Azure Data Explorer を使用して Azure Data Lake でデータのクエリを実行する
Azure Data Lake Storage は、スケーラビリティが高く拡張性と費用対効果に優れた、ビッグ データ分析用のデータ レイク ソリューションです。 ハイパフォーマンス ファイル システムの能力に加えて、非常に高いスケーラビリティと効率性を兼ね備えており、お客様が分析情報を得るまでの時間を短縮するのに役立ちます。 Data Lake Storage Gen2 は Azure BLOB ストレージの機能を拡張するもので、分析ワークロード用に最適化されています。
Azure Data Explorer は、Azure Blob Storage および Azure Data Lake Storage (Gen1 および Gen2) と統合され、外部ストレージに格納されたデータへの高速でキャッシュされたインデックス付きのアクセスを提供します。 データは、Azure Data Explorer に事前に取り込まずに分析およびクエリを実行できます。 また、取り込んだデータと取り込んでいない外部データに対して同時にクエリを実行することもできます。 詳細については、Azure Data Explorer Web UI ウィザードを使用して外部テーブルを作成する方法を参照してください。 概要については、「外部テーブル」を参照してください。
ヒント
最良のクエリ パフォーマンスを得るには、Azure Data Explorer へのデータの取り込みが必要です。 事前に取り込まずに外部データのクエリを実行する機能は、履歴データか、ほとんどクエリが実行されないデータに対してのみ使用してください。 最高の結果を得るために、外部データのクエリのパフォーマンスを最適化してください。
外部テーブルを作成する
たとえば、倉庫に保管されている製品に関する履歴情報が含まれている CSV ファイルが多数あり、過去 1 年間の最も人気のある 5 つの製品を検索するために簡単な分析を実行するとします。 この例では、CSV ファイルは次のようになります。
| タイムスタンプ | 製品 ID | ProductDescription |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3.5in DS/HD Floppy Disk |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
それらのファイルは、Azure BLOB ストレージ mycompanystorage の archivedproducts という名前のコンテナーに、日付ごとに分割されて格納されています。
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
これらの CSV ファイルに対して KQL クエリを直接実行するには、.create external table コマンドを使用して、Azure Data Explorer で外部テーブルを定義します。 外部テーブル作成コマンド オプションの詳細については、外部テーブル コマンドに関する記事を参照してください。
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
外部テーブルが Azure Data Explorer Web UI の左側のペインに表示されるようになりました。
外部テーブルのアクセス許可
- データベース ユーザーは外部テーブルを作成できます。 テーブルの作成者は、自動的にそのテーブルの管理者になります。
- クラスター、データベース、またはテーブルの管理者は、既存のテーブルを編集できます。
- すべてのデータベースのユーザーまたは閲覧者は、外部テーブルのクエリを実行できます。
外部テーブルに対するクエリの実行
外部テーブルを定義すると、external_table() 関数を使用してそれを参照できます。 クエリの残りの部分は、標準的な Kusto クエリ言語です。
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
外部データと取り込んだデータに対するクエリの一括実行
同じクエリ内で、外部テーブルと取り込んだデータ テーブルの両方のクエリを実行できます。 外部テーブルを、Azure Data Explorer、SQL サーバー、またはその他のソースからの他のデータと join または union できます。 let( ) statement を使用して、外部テーブル参照に短縮名を割り当てます。
以下の例で、Products は、取り込んだデータ テーブルで、ArchivedProducts は、前に定義した外部テーブルです。
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
階層データ形式に対するクエリの実行
Azure Data Explorer では、JSON、Parquet、Avro、ORC などの階層形式に対してクエリを実行できます。 階層データ スキーマを外部テーブル スキーマにマップするには (それが異なる場合)、外部テーブル マッピング コマンドを使用します。 たとえば、次の形式の JSON ログ ファイルに対してクエリを実行するとします。
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "e1ef54a6-c6f2-4389-836e-d289b37bcfe0",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "9b49d0d7-b3e6-4467-bb35-fa420a25d324",
"method": "GetFileList"
}
}
...
外部テーブルの定義は次のようになります。
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
データ フィールドを外部テーブル定義フィールドにマップする JSON マッピングを定義します。
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
外部テーブルに対してクエリを実行すると、マッピングが呼び出され、関連するデータが外部テーブルの列にマップされます。
external_table('ApiCalls') | take 10
マッピング構文の詳細については、「データのマッピング」を参照してください。
ヘルプ クラスターで TaxiRides 外部テーブルのクエリを実行する
"ヘルプ" と呼ばれるテスト クラスターを使用して、さまざまな Azure Data Explorer 機能を試してください。 "ヘルプ" クラスターには、何十億ものタクシーの乗車情報を含むニューヨーク市のタクシー データセットの外部テーブル定義が格納されています。
外部テーブル TaxiRides を作成する
このセクションでは、"ヘルプ" クラスターに TaxiRides 外部テーブルを作成するために使用されるクエリを示します。 このテーブルは既に作成済みのため、このセクションをスキップして、「TaxiRides 外部テーブル データのクエリを実行する」に直接進むことができます。
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
作成された TaxiRides テーブルは、Azure Data Explorer Web UI の左側のペインで確認できます。
TaxiRides 外部テーブル データのクエリを実行する
https://dataexplorer.azure.com/clusters/help/databases/Samples にサインインします。
パーティション分割を行わずに TaxiRides 外部テーブルのクエリを実行する
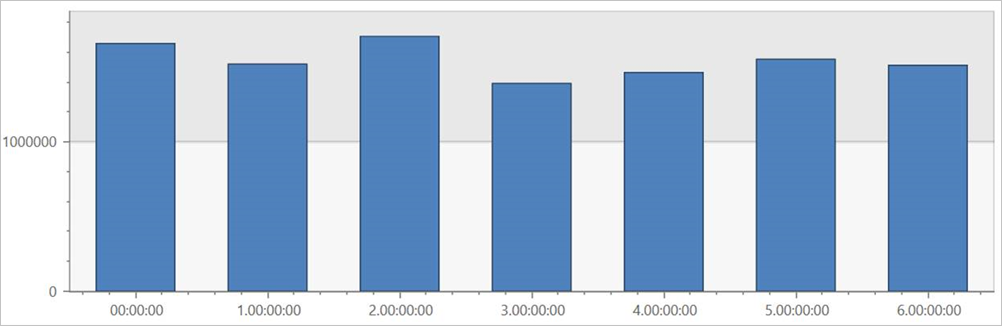
このクエリを 外部テーブル TaxiRides で実行して、データセット全体の曜日ごとの乗車を表示します。
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
このクエリにより、一週間で最も忙しい曜日が示されます。 データがパーティション分割されていないため、このクエリでは、結果が返されるまでに数分かかる場合があります。
パーティション分割を行って TaxiRides 外部テーブルのクエリを実行する
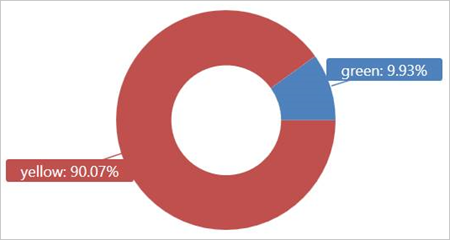
外部テーブル TaxiRides に対してこのクエリを実行すると、2017 年 1 月に使用されたタクシーの種類 (イエローまたはグリーン) が示されます。
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
このクエリではパーティション分割を使用しています。それにより、クエリの時間とパフォーマンスが最適化されます。 クエリではパーティション分割された列 (pickup_datetime) でフィルター処理が実行されて、数秒で結果が返されます。
外部テーブル TaxiRides で実行する他のクエリを記述することで、このデータについてさらに詳しく知ることができます。
クエリ パフォーマンスを最適化する
外部データに対するクエリの実行に関する次のベスト プラクティスに従って、レイクでのクエリのパフォーマンスを最適化します。
データ形式
- 分析クエリには、次の理由から列形式を使用します。
- クエリに関連する列のみを読み取ることができるためです。
- 列エンコード手法を使用すると、データのサイズを大幅に削減できるためです。
- Azure Data Explorer は、Parquet および ORC の列形式をサポートしています。 実装が最適化されているため、Parquet 形式が推奨されます。
Azure リージョン
外部データが Azure Data Explorer クラスターと同じ Azure リージョンにあることを確認してください。 この設定により、コストとデータのフェッチ時間が削減されます。
ファイル サイズ
最適なファイル サイズは、ファイルあたり数百 MB (最大 1 GB) です。 低速のファイル列挙プロセスや列形式の使用の制限などの、不要なオーバーヘッドを要求する大量の小さなファイルは避けてください。 ファイルの数は、Azure Data Explorer クラスター内の CPU コアの数より多くする必要があります。
Compression
圧縮を使用して、リモート ストレージからフェッチされるデータの量を減らします。 Parquet 形式の場合は、列グループを個別に圧縮する内部 Parquet 圧縮メカニズムを使用してください。これにより、それらを個別に読み取ることができます。 圧縮メカニズムの使用を検証するには、ファイル名が "<filename>.parquet.gz" ではなく、"<filename>.gz.parquet" または "<filename>.snappy.parquet" であることを確認します。
パーティション分割
"フォルダー" パーティションを使用してデータを整理し、クエリで無関係なパスをスキップできるようにします。 パーティション分割を計画するときは、クエリ内でタイムスタンプやテナント ID などの、ファイル サイズおよび一般的なフィルターを検討してください。
VM サイズ
よりコア数が多く、ネットワーク スループットが高い VM SKU を選択します (メモリはあまり重要ではありません)。 詳細については、「Azure Data Explorer クラスターに適した VM SKU を選択する」を参照してください。