネージド仮想ネットワークを使用する Azure 統合ランタイム
マネージド仮想ネットワークを使用する Azure 統合ランタイムを使用する場合は、マネージド プライベート エンドポイントを使用してデータ ソースを接続し、転送中のデータ セキュリティを確保する必要があります。 Private Link サービスや Load Balancer などの一部の追加設定を使用すると、マネージド プライベート エンドポイントを使用してオンプレミスのデータ ソースにアクセスすることもできます。
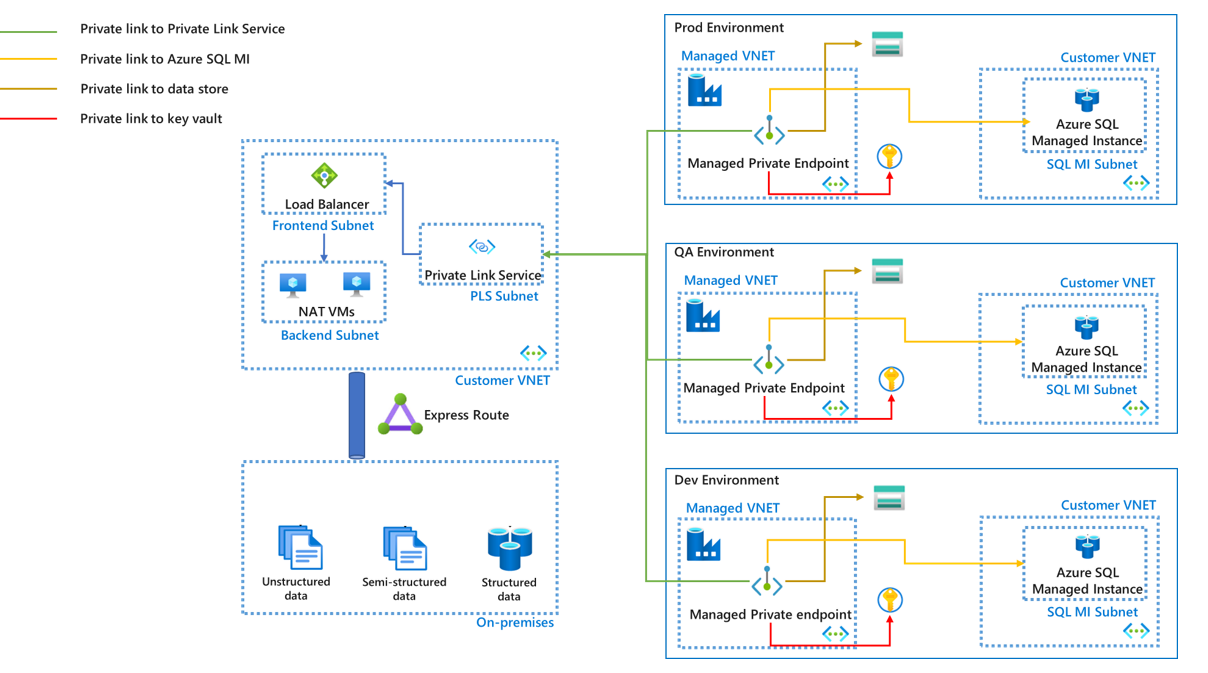
- マネージド プライベート エンドポイントは、異なる環境間で再利用することはできません。 環境ごとに 1 組のマネージド プライベート エンドポイントを作成する必要があります。 マネージド プライベート エンドポイントでサポートされるすべてのデータ ソースについては、「サポートされているデータ ソースとサービス」の記事を参照してください。
- また、Azure Databricks や Azure Functions など、調整する必要がある外部コンピューティング リソースへの接続にマネージド プライベート エンドポイントを使用することもできます。 サポートされる外部コンピューティング リソースの詳細な一覧については、「サポートされているデータ ソースとサービス」の記事を参照してください。
- マネージド仮想ネットワークは、Azure Data Factory サービスによって管理されます。 VNET ピアリングは、マネージド仮想ネットワークと顧客の仮想ネットワークとの間ではサポートされません。
- 顧客は、マネージド仮想ネットワーク上の NSG ルールなどの構成を直接変更することはできません。
- 環境によってマネージド プライベート エンドポイントのプロパティが異なる場合は、そのプロパティをパラメーター化し、デプロイ時にそれぞれの値を指定することでオーバーライドできます。 「CI/CD のベスト プラクティス」の記事で詳細を参照してください。
セルフホステッド統合ランタイム
異なる環境からのデータが相互に干渉するのを防ぎ、運用環境のセキュリティを確保するには、環境ごとに対応するセルフホステッド統合ランタイムを作成する必要があります。 これにより、異なる環境間での十分な分離が確保されます。
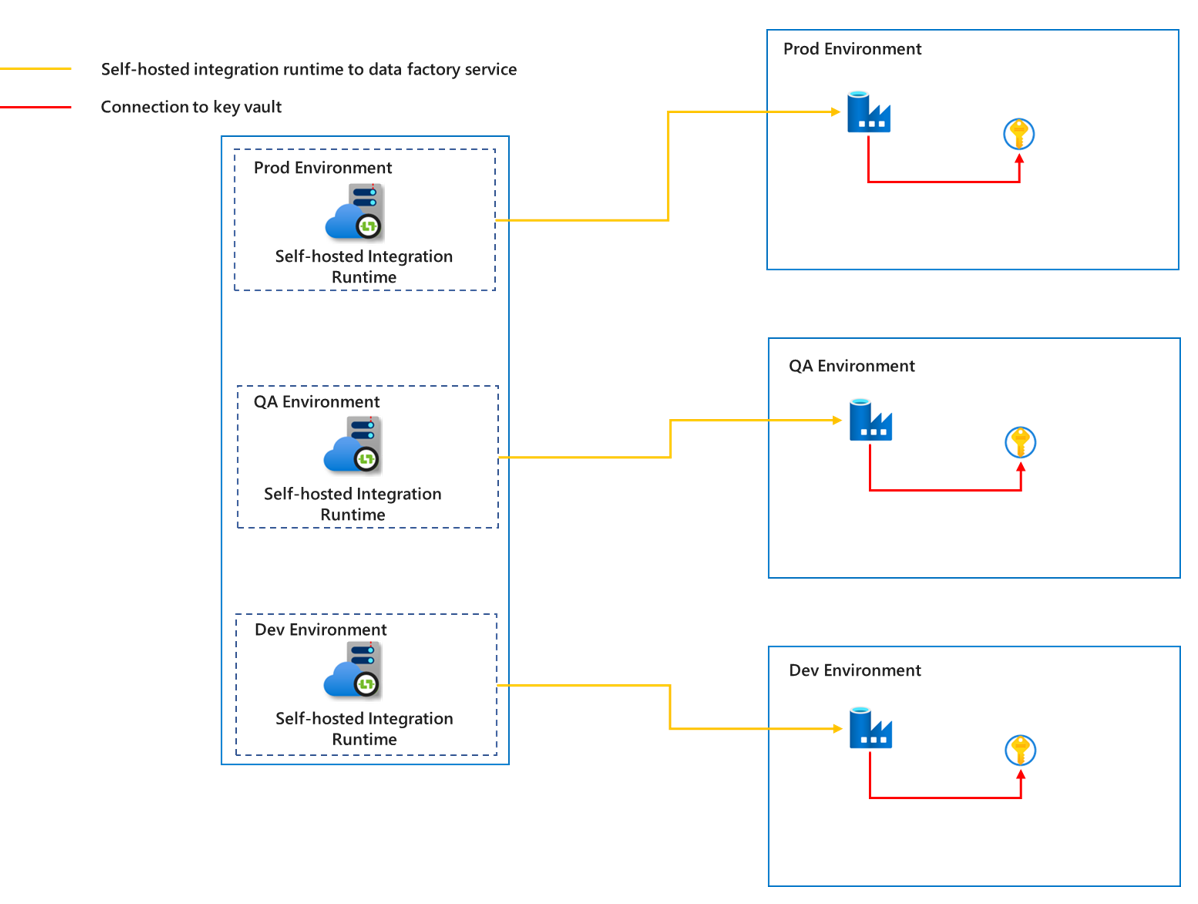
セルフホステッド統合ランタイムはカスタマー マネージド マシンで実行されるため、コスト、メンテナンス、アップグレードの作業を可能な限り削減するために、同じ環境の異なるプロジェクトに対してセルフホステッド統合ランタイムの共有機能を利用できます。 セルフホステッド統合ランタイムの共有の詳細については、「Azure Data Factory で共有のセルフホステッド統合ランタイムを作成する」の記事を参照してください。 同時に、転送中のデータの安全性を高めるために、プライベート リンクを使用してデータ ソースとキー コンテナーを接続し、セルフホステッド統合ランタイムと Azure Data Factory サービス間の通信を接続することもできます。
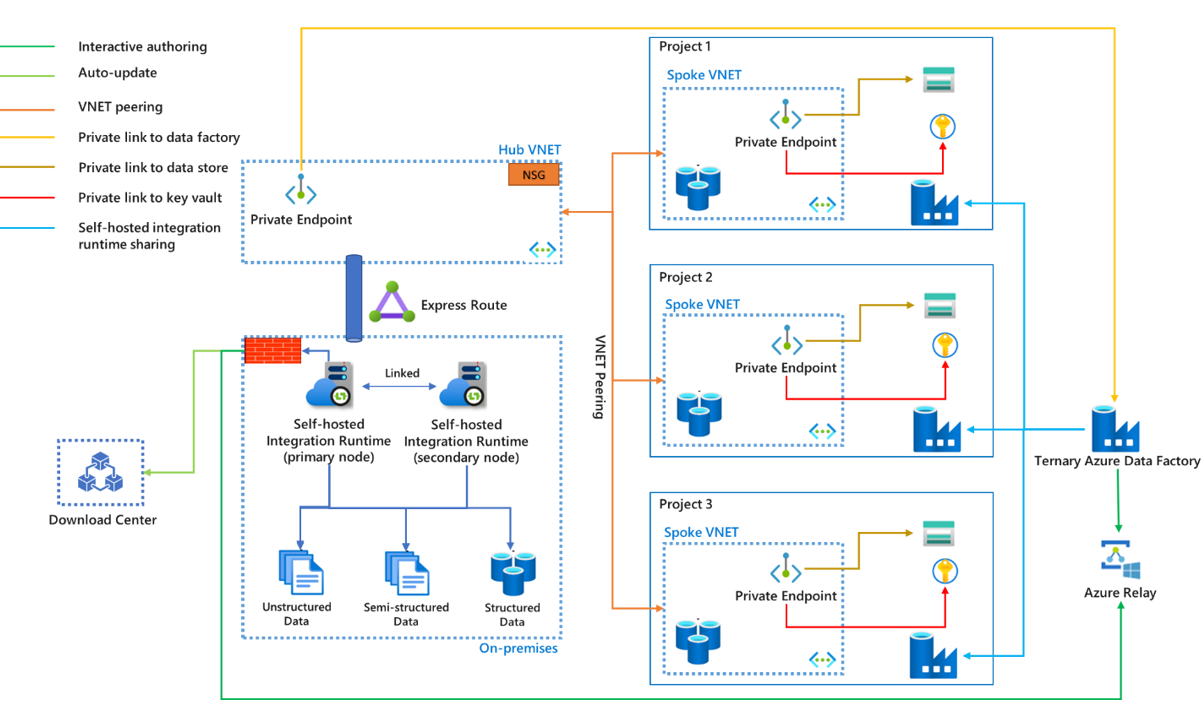
- Express Route は必須ではありません。 Express Route がないと、データは仮想ネットワークやプライベート リンクなどのプライベート ネットワーク経由でシンクに到達するのではなく、パブリック ネットワーク経由で到達します。
- オンプレミス ネットワークが Express Route または VPN 経由で Azure 仮想ネットワークに接続されている場合、セルフホステッド統合ランタイムをハブ VNET 内の仮想マシンにインストールできます。
- ハブスポーク仮想ネットワーク アーキテクチャは、さまざまなプロジェクトだけでなく、さまざまな環境 (運用、QA、開発) にも使用できます。
- セルフホステッド統合ランタイムは、複数のデータ ファクトリで共有できます。 プライマリ データ ファクトリでは、それを共有のセルフホステッド統合ランタイムと呼び、他のデータ ファクトリでは、リンクされたセルフホステッド統合ランタイムと呼びます。 物理的なセルフホステッド統合ランタイムでは、クラスター内に複数のノードを含めることができます。 通信は、プライマリ セルフホステッド統合ランタイムとプライマリ ノードの間でのみ行われ、作業はプライマリ ノードからセカンダリ ノードに配布されます。
- オンプレミス データ ストアの資格情報は、ローカル コンピューターまたは Azure Key Vault のいずれかに格納できます。 Azure Key Vault を強くお勧めします。
- セルフホステッド統合ランタイムとデータ ファクトリ間の通信は、プライベート リンクを経由できます。 ただし、現在、Azure Relay を使用したインタラクティブな作成と、ダウンロード センターからの最新バージョンへの自動更新では、プライベート リンクはサポートされていません。 トラフィックは、オンプレミス環境のファイアウォールを通過します。 詳細については、「Azure Data Factory 用の Azure Private Link」の記事を参照してください。
- プライベート リンクは、プライマリ データ ファクトリにのみ必要です。 すべてのトラフィックはプライマリ データ ファクトリを経由してから、他のデータ ファクトリに進みます。
- CI/CD のすべてのステージで、セルフホステッド統合ランタイムの名前が同じである必要があります。 共有のセルフホステッド統合ランタイムを含めるためだけに三項ファクトリを使用することを検討でき、さまざまな運用ステージではリンクされたセルフホステッド統合ランタイムを使用できます。 詳細については、「継続的インテグレーションと配信」の記事を参照してください。
- オンプレミスのプロキシまたはハブ仮想ネットワークを介して、オンプレミス ネットワークと Express Route の構成を使用して、トラフィックがダウンロード センターと Azure Relay に進む方法を制御できます。 トラフィックがプロキシまたは NSG ルールによって許可されていることを確認してください。
- セルフホステッド統合ランタイム ノード間の通信をセキュリティで保護したい場合、TLS/SSL 証明書を使用してイントラネットからのリモート アクセスを有効にすることができます。 詳細については、「TLS/SSL 証明書を使用してイントラネットからのリモート アクセスを有効にする (詳細)」の記事を参照してください。