クラウド規模の分析をクラウド導入戦略に統合する
Azure のクラウド導入フレームワークの
この記事では、より広範な戦略に影響を与えるクラウド規模の分析シナリオに関する考慮事項について説明します。
クラウド規模の分析を実装する前に、データ戦略の計画を立てることもできます。 1 つのユース ケースで小規模から始めたり、優先順位付けを必要とする大規模なユース ケースセットを作成したりできます。 戦略を立てることは、プロセスを確立し、集中する必要がある柱に関する最初の会話を開始するのに役立ちます。
データ戦略のビジネス成果に優先順位を付ける
データ戦略を成功に収めれば、競争上の優位性が得られます。 データ戦略は、常に目的のビジネス成果に合わせる必要があります。 ほとんどのビジネス成果は、次の 4 つのカテゴリのいずれかに分類できます。
従業員に力を与える: 顧客、デバイス、マシンに関するリアルタイムの知識を従業員に提供します。 この知識は、顧客やビジネスのニーズを迅速に満たすために効率的に共同作業を行うのに役立ちます。
顧客と関わる: ブランドに着想を得た豊富でパーソナライズされたつながりのあるエクスペリエンスを提供します。 データと分析情報の力を活用して、顧客体験のすべてのステップに沿って顧客ロイヤルティを促進します。
運用の最適化: 組織全体の情報フローを増やします。 ビジネス プロセスを同期し、データドリブン アプローチを使用して、すべての対話を価値あるものにします。
製品と開発ライフサイクルを変革する: サービスとオファリングに関するテレメトリ データを収集します。 テレメトリ データを使用して、リリースに優先順位を付けたり、新しい機能を作成したり、有効性と導入を継続的に評価したりできます。
ビジネス成果に優先順位を付けた後、現在のプロジェクトと長期的な戦略的イニシアチブを確認し、それに応じて分類します。 複雑さと影響に基づくマトリックス形式で、ビジネス成果の 4 つのカテゴリを組み合わせることを検討してください。 また、アーキテクチャの柱を追加して、シナリオの詳細を確認することを検討してください。
戦略的価値を引き出す
データ駆動型のカルチャを構築し、一貫した先読み、アジャイル、および情報に基づく方法でビジネスを前進させるには、固有の複雑さと現実があります。 展開フェーズに入る前に、目的のビジネス成果を達成するのに役立つ一貫性のあるデータ戦略の形成に重点を置く必要があります。
クラウド規模の分析は、
- エンタープライズ データ プラットフォームを構築できるスケーラブルな分析フレームワーク
- セルフサービス。データ探索、データ資産の作成、および製品開発においてユーザーを支援します
- 再利用可能なデータ資産、データ コミュニティ、セキュリティで保護されたサード パーティの交換、インプレース共有を備えたデータ主導のカルチャ
- ポリシー、共通 ID、機密性、暗号化を使用して、自信を持ってデータを共有する
- カスタマー エクスペリエンスとエンゲージメントの向上
- 製品またはサービスの変革
- 新しい製品やサービスによる市場の中断
次の図には、独自の戦略でこれらの動機を実現するのに役立つ主要なテーマが含まれています。 これらのテーマと、それらが一貫性のあるデータ戦略にどのように貢献しているかを慎重に分析します。 また、データの戦略的価値を引き出し、一貫したビジネスの成長を可能にする方法を検討します。
「データ戦略は、データを資産として使用し、ビジネスを前進させる基盤です。 これは、データの問題に対するパッチ ジョブではありません。 これは、データの課題を解決するために配置する人、プロセス、テクノロジを定義する長期的なガイド計画です。"
戦略の作成は 1 つのステップです。 エンタープライズ規模で戦略を実行することは、組織の既存の文化、人、プロセス、テクノロジの選択に大きな課題を伴います。 実行にはコミットメントと、組織のすべてのレベルでの明確な所有権が必要です。
効率の向上
クラウドの機敏性により、組織は迅速に適応し、ビジネスのあらゆる領域に効率をもたらす必要があります。 Gartnerの新たなリスクに関する
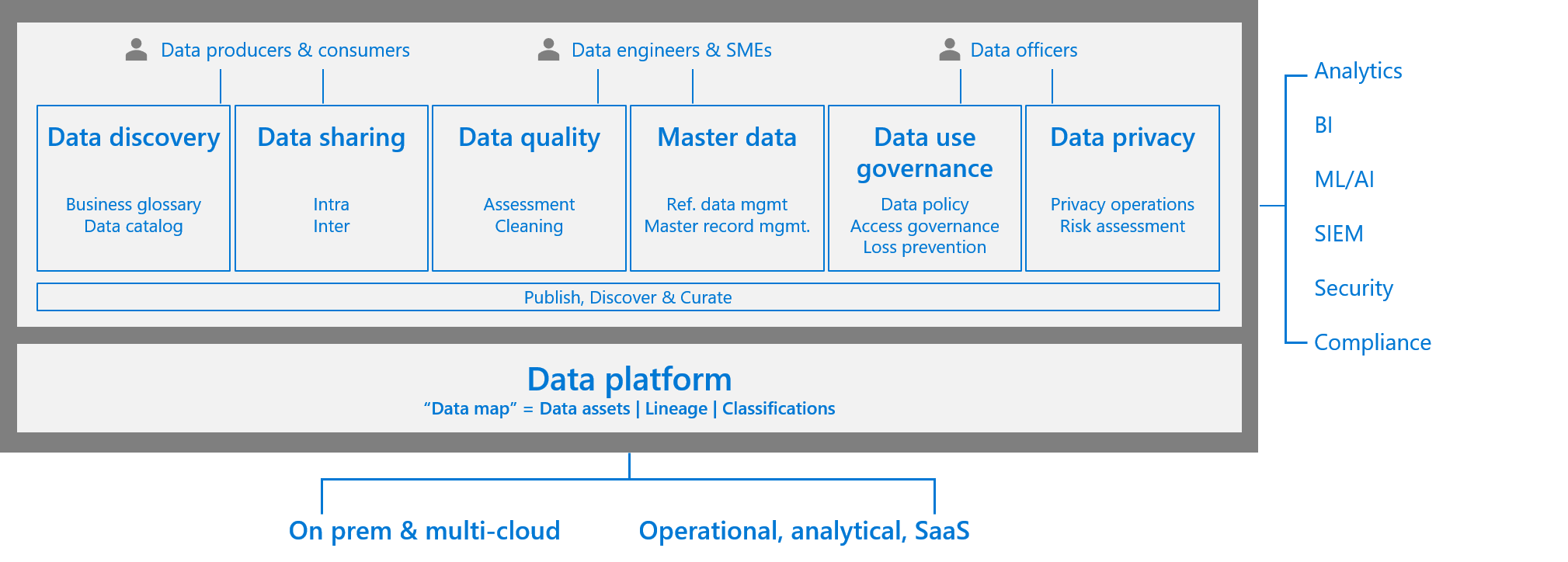
データ管理の運用化
多くの組織では、機敏性を実現するために中央 IT を徐々に分散化しています。 組織は迅速にイノベーションを行いたいと考えており、セルフサービス方式でエンタープライズ全体の統合データにアクセスすることで、困難なビジネス要件を満たすのに役立ちます。
企業がデータの可能性を最大限に活用できないのには、多くの理由があります。 これは、各チームがデータ分析に異なるツールと標準を使用しているサイロでビジネス機能が機能するためである可能性があります。 または、主要業績評価指標を全体的なビジネス目標にリンクできない可能性があります。
データの民主化は、ビジネスに価値を還元し、困難なビジネス成長目標を達成するのに役立ちます。
- LOB のニーズを理解し、優先順位を付けます。
- ドメイン間でデータを分散して所有権を有効にし、データをユーザーに近づけます。
- セルフサービス データ製品をデプロイして、分析情報とビジネス価値を高めます。
データ ガバナンスのためには、分散化されたデータ民主化の世界で適切なバランスを取る必要があります。 ガバナンスを厳密に適用しすぎると、イノベーションを妨げることができます。 ただし、少なくともいくつかの主要な原則とプロセスがない場合は、最終的にデータ サイロが発生する可能性があります。 これらのサイロは、組織の評判と潜在的な収益を損なう可能性があります。 包括的なデータ ガバナンス アプローチは、一貫した方法でデータの戦略的価値を引き出すために不可欠です。
十分に考え抜いたデータ戦略が存在しない場合は、単に "進む" だけで、組織に価値を提供し始める必要があります。 前述の主要テーマに基づいて行動するか、フレームワーク内の戦略的原則として使用することで、現在のビジネス上の問題に対処します。 これらの主要なテーマを使用すると、検証を繰り返しながらタイムリーな結果を提供する包括的なデータ戦略を作成するのにも役立ちます。 ビジネスリーダーとテクノロジ リーダーは、データから価値を生み出し、簡素化された構造化された方法で迅速にスケーリングするために必要な戦略と考え方を開発する必要があります。
詳細については、「データ ガバナンスとは」を参照してください。.
データ ドリブン カルチャを開発する
データ戦略を成功させるには、データドリブン カルチャが必要です。 オープンで協調的な参加を一貫して促進する文化を発展させます。 この種の文化では、従業員全員が組織のビジネス成果を学び、コミュニケーションを取り、改善することができます。 データドリブン カルチャを開発することで、各従業員がデータに基づく影響や影響を生み出す能力も向上します。
体験の出発点は、成熟度曲線に沿った組織、業界、現在の場所によって異なります。 次の図は、組織の AI 使用率の成熟度レベルを示す成熟度モデルの例を示しています。

レベル 0
データは、プログラムによって一貫して利用されることはありません。 組織のデータフォーカスは、アプリケーション開発の観点からのものです。
レベル 0 では、組織には計画外の分析プロジェクトが含まれていることがよくあります。 各アプリケーションは、固有のデータと利害関係者のニーズに高度に特化されています。 また、各アプリケーションには重要なコード ベースとエンジニアリング チームがあり、多くは IT の外部で設計されています。 ユース ケースの有効化と分析はサイロ化されます。
レベル 1
レベル 1 では、チームが形成され、戦略が作成されますが、分析は部門化されたままです。 組織は、従来のデータキャプチャと分析に適している傾向があります。 クラウド規模のアプローチに対するある程度のコミットメントがある場合があります。 たとえば、クラウドから既にデータにアクセスしている可能性があります。
レベル 2
組織のイノベーション プラットフォームは、ほぼ準備ができています。 ワークフローは、データ品質に対応するために用意されています。 組織は、いくつかの "理由" の質問に答えることができます。
レベル 2 では、一元管理されたデータ レイク ストアを使用してデータ ストアのスプロールを制御し、データ検出可能性を向上させるエンドツーエンドのデータ戦略を積極的に探しています。 組織は、中央管理されたデータ レイクにコンピューティングを提供するスマート アプリケーションの準備が整いました。 これらのスマート アプリケーションにより、プライバシー リスク、コンピューティング コスト、および重要なデータのフェデレーション コピーの必要性が軽減されます。
このレベルでは、組織は、一般的なデータ コンピューティング タスクにマルチテナントで一元的にホストされる共有データ サービスを使用する準備も整っています。 これらの共有データ サービスを使用すると、データ サイエンス主導のインテリジェンス サービスから迅速な分析情報を得ることができます。
レベル 3
組織は包括的なデータ アプローチを使用します。 データに関連するプロジェクトは、ビジネス成果の中に統合されます。 組織は分析プラットフォームを使用して予測を行います。
レベル 3 では、組織はデータ資産とアプリケーション開発の両方の観点からデジタル イノベーションのロックを解除します。 データ レイクや共有データ サービスなど、基本的なデータ サービスが用意されています。
組織全体の複数のチームが、重要なビジネス ワークロード、主要なビジネス ユース ケース、測定可能な結果を正常に提供します。 新しい共有データ サービスは、テレメトリを使用して識別されます。 IT は、重要なビジネス プロセスの改善に役立つ、信頼されたエンド ツー エンドのデータ戦略を使用して、会社全体のチームに対する信頼できるアドバイザーです。
レベル 4
レベル 4 では、組織全体でフレームワーク、標準、エンタープライズ、データドリブン カルチャが使用されています。 自動化、データドリブン フィードバック ループ、分析または自動化に関する卓越性の中心を実際に観察できます。
ビジネスに合わせた目標を開発する
ビジネス ビジョンに沿った優先順位を特定し、"大きく考え、小さく始め、迅速に行動する" イデオロギーを維持することは、成功の鍵となります。 適切なユース ケースを取り上げるには、長く困難な審査プロセスが必要であるとは限りません。 投資収益率を検証するのに十分なデータがあり、より多くの需要と容易な承認を得られるビジネスユニットでは、継続的な問題となる可能性があります。 状況はすぐに動く可能性があり、ほとんどの組織が作業を始めるのに苦労する可能性があります。
データ属性について
強力なデータ戦略を構築するには、データのしくみを理解する必要があります。 データのコア特性を知ることは、データを処理するための原則的なプラクティスを構築するのに役立ちます。
データは高速に移動しますが、その速度は物理学の法則に逆らうことはできません。 データは、土地およびそれを作成した業界の法律に準拠している必要があります。
データ自体は変更されませんが、そのような課題を軽減するための対策を講じない限り、変更や偶発的な損失が発生しやすくなります。 予期しない変更に対処できるように、コントロール、データベース、ストレージの破損対策を実施します。 また、監視、監査、アラート、ダウンストリーム プロセスも設定してください。
それ自体では、データは分析情報を生成したり、価値を生み出したりすることはありません。 分析情報を取得したり、値を抽出したりするには、データの大部分またはすべてを 4 つの個別の手順で配置する必要があります。
- データの取り込み
- ストレージ
- 加工
- 解析学
これら 4 つの各手順には、独自の原則、プロセス、ツール、テクノロジがあります。
データ資産と関連する分析情報を源泉徴収すると、社会経済的、政治的、研究、投資に関する意思決定に影響を与える可能性があります。 組織が安全で責任ある方法で分析情報を提供できることが重要です。 生成または取得するすべてのデータは、特に明記されていない限り、データ分類演習を実行する必要があります。 暗号化は、保存時と転送中の両方で機密データを処理するためのゴールド スタンダードです。
データ、アプリケーション、サービスはすべて独自の重力プルを持っていますが、データのプルは最大です。 サー・アイサック・ニュートンの伝説のリンゴとは異なり、データは周囲の物体に影響を与える物理的な質量を持っていません。 代わりに待機時間とスループットがあり、分析プロセスのアクセラレータとして機能します。 待ち時間、スループット、アクセスの容易さを考慮すると、望ましくない場合でもデータを複製しなければならないことがよくあります。 このような要件と組織のデータ ポリシーのバランスを取ることができるように、ユーザー、プロセス、ツール、テクノロジを適切に設定します。
アーキテクチャコンストラクトは、データを処理できる速度を制御します。 コンストラクトは、ソフトウェア、ハードウェア、ネットワークのイノベーションによって促進されます。 アーキテクチャ上の考慮事項をいくつか次に示します。
- データ分散の設定
- パーティショニング
- キャッシュ テクノロジ
- バッチ処理とストリーム処理
- バックエンドとクライアント側の処理の分散
データ戦略を定義する
より良い製品と価値の高いサービスを構築するための競争上の利点としてデータを使用することは、新しい概念ではありません。 ただし、クラウド コンピューティングによって有効になるデータの量、速度、および多様性は、かつてないほどです。
クラウド内の最新のデータ分析プラットフォームの設計は、セキュリティ、ガバナンス、監視、オンデマンド スケーリング、データ操作、セルフサービスで構成されています。 これらのファセット間の相互作用を理解することは、優れたデータ戦略と良いものを区別することです。 クラウド導入フレームワークなどのツールを使用して、アーキテクチャの凝集性、整合性、ベスト プラクティスを確保します。
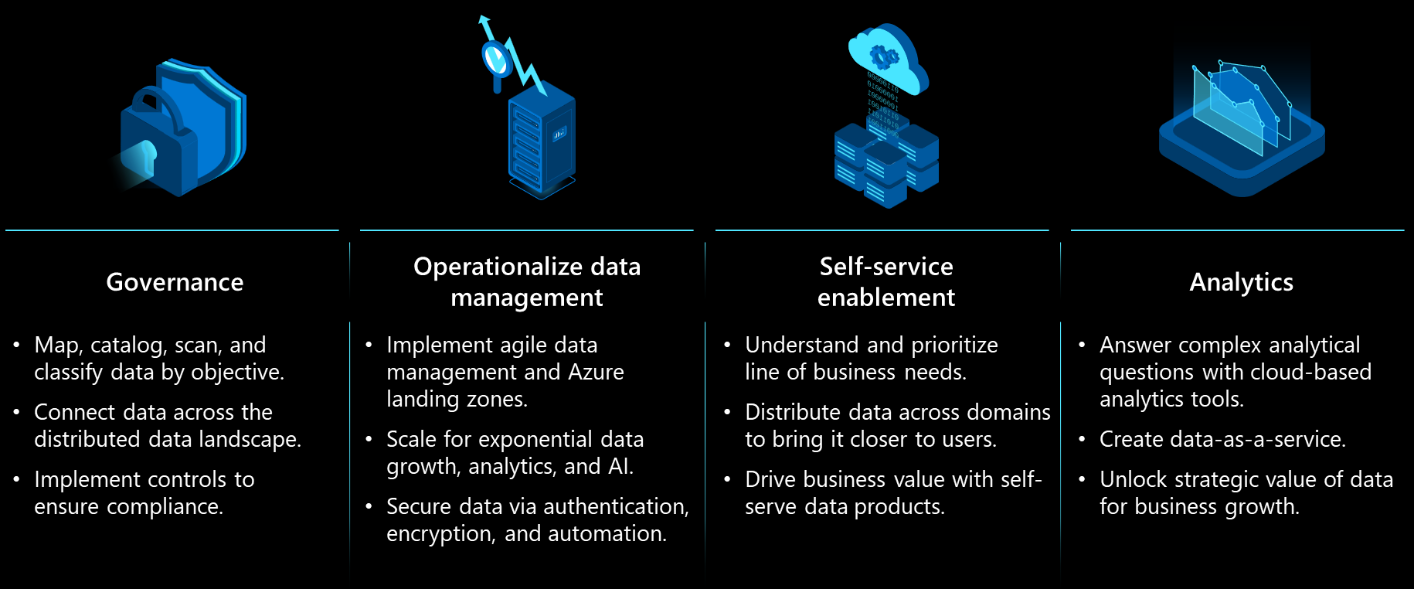
効果的にするには、データ戦略にデータ ガバナンスのプロビジョニングが含まれている必要があります。 次の図は、データ ライフサイクルの主要なステージを示しています。データ ガバナンスに重点を置きます。
次のセクションでは、データ戦略のレイヤーの設計原則を決定する際に使用する必要がある考慮事項について説明します。 データからビジネスの成果と価値を提供することに重点を置く。
データ インジェスト
データ インジェストの主な考慮事項は、要件から運用環境まで、セキュリティで保護された準拠した方法でデータ パイプラインを迅速に構築できることです。 重要な要素には、データ レイクをハイドレートするメタデータ駆動型、セルフサービス型、およびローコードのテクノロジが含まれます。
パイプラインを構築するときは、設計と、データのラングリング、データの分散、コンピューティングのスケーリングの両方を検討してください。 また、パイプラインの継続的インテグレーションと配信に対する適切な DevOps サポートを確保する必要があります。
Azure Data Factory などのツールでは、多数のオンプレミス データ ソース、サービスとしてのソフトウェア (SaaS) データ ソース、およびその他のパブリック クラウドからのその他のデータ ソースがサポートされています。
ストレージ
物理層と論理層の両方でデータにタグを付け、整理します。 データ レイクは、すべての最新のデータ分析アーキテクチャの一部です。 組織は、運用するすべてのデータ分類と業界のコンプライアンス要件を満たす適切なデータ プライバシー、セキュリティ、およびコンプライアンス要件を適用する必要があります。 カタログ化とセルフサービスは、組織レベルのデータ民主化を支援します。これは、適切なアクセス制御によって導かれながら、イノベーションを促進します。
ワークロードに適したストレージを選択します。 ストレージが初めて正確に取得されない場合でも、クラウドを使用すると、迅速にフェールオーバーして体験を再開できます。 アプリケーションの要件を使用して、最適なデータベースを選択します。 分析プラットフォームを選択するときは、バッチ データとストリーミング データを処理する機能を必ず検討してください。
データ処理
データ処理のニーズは、ワークロードごとに異なります。 ほとんどの大規模なデータ処理には、リアルタイム処理とバッチ処理の両方の要素が含まれています。 ほとんどの企業には、時系列処理要件の要素があり、エンタープライズ検索機能用に自由形式のテキストを処理する必要もあります。
オンライン トランザクション処理 (OLTP) は、最も一般的な組織処理要件を提供します。 一部のワークロードでは、"ビッグ コンピューティング" と呼ばれるハイ パフォーマンス コンピューティング (HPC) などの特殊な処理が必要です。これらのワークロードは、多くの CPU または GPU ベースのコンピューターを使用して複雑な数学的タスクを解決します。
特定の特殊なワークロードの場合、お客様は Azure コンフィデンシャル コンピューティングなどの実行環境をセキュリティで保護できます。これにより、パブリック クラウド プラットフォーム内でデータが使用されている間にユーザーがデータをセキュリティで保護できます。 この状態は、効率的な処理に必要です。 データは、エンクレーブとも呼ばれる信頼された実行環境 (TEE) 内で保護されます。 TEE は、外部の表示と変更からコードとデータを保護します。 TEEs を使用すると、さまざまな組織のデータ ソースを使用している間でも、データの機密性を損なうことなく AI モデルをトレーニングできます。
分析処理
抽出、変換、読み込み (ETL) コンストラクトは、オンライン分析処理 (OLAP) とデータ ウェアハウスのニーズに関連します。 ビジネスに合わせたデータ モデルとセマンティック モデルにより、組織はビジネス ルールと主要業績評価指標 (KPI) を実装することが多く、分析プロセスの一部として実装されます。 便利な機能の 1 つは、自動スキーマ ドリフト検出です。
データ戦略の概要
データ ガバナンスや責任ある AI など、他の考慮事項に原則的なアプローチを取ると、後で配当が支払われます。
Microsoft では、公平性、信頼性と安全性、プライバシーとセキュリティ、包括性という 4 つの基本原則に従っています。 透明性と説明責任の 2 つの基本原則は、4 つの主要な原則すべてを支えています。
リソースとガバナンスのシステムを開発することで、原則と責任ある AI を実践します。 一部のガイドラインでは、人間/AI の相互作用、会話型 AI、インクルーシブ デザイン、AI の公平性チェックリスト、データセットのデータ シートに対処しています。
また、イノベーションのあらゆる段階で、他のユーザーが AI を理解、保護、制御できるように、一連のツールも開発しました。 これらのツールは、責任ある AI を強化および加速するための、学際的なコラボレーションの取り組みの結果です。 コラボレーションは、ソフトウェア エンジニアリングと開発、ソーシャル サイエンス、ユーザー研究、法律、ポリシーにまたがっています。
コラボレーションを向上させるために、InterpretML や Fairlearn などの多くのツールをオープンソース化しました。 他のユーザーは、これらのオープンソース ツールに貢献して構築できます。 また、Azure Machine Learning を使用してツールを民主化しました。
データ主導型の組織になるためのピボットは、新しい標準で競争上の優位性を提供するための基礎です。 お客様がアプリケーションのみのアプローチからアプリケーションとデータ主導のアプローチに移行できるように支援したいと考えています。 アプリケーションとデータに重点を置くアプローチは、ビジネス成果に影響を与える現在および将来のユース ケース全体で再現性とスケーラビリティを確保するエンドツーエンドのデータ戦略を作成するのに役立ちます。
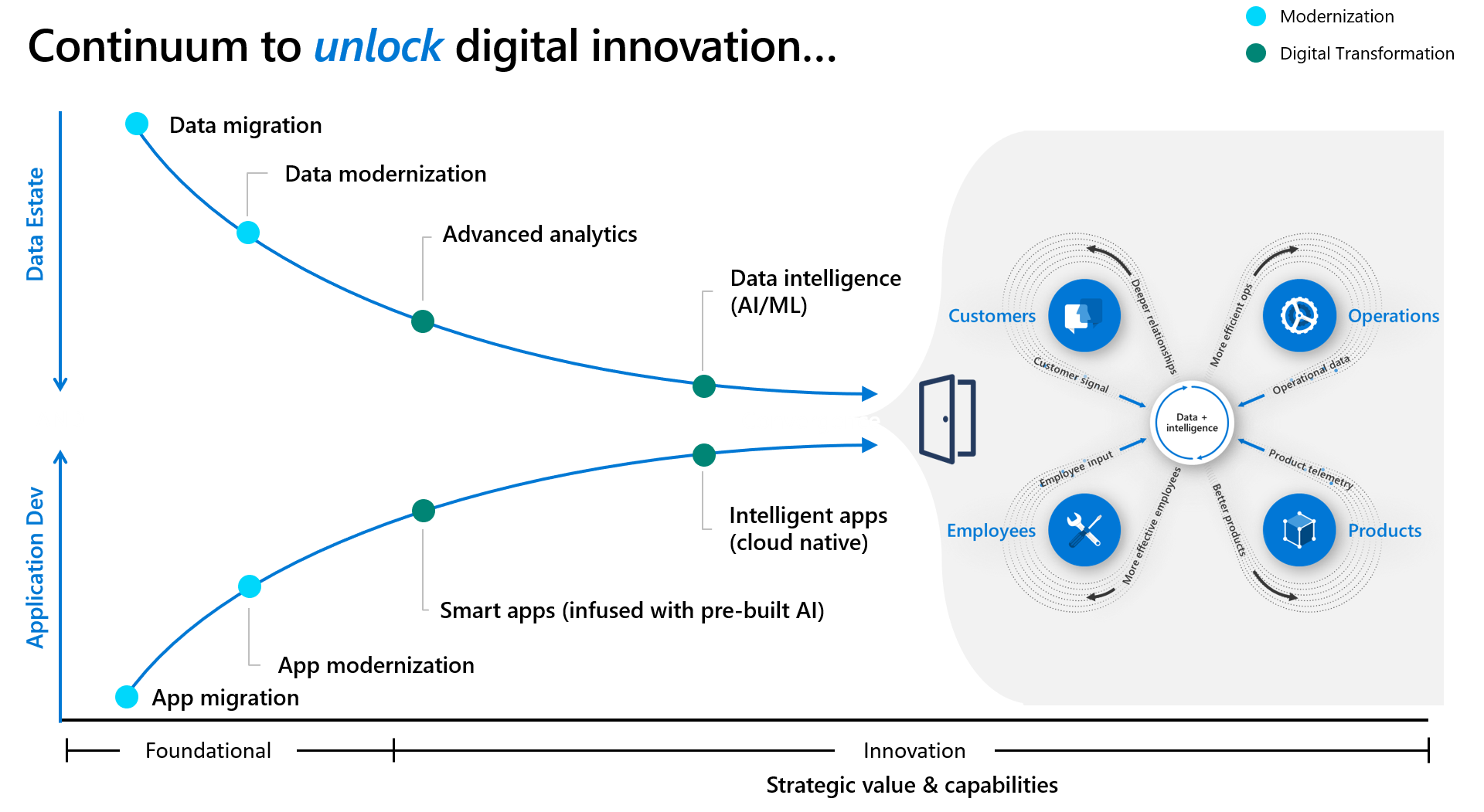
コミットメント、コミュニケーション、エンゲージメントを促進する
データ戦略を成功に導くすべての重要な役割は、採用したアプローチと一般的なビジネス目標を明確に理解する必要があります。 主要な役割には、リーダーシップ チーム (C レベル)、ビジネス ユニット、IT、運用、配信チームが含まれる場合があります。
コミュニケーションは、このフレームワークの最も重要な部分の 1 つです。 組織は、ロール間で効果的なコミュニケーションを行うプロセスを考案する必要があります。 コミュニケーションは、現在のプロジェクトのコンテキストで効果的に提供するのに役立ちます。 また、関係者全員が最新の状態を維持し、将来の包括的なデータ戦略を構築するという全体的な目的に焦点を当てるフォーラムを確立します。
エンゲージメントは、次の 2 つのグループの間で不可欠です。
- データ戦略を設計して実装するチーム メンバー
- データに貢献し、使用し、悪用するチーム メンバー (意思決定を行い、データに基づいて結果を構築するビジネス ユニットなど)
別の言い方をすると、関連性と導入におけるユーザー エンゲージメント リスクの課題なしで構築されたデータ戦略と関連するデータ プラットフォームです。
このフレームワークでは、次の 2 つの戦略的プロセスが成功に役立ちます。
- センター オブ エクセレンスの形成
- アジャイル配信方法の導入
詳細については、「クラウド規模の分析の計画を作成する」を参照してください。
価値を提供する
標準化された構造化された方法で成功条件に対してデータ製品を配信すると、その配信によって反復的なフレームワークが検証されます。 さらに、学習を使用して継続的にイノベーションを行うことで、ビジネスの信頼度を高め、データ戦略の目標を拡大することができます。 このプロセスにより、組織全体でより明確かつ迅速に導入できます。
データ プラットフォームにも同じことが当てはまります。 複数のチームが自律的に動作するセットアップがある場合は、メッシュに向かって進む必要があります。 そこに到達するには反復的なプロセスが必要です。 多くの場合、組織のセットアップ、準備、ビジネスの調整に大きな変更が必要です。
次の手順
クラウド導入体験のガイダンスを見つけて、クラウド導入シナリオを成功させるには、次の記事を参照してください。