Azure Data Factory テンプレートを使用してデータベースから Azure Data Explorer に一括コピーする
Azure Data Explorer は、フル マネージドの高速データ分析サービスです。 アプリケーション、Web サイト、IoT デバイスなど、さまざまなソースからストリーム配信される大量のデータをリアルタイムに分析することができます。
Oracle サーバー、Netezza、Teradata、または SQL Server 内のデータベースから Azure Data Explorer にデータをコピーするには、複数のテーブルから膨大な量のデータを読み込む必要があります。 通常は、複数のスレッドを並列して使用して単一のテーブルから行が読み込まれるように、各テーブルでデータをパーティション化する必要があります。 この記事では、これらのシナリオで使用するテンプレートについて説明します。
Azure Data Factory テンプレートは、定義済みの Data Factory パイプラインです。 テンプレートを通じて Data Factory をすぐに使い始めることができ、また、データ統合プロジェクトでの開発時間を短縮することができます。
"データベースから Azure Data Explorer への一括コピー" テンプレートは、Lookup アクティビティと ForEach アクティビティを使用して作成します。 このテンプレートを使用して、データベースまたはテーブルごとにさまざまなパイプラインを作成し、データのコピーを高速化することができます。
重要
必ず、コピーするデータの量に見合ったツールを使用してください。
- SQL Server や Google BigQuery などのデータベースから Azure Data Explorer に大量のデータをコピーするには、"データベースから Azure Data Explorer への一括コピー" テンプレートを使用します。
- 少量または中程度の量のデータを含む少数のテーブルを Azure Data Explorer にコピーするには、Data Factory のデータのコピー ツールを使用します。
前提条件
- Azure サブスクリプション。 無料の Azure アカウントを作成します。
- Azure Data Explorer クラスターとデータベース。 クラスターとデータベースを作成します。
- データ ファクトリ。 データ ファクトリを作成します。
- データのソース。
ControlTableDataset を作成する
ControlTableDataset は、パイプラインでソースからターゲットにコピーされるデータを示します。 行数は、データのコピーに必要なパイプラインの合計数を示します。 ControlTableDataset は、ソース データベースの一部として定義する必要があります。
SQL Server ソースのテーブル形式の例を次のコードに示します。
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
各コード要素について次の表で説明します。
| プロパティ | 説明 | 例 |
|---|---|---|
| PartitionId | コピー順序 | 1 |
| SourceQuery | パイプライン ランタイム中にコピーされるデータを示すクエリ | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | ターゲット テーブル名 | MyAdxTable |
ControlTableDataset の形式が異なる場合は、ご自分の形式に対応する ControlTableDataset を作成します。
データベースから Azure Data Explorer への一括コピー テンプレートを使用する
[Let's get started]\(始めましょう\) ウィンドウで [Create pipeline from template]\(テンプレートからパイプラインを作成\) を選択して [テンプレート ギャラリー] ウィンドウを開きます。
![Azure Data Factory の [Let's get started]\(始めましょう\) ウィンドウ](media/data-factory-template/adf-get-started.png)
[データベースから Azure Data Explorer への一括コピー] テンプレートを選択します。
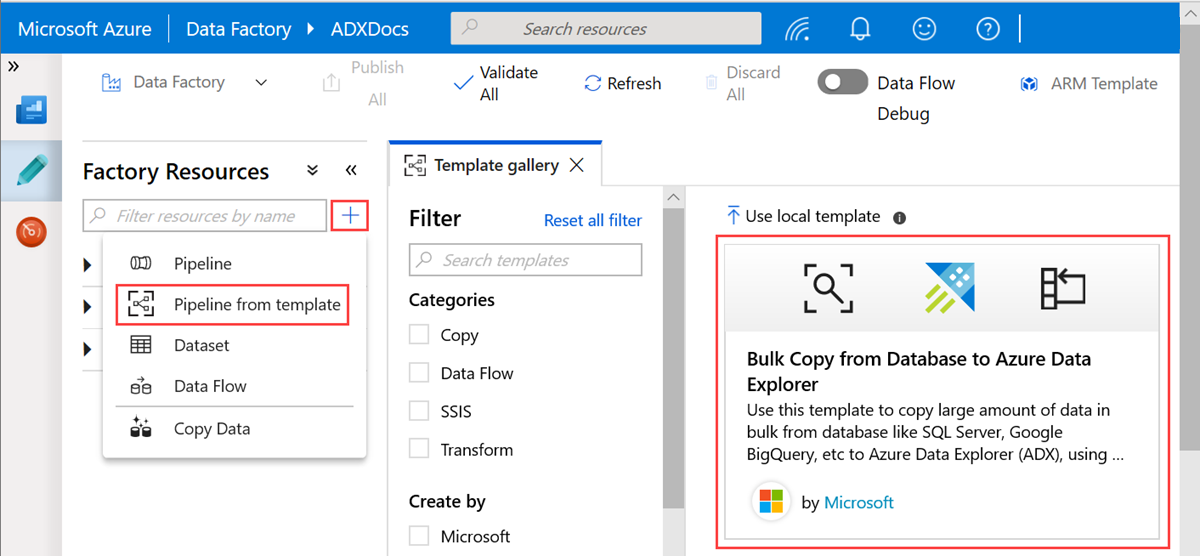
[データベースから Azure Data Explorer への一括コピー] ウィンドウの [ユーザーによる入力] で、次の手順に従ってデータセットを指定します。
a. ソースからターゲットにコピーされるデータと、ターゲット内のコピー先とを示す制御テーブルへのリンクされたサービスを [ControlTableDataset] ボックスの一覧から選択します。
b. [SourceDataset] ボックスの一覧から、ソース データベースへのリンクされたサービスを選択します。
c. [AzureDataExplorerTable] ボックスの一覧から Azure Data Explorer テーブルを選択します。 データセットが存在しない場合は、Azure Data Explorer のリンクされたサービスを作成して、データセットを追加します。
d. このテンプレートを使用する を選択します。
![[データベースから Azure Data Explorer への一括コピー] ウィンドウ](media/data-factory-template/configure-bulk-copy-adx-template.png)
アクティビティの外側のキャンバス内の領域を選択して、テンプレート パイプラインにアクセスします。 [パラメーター] タブを選択して、[名前] (制御テーブル名) と [既定値] (列名) を含むテーブルのパラメーターを入力します。
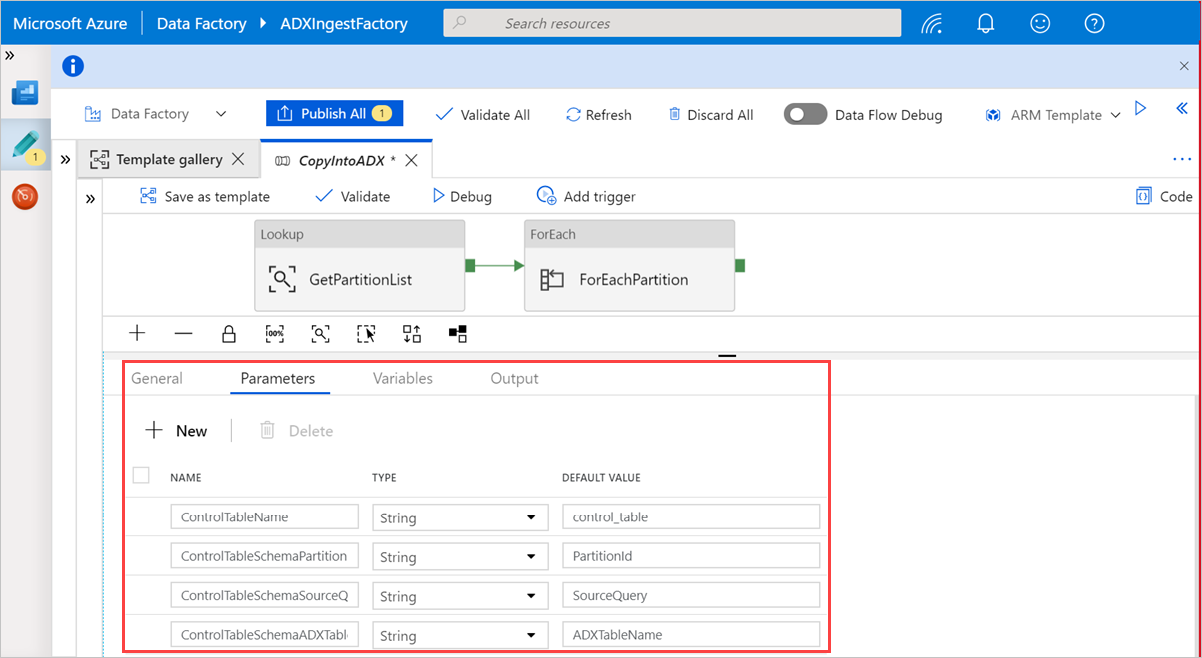
Lookup アクティビティの GetPartitionList を選択して、既定の設定を表示します。 クエリが自動的に作成されます。
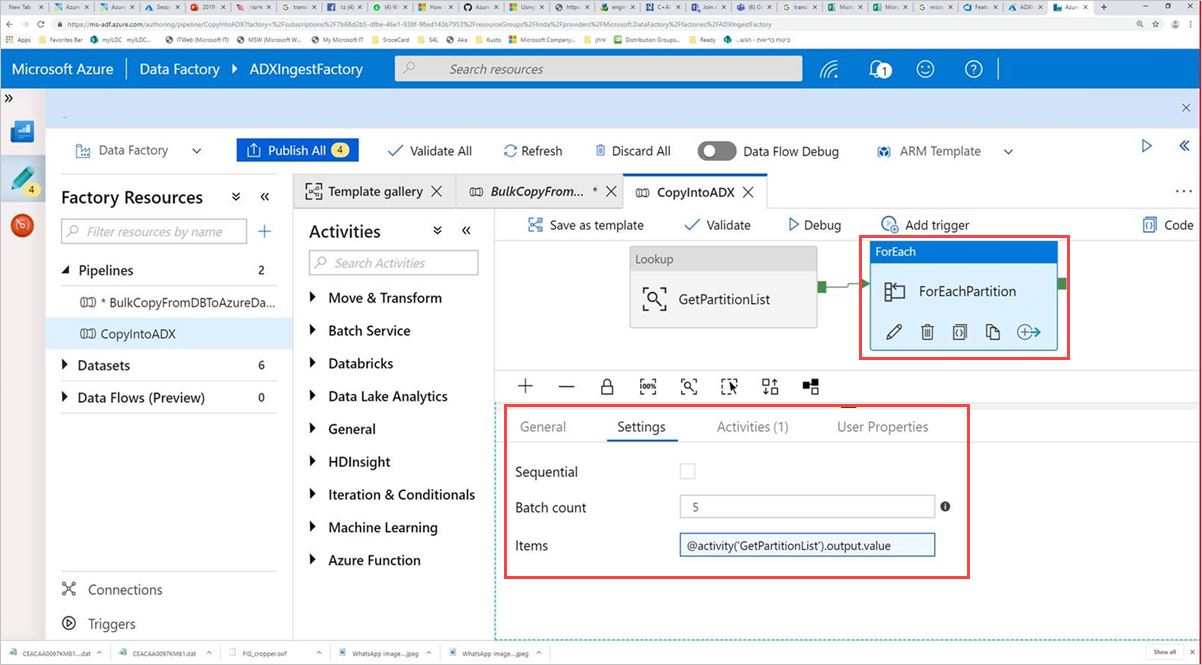
Command アクティビティ ForEachPartition を選択し、[設定] タブを選択して、次の手順を実行します。
a. [Batch count]\(バッチ カウント\) ボックスに 1 から 50 の数値を入力します。 この選択により、ControlTableDataset の行数に達するまで、並列で実行されるパイプラインの数が決まります。
b. パイプライン バッチを確実に並列実行するため、[シーケンシャル] チェック ボックスをオンにすることは避けてください。
ヒント
ベスト プラクティスは、データをより迅速にコピーできるように、多くのパイプラインを並列に実行することです。 効率を高めるためには、ソース テーブルのデータをパーティション分割し、日付とテーブルに従ってパイプラインごとに 1 つのパーティションを割り当てます。
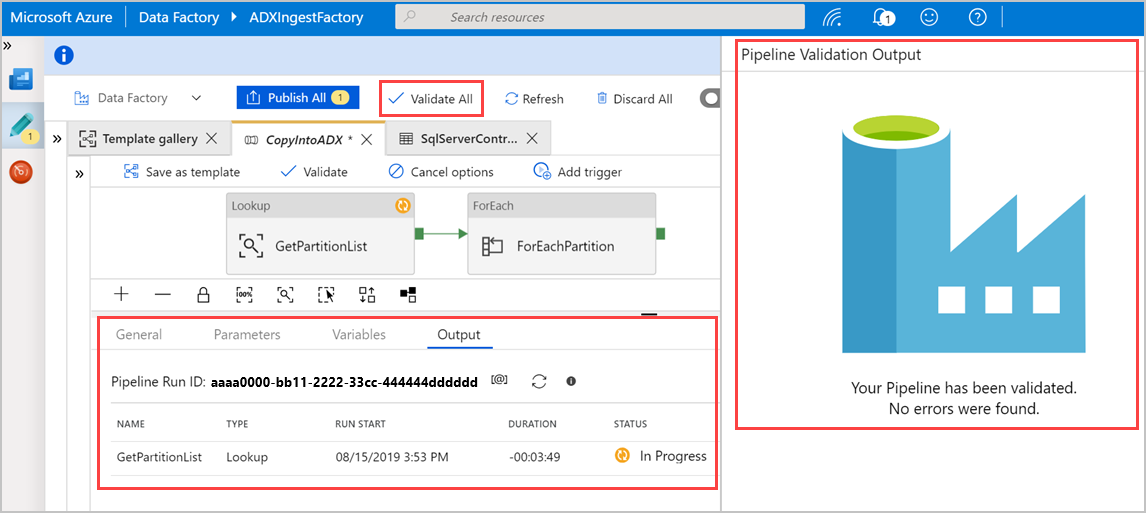
[すべて検証] を選択して Azure Data Factory パイプラインを検証し、[Pipeline Validation Output]\(パイプラインの検証の出力\) ウィンドウで結果を確認します。
必要に応じて [デバッグ]、[トリガーの追加] の順に選択してパイプラインを実行します。
![[デバッグ] ボタンと [Run pipeline]\(パイプラインの実行\) ボタン](media/data-factory-template/trigger-run-of-pipeline.png)
テンプレートを使用して、データベースとテーブルから大量のデータを効率的にコピーできるようになりました。
関連するコンテンツ
- Azure Data Factory の Azure Data Explorer コネクタについて学習する。
- Data Factory UI でリンクされたサービス、データセット、およびパイプラインを編集する。
- Azure Data Explorer の Web UI でデータのクエリを実行する。