Azure Cosmos DB Sync Java SDK v2 のパフォーマンスに関するヒント
適用対象: ![]() NoSQL
NoSQL
重要
これは Azure Cosmos DB 用の最新の Java SDK では "ありません"。 プロジェクトを Azure Cosmos DB Java SDK v4 にアップグレードしてから、Azure Cosmos DB Java SDK v4 のパフォーマンス ヒント ガイドをお読みください。 Azure Cosmos DB Java SDK v4 への移行に関するガイド、およびリアクターと RxJava に関するガイドの手順に従ってアップグレードします。
これらのパフォーマンスに関するヒントは、Azure Cosmos DB Sync Java SDK v2 専用です。 詳細については、Maven リポジトリを参照してください。
重要
2024 年 2 月 29 日に、Azure Cosmos DB Sync Java SDK v2.x は廃止されます。この SDK と、SDK を使用しているすべてのアプリケーションは、引き続き機能します。Azure Cosmos DB は、この SDK の保守とサポートをさらに提供することを停止します。 上記の手順に従って Azure Cosmos DB Java SDK v4 に移行することをお勧めします。
Azure Cosmos DB は、高速で柔軟性に優れた分散データベースです。待機時間とスループットが保証されており、シームレスにスケーリングできます。 Azure Cosmos DB でデータベースをスケーリングするために、アーキテクチャを大きく変更したり、複雑なコードを記述したりする必要はありません。 スケールアップとスケールダウンは、API 呼び出しを 1 回行うだけの簡単なものです。 詳細については、コンテナーのスループットをプロビジョニングする方法またはデータベースのスループットをプロビジョニングする方法に関するページを参照してください。 ただし、Azure Cosmos DB にはネットワーク呼び出しによってアクセスするため、Azure Cosmos DB Sync Java SDK v2 を使うと、最高のパフォーマンスを実現するためにクライアント側の最適化を行うことができます。
データベースのパフォーマンスを向上させる場合は、以下のオプションを検討してください。
ネットワーク
接続モード: DirectHttps を使う
クライアントが Azure Cosmos DB に接続する方法は、特に監視対象となるクライアント側の待機時間の観点から、パフォーマンスに重要な影響を及ぼします。 クライアントの ConnectionPolicy を構成するときに利用できる重要な構成設定の 1 つが ConnectionMode です。 次の 2 つの ConnectionMode を使うことができます。
-
Gateway モードは構成済みの既定のモードであり、すべての SDK プラットフォームでサポートされています。 Gateway モードでは標準の HTTPS ポートと単一のエンドポイントを使用するため、ファイアウォールの厳しい制限がある企業ネットワーク内でアプリケーションを実行する場合は、Gateway が最適な選択肢です。 ただし、パフォーマンスのトレードオフとして、Gateway モードでは、Azure Cosmos DB に対してデータの読み取りまたは書き込みを行うたびに、追加のネットワーク ホップが必要になります。 そのため、ネットワーク ホップ数が少ない DirectHttps モードの方がパフォーマンスが向上します。
Azure Cosmos DB Sync Java SDK v2 では、トランスポート プロトコルとして HTTPS を使用します。 HTTPS では、初期の認証とトラフィックの暗号化に TLS を使用します。 Azure Cosmos DB Sync Java SDK v2 を使うときに開く必要があるのは、HTTPS ポート 443 だけです。
ConnectionMode は、ConnectionPolicy パラメーターを使って DocumentClient インスタンスの作成時に構成されます。
Sync Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);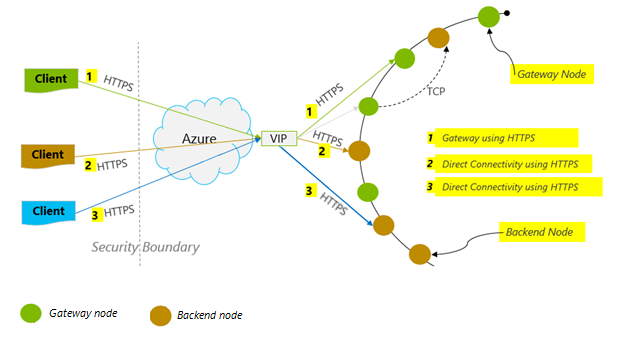
パフォーマンスを確保するために同じ Azure リージョン内にクライアントを併置する
可能であれば、Azure Cosmos DB を呼び出すアプリケーションを Azure Cosmos DB データベースと同じリージョンに配置します。 おおよその比較では、Azure Cosmos DB の呼び出しは、同じリージョン内であれば 1 から 2 ミリ秒以内で完了するのに対し、米国西部と米国東部の間では待ち時間が 50 ミリ秒より長くなります。 要求がクライアントから Azure データセンターの境界まで流れるときに使用されるルートに応じて、この待機時間が要求ごとに異なる可能性があります。 最短の待機時間は、プロビジョニングされた Azure Cosmos DB エンドポイントと同じ Azure リージョン内に呼び出し元アプリケーションを配置することによって実現されます。 使用可能なリージョンの一覧については、「 Azure のリージョン」を参照してください。
SDK の使用例
最新の SDK をインストールする
Azure Cosmos DB SDK は、最適なパフォーマンスを提供するために頻繁に改善されています。 最新の SDK の改善点を確認するには、Azure Cosmos DB SDK を参照してください。
アプリケーションの有効期間中はシングルトン Azure Cosmos DB クライアントを使用する
各 DocumentClient インスタンスはスレッド セーフであり、直接モードで動作しているときには効率的な接続管理とアドレスのキャッシュが実行されます。 DocumentClient による効率的な接続管理とパフォーマンスの向上を実現するために、アプリケーションの有効期間中は、AppDomain ごとに DocumentClient の単一のインスタンスを使用することをお勧めします。
Gateway モードを使うときはホストごとに MaxPoolSize を増やす
Gateway モードを使用するときは Azure Cosmos DB の要求は HTTPS/REST を介して行われ、ホスト名または IP アドレスごとの既定の接続数の制限の対象となります。 場合によっては、Azure Cosmos DB に対する複数の同時接続をクライアント ライブラリが活かすためには、MaxPoolSize を 200 ~ 1000 に増やす必要があります。 Azure Cosmos DB Sync Java SDK v2 での ConnectionPolicy.getMaxPoolSize の既定値は 100 です。 値を変更するには setMaxPoolSize を使います。
パーティション分割コレクションに対する並列クエリを調整する
Azure Cosmos DB Sync Java SDK バージョン 1.9.0 以降は、パーティション分割コレクションに対して並列にクエリを実行するために使用できる並列クエリをサポートします。 詳細については、SDK の操作に関連したコード サンプルを参照してください。 並列クエリは、シリアル クエリよりもクエリの待機時間とスループットを向上させるように設計されています。
(a) setMaxDegreeOfParallelism の調整: 並列クエリは、複数のパーティションに並列にクエリを実行することによって機能します。 ただし、個々のパーティション分割されたコレクションからのデータは、クエリごとに順番に取得されます。 そのため、setMaxDegreeOfParallelism を使ってパーティションの数を設定すると、その他のすべてのシステムの条件が変わらなければ、クエリのパフォーマンスを最大にできる可能性が最大になります。 パーティションの数が不明な場合は、setMaxDegreeOfParallelism を使って大きな数を設定すると、システムが並列処理の最大限度として最小値 (パーティションの数、ユーザー指定の入力) を選びます。
並列クエリが最も有効に機能するのは、クエリに対するデータがすべてのパーティションに均等に分散している場合であることに注意する必要があります。 パーティション分割されたコレクションが、クエリによって返されるすべてまたは大部分のデータがわずかな数のパーティション (最悪の場合は 1 つのパーティション) に集中するように分割されている場合、クエリのパフォーマンスに関してこれらのパーティションがボトルネックになります。
(b) setMaxBufferedItemCount の調整 並列クエリは、結果の現在のバッチがクライアントによって処理されている間に結果をプリフェッチするように設計されています。 プリフェッチは、クエリの全体的な待ち時間の向上に役立ちます。 setMaxBufferedItemCount では、プリフェッチされる結果の数を制限します。 setMaxBufferedItemCount を、返される結果の予期される数 (またはそれ以上の数) に設定すると、クエリに対するプリフェッチの効果が最大になります。
プリフェッチは MaxDegreeOfParallelism とは無関係に同じように動作し、すべてのパーティションからのデータに対して単一のバッファーが存在します。
GetRetryAfterInMilliseconds の間隔でバックオフを実装する
パフォーマンス テストでは、調整される要求の割合がわずかになるまで負荷を上げる必要があります。 スロットル状態になった場合、クライアント アプリケーション側でバックオフ値を適用し、サーバー側によって指定された再試行間隔のスロットル時間を後退させるようにしてください。 バックオフにより、再試行までの待ち時間を最小限に抑えることができます。 再試行ポリシーのサポートは、Azure Cosmos DB Sync Java SDK のバージョン 1.8.0 以降に含まれます。 詳細については、getRetryAfterInMilliseconds を参照してください。
クライアント ワークロードをスケールアウトする
高スループット レベル (1 秒あたりの要求ユニット数が >50,000) でテストを行っている場合、コンピューターが CPU 使用率またはネットワーク使用率の上限に達したことでクライアント アプリケーションがボトルネックになることがあります。 この状態に達しても、クライアント アプリケーションを複数のサーバーにスケールアウトすることで引き続き同じ Azure Cosmos DB アカウントで対応できます。
名前ベースのアドレス指定を使う
dbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>という形式の SelfLinks (_self) ではなく、dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentIdというリンク形式の名前ベースのアドレス指定を使って、リンクの作成に使われるすべてのリソースの ResourceId を取得しなくて済むようにします。 また、これらのリソースは (場合によっては同じ名前で) 再作成されるので、これらをキャッシュしても役に立たない場合があります。パフォーマンスを向上させるために、クエリ/読み取りフィードのページ サイズを調整する
読み取りフィード機能 (readDocuments など) を使ってドキュメントの一括読み取りを実行するときや、SQL クエリを発行するときに、結果セットが大きすぎる場合、セグメント化された形式で結果が返されます。 既定では、100 項目または 1 MB (先に達した方) のチャンク単位で結果が返されます。
該当するすべての結果を取得するために必要なネットワーク ラウンド トリップの回数を減らすために、x-ms-max-item-count 要求ヘッダーを使って、ページ サイズを最大 1,000 まで増やすことができます。 ごく少数の結果のみを表示する必要がある場合は (ユーザー インターフェイスやアプリケーション API が一度に 10 件しか結果を返さない場合など)、読み取りとクエリに使用されるスループットを減らすために、ページ サイズを 10 に減らすこともできます。
また、setPageSize メソッドを使ってページ サイズを設定することもできます。
インデックス作成ポリシー
インデックス作成から未使用のパスを除外して書き込みを高速化する
Azure Cosmos DB のインデックス作成ポリシーでは、インデックス作成パス (setIncludedPaths および setExcludedPaths) を使って、インデックス作成に含めるか除外するドキュメント パスを指定できます。 インデックス作成コストはインデックス付きの一意のパスの数に直接関係するため、パスのインデックス作成を使用すると、クエリ パターンが事前にわかっているシナリオで書き込みパフォーマンスが向上し、インデックス ストレージを削減できます。 たとえば、次のコードは、ワイルドカード "*" を使用して、ドキュメントのセクション全体 (サブツリー) をインデックス作成から除外する方法を示しています。
Sync Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);詳細については、Azure Cosmos DB インデックス作成ポリシーに関するページをご覧ください。
スループット
測定と調整によって 1 秒あたりの要求ユニットの使用量を削減する
Azure Cosmos DB には、UDF、ストアド プロシージャ、トリガーを使ったリレーショナル クエリや階層クエリなど、さまざまなデータベース操作が用意されています。これらの操作はすべて、データベース コレクション内のドキュメントに対して実行できます。 これらの操作のそれぞれに関連付けられたコストは、操作を完了するために必要な CPU、IO、およびメモリに応じて異なります。 ハードウェア リソースの管理について考える代わりに、各種のデータベース操作を実行しアプリケーション要求を処理するのに必要なリソースに関する単一の測定単位として要求単位 (RU) を考えることができます。
コンテナーごとに設定された要求ユニットの数に基づいて、スループットをプロビジョニングします。 要求単位の消費は、1 秒あたりのレートとして評価されます。 コンテナーのプロビジョニング済み要求ユニット レートを超過したアプリケーションは、レートがそのコンテナーにプロビジョニングされているレベルを下回るまで制限されます。 アプリケーションでより高いスループットが必要になった場合は、追加の要求ユニットをプロビジョニングしてスループットを増やすことができます。
クエリの複雑さは、操作で消費される要求ユニット数に影響します。 述語の数、述語の特性、UDF 数、ソース データ セットのサイズのすべてがクエリ操作のコストに影響します。
操作 (作成、更新、または削除) のオーバーヘッドを測定するには、x-ms-request-charge ヘッダー (あるいは、ResourceResponse<T> または FeedResponse<T> の同等の RequestCharge プロパティ) を調べて、これらの操作で使われる要求ユニット数を測定します。
Sync Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();このヘッダーで返される要求の使用量は、プロビジョニングしたスループットの一部です。 たとえば、2000 RU/秒がプロビジョニングされていて、上記のクエリで 1 KB のドキュメントを 1,000 個返した場合、この操作のコストは 1000 になります。 そのため、後続の要求をレート制限する前に、サーバーは 1 秒以内にこのような要求を 2 つだけ受け付けます。 詳細については、要求ユニットに関する記事および要求ユニット計算ツールのページを参照してください。
レート制限と大きすぎる要求レートに対処する
クライアントがアカウントの予約済みスループットを超えようとしても、サーバーでパフォーマンスの低下が発生することはなく、予約済みのレベルを超えてスループット容量が使用されることもありません。 サーバーはいち早く RequestRateTooLarge (HTTP 状態コード 429) で要求を終了させ、要求を再試行するまでにユーザーが待機しなければならない時間 (ミリ秒) を示す x-ms-retry-after-ms ヘッダーを返します。
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100SDK はすべてこの応答を暗黙的にキャッチし、サーバーが指定した retry-after ヘッダーを優先して要求を再試行します。 アカウントに複数のクライアントが同時アクセスしている状況でなければ、次回の再試行は成功します。
複数のクライアントが要求レートを常に上回った状態で累積的に動作している場合、現在クライアントによって内部的に 9 に設定されている既定の再試行回数では不十分な可能性があります。この場合、クライアントは状態コード 429 を含む DocumentClientException をアプリケーションにスローします。 既定の再試行回数は、ConnectionPolicy インスタンスで setRetryOptions を使って変更できます。 既定では、要求レートを超えて要求が続行されている場合に、30 秒の累積待機時間を過ぎると、状態コード 429 を含む DocumentClientException が返されます。 これは、現在の再試行回数が最大再試行回数 (既定値の 9 またはユーザー定義の値) より少ない場合でも発生します。
自動再試行動作により、ほとんどのアプリケーションの回復性とユーザービリティが向上しますが、パフォーマンス ベンチマークの実行時 (特に待機時間の測定時) に問題が生じることがあります。 実験でサーバー スロットルが発生し、クライアント SDK によって警告なしに再試行が行われると、クライアントが監視する待機時間が急増します。 パフォーマンスの実験中に待機時間が急増するのを回避するには、各操作で返される使用量を測定し、予約済みの要求レートを下回った状態で要求が行われていることを確認します。 詳細については、 要求ユニットに関する記事を参照してください。
スループットを向上させるためにサイズの小さいドキュメントに合わせて設計する
特定の操作の要求の使用量 (要求処理コスト) は、ドキュメントのサイズに直接関係します。 サイズの大きいドキュメントの操作は、サイズの小さいドキュメントの操作よりもコストがかかります。
次のステップ
スケーリングと高パフォーマンスのためのアプリケーションの設計について詳しくは、「Azure Cosmos DB でのパーティション分割とスケーリング」をご覧ください。