Azure でのクラウド規模の分析を使用したデータ サイエンス プロジェクトのベスト プラクティス
Microsoft Azure でクラウド規模の分析を使用してデータ サイエンス プロジェクトを運用化するためのベスト プラクティスをお勧めします。
テンプレートを開発する
データ サイエンス プロジェクトの一連のサービスをバンドルするテンプレートを開発します。 一連のサービスをバンドルするテンプレートを使用して、さまざまなデータ サイエンス チームのユース ケース間の一貫性を提供します。 テンプレート リポジトリの形式で一貫したブループリントを開発することをお勧めします。 このリポジトリは、企業内のさまざまなデータ サイエンス プロジェクトに使用して、デプロイ時間の短縮に役立ちます。
データ サイエンス テンプレートのガイドライン
次のガイドラインを使用して、組織のデータ サイエンス テンプレートを開発します。
Azure Machine Learning ワークスペースをデプロイするための一連のコードとしてのインフラストラクチャ (IaC) テンプレートを開発します。 キー コンテナー、ストレージ アカウント、コンテナー レジストリ、Application Insights などのリソースを含めます。
これらのテンプレートには、コンピューティング インスタンス、コンピューティング クラスター、Azure Databricks などのデータ ストアとコンピューティング ターゲットのセットアップを含めます。
デプロイのベスト プラクティス
リアルタイム
- テンプレートと Azure Cognitive Services に Azure Data Factory または Azure Synapse デプロイを含めます。
- テンプレートには、データ サイエンス探索フェーズとモデルの初期運用化を実行するために必要なすべてのツールが用意されている必要があります。
初期セットアップに関する考慮事項
場合によっては、組織内のデータ サイエンティストが、必要に応じて迅速に分析するための環境を必要とする場合があります。 この状況は、データ サイエンス プロジェクトが正式に設定されていない場合に一般的です。 たとえば、不足している要素に承認が必要なため、Azure 内でのクロス課金に必要なプロジェクト マネージャー、コスト コード、またはコスト センターが不足している可能性があります。 組織またはチームのユーザーは、データを理解し、プロジェクトの実現可能性を評価するために、データ サイエンス環境にアクセスする必要がある場合があります。 また、データ製品の数が少ないため、完全なデータ サイエンス環境を必要としないプロジェクトもあります。
また、専用の環境、プロジェクト管理、コスト コード、コスト センターを備えた完全なデータ サイエンス プロジェクトが必要になる場合もあります。 完全なデータ サイエンス プロジェクトは、複数のチーム メンバーが共同作業を行い、結果を共有し、探索フェーズが成功した後にモデルを運用化する必要がある場合に役立ちます。
セットアップ プロセス
テンプレートは、セットアップ後にプロジェクトごとにデプロイする必要があります。 各プロジェクトは、開発環境と運用環境を分離するために、少なくとも 2 つのインスタンスを受け取る必要があります。 運用環境では、個々のユーザーがアクセスする必要はなく、継続的インテグレーションまたは継続的開発パイプラインとサービス プリンシパルを通じてすべてをデプロイする必要があります。 Azure Machine Learning では、ワークスペース内にきめ細かなロールベースのアクセス制御モデルが提供されないため、これらの運用環境の原則は重要です。 特定の実験セット、エンドポイント、またはパイプラインへのユーザー アクセスを制限することはできません。
通常、同じアクセス権はさまざまな種類の成果物に適用されます。 ワークスペース内の運用パイプラインまたはエンドポイントが削除されないように、開発と運用環境を分離することが重要です。 テンプレートと共に、データ製品チームに新しい環境を要求するオプションを提供するプロセスを構築する必要があります。
Azure Cognitive Services などのさまざまな AI サービスをプロジェクトごとに設定することをお勧めします。 プロジェクトごとに異なる AI サービスを設定することで、データ製品リソース グループごとにデプロイが行われます。 このポリシーにより、データ アクセスの観点から明確に分離され、間違ったチームによる不正なデータ アクセスのリスクが軽減されます。
ストリーミング シナリオ
リアルタイムおよびストリーミングのユース ケースでは、Azure Kubernetes Service (AKS)
次に、必要なサービスにモデルをデプロイできます。 このデプロイ コンピューティング ターゲットは、AKS クラスター内の運用環境のワークロードで一般公開され、推奨される唯一のターゲットです。 この手順は、グラフィックス処理装置 (GPU) またはフィールド プログラマブル ゲート アレイのサポートが必要な場合に必要になります。 これらのハードウェア要件をサポートするその他のネイティブ デプロイ オプションは、現在 Azure Machine Learning では使用できません。
Azure Machine Learning には、AKS クラスターへの 1 対 1 のマッピングが必要です。 Azure Machine Learning ワークスペースへの新しい接続はすべて、AKS と Azure Machine Learning の間の以前の接続を切断します。 その制限を軽減した後は、中央の AKS クラスターを共有リソースとしてデプロイし、それぞれのワークスペースにアタッチすることをお勧めします。
モデルを運用 AKS に移動する前にストレス テストを実行する必要がある場合は、別の中央テスト AKS インスタンスをホストする必要があります。 テスト環境では、運用環境と同じコンピューティング リソースを提供して、結果が運用環境と可能な限り類似していることを確認する必要があります。
バッチシナリオ
すべてのユース ケースで AKS クラスターのデプロイが必要なわけではありません。 大量のデータが定期的にスコア付けする必要がある場合、またはイベントに基づいている場合、ユース ケースでは AKS クラスターのデプロイは必要ありません。 たとえば、データが特定のストレージ アカウントにドロップするタイミングに基づいて、大量のデータを使用できます。 これらの種類のシナリオでは、Azure Machine Learning パイプラインと Azure Machine Learning コンピューティング クラスターをデプロイに使用する必要があります。 これらのパイプラインは、Data Factory で調整して実行する必要があります。
適切なコンピューティング リソースを特定する
Azure Machine Learning のモデルを AKS にデプロイする前に、ユーザーは、それぞれのモデルに割り当てる必要がある CPU、RAM、GPU などのリソースを指定する必要があります。 これらのパラメーターの定義は、複雑で面倒なプロセスになる可能性があります。 適切なパラメーター セットを識別するには、さまざまな構成でストレス テストを実行する必要があります。 このプロセスは、Azure Machine Learning の モデル プロファイリング 機能を使用して簡略化できます。これは、さまざまなリソース割り当ての組み合わせをテストし、識別された待機時間とラウンド トリップ時間 (RTT) を使用して最適な組み合わせを推奨する、実行時間の長いジョブです。 この情報は、AKS での実際のモデルのデプロイに役立つ可能性があります。
Azure Machine Learning でモデルを安全に更新するには、チームは制御されたロールアウト機能 (プレビュー) を使用してダウンタイムを最小限に抑え、モデルの REST エンドポイントの一貫性を維持する必要があります。
MLOps のベスト プラクティスとワークフロー
データ サイエンス リポジトリにサンプル コードを含める
チームに特定の成果物とベスト プラクティスがある場合は、データ サイエンス プロジェクトを簡略化して高速化できます。 すべてのデータ サイエンス チームが Azure Machine Learning とデータ製品環境のそれぞれのツールを操作するときに使用できる成果物を作成することをお勧めします。 データと機械学習のエンジニアは、成果物を作成して提供する必要があります。
これらの成果物には、次のものが含まれている必要があります。
次の方法を示すサンプル ノートブック:
- データ製品の読み込み、マウント、操作。
- メトリックとパラメーターをログに記録します。
- トレーニング ジョブをコンピューティング クラスターに送信します。
運用に必要な成果物:
- Azure Machine Learning パイプラインのサンプル
- サンプルの Azure Pipelines
- パイプラインを実行するために必要なその他のスクリプト
ドキュメンテーション
適切に設計された成果物を使用してパイプラインを運用化する
成果物を使用すると、データ サイエンス プロジェクトの探索と運用化のフェーズを高速化できます。 DevOps フォーク戦略は、すべてのプロジェクトでこれらの成果物をスケーリングするのに役立ちます。 このセットアップにより Git の使用が促進されるため、ユーザーと全体的な自動化プロセスは、提供された成果物の恩恵を受けることができます。
ヒント
Azure Machine Learning サンプル パイプラインは、Python ソフトウェア開発者キット (SDK) を使用するか、YAML 言語に基づいて構築する必要があります。 Azure Machine Learning 製品チームは現在、新しい SDK とコマンド ライン インターフェイス (CLI) に取り組んでいるので、新しい YAML エクスペリエンスは将来性が高まります。 Azure Machine Learning 製品チームは、YAML が Azure Machine Learning 内のすべての成果物の定義言語として機能することを確信しています。
サンプル パイプラインはプロジェクトごとにすぐには機能しませんが、ベースラインとして使用できます。 プロジェクトのサンプル パイプラインを調整できます。 パイプラインには、各プロジェクトの最も関連性の高い側面を含める必要があります。 たとえば、パイプラインでは、コンピューティング 先を参照したり、データ製品を参照したり、パラメーターを定義したり、入力を定義したり、実行手順を定義したりできます。 Azure Pipelines に対して同じプロセスを実行する必要があります。 Azure Pipelines では、Azure Machine Learning SDK または CLI も使用する必要があります。
パイプラインでは、次の方法を示す必要があります。
- DevOps パイプライン内からワークスペースに接続します。
- 必要なコンピューティングが使用可能かどうかを確認します。
- ジョブを送信する。
- モデルを登録してデプロイします。
成果物は常にすべてのプロジェクトに適しているわけではなく、カスタマイズが必要になる場合がありますが、基盤を持つことで、プロジェクトの運用化とデプロイを高速化できます。
MLOps リポジトリの構造
ユーザーがアーティファクトを見つけて格納できる場所を追跡できなくなる場合があります。 このような状況を回避するには、標準リポジトリの最上位フォルダー構造を通信して構築するための時間を増やす必要があります。 すべてのプロジェクトはフォルダー構造に従う必要があります。
手記
このセクションで説明する概念は、オンプレミス、アマゾン ウェブ サービス、Palantir、Azure の各環境で使用できます。
MLOps (機械学習操作) リポジトリに対して提案された最上位フォルダー構造を次の図に示します。
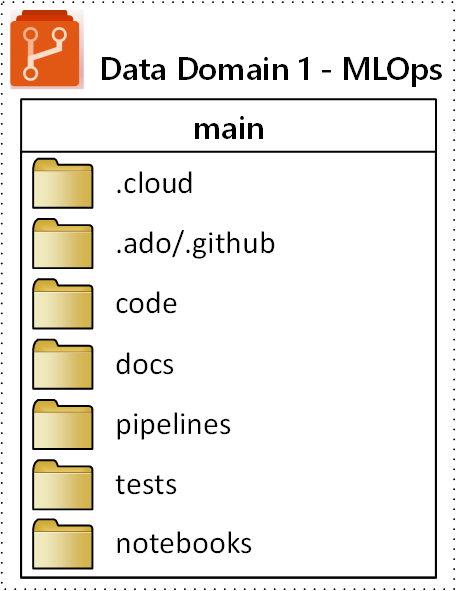
リポジトリ内の各フォルダーには、次の目的が適用されます。
| フォルダー | 目的 |
|---|---|
.cloud |
クラウド固有のコードと成果物をこのフォルダーに格納します。 成果物には、コンピューティング 先の定義、ジョブ、登録済みモデル、エンドポイントなど、Azure Machine Learning ワークスペースの構成ファイルが含まれます。 |
.ado/.github |
YAML パイプラインやコード所有者などの Azure DevOps または GitHub 成果物をこのフォルダーに格納します。 |
code |
プロジェクトの一部として開発された実際のコードをこのフォルダーに含めます。 このフォルダーには、Python パッケージと、機械学習パイプラインのそれぞれの手順に使用されるいくつかのスクリプトを含めることができます。 このフォルダーで行う必要がある個々の手順を分離することをお勧めします。 一般的な手順は、前処理、モデルトレーニング、そして モデル登録です。 Conda の依存関係、Docker イメージなどの依存関係を各フォルダーに定義します。 |
docs |
このフォルダーは、ドキュメントの目的で使用します。 このフォルダーには、プロジェクトを記述するための Markdown ファイルと画像が格納されます。 |
pipelines |
このフォルダーの YAML または Python に Azure Machine Learning パイプライン定義を格納します。 |
tests |
このフォルダー内のプロジェクトの早い段階でバグや問題を検出するために実行する必要がある単体テストと統合テストを記述します。 |
notebooks |
このフォルダーを使用して、実際の Python プロジェクトから Jupyter ノートブックを分離します。 フォルダー内には、各ユーザーがノートブックをチェックインし、Git マージの競合を防ぐためのサブフォルダーが必要です。 |