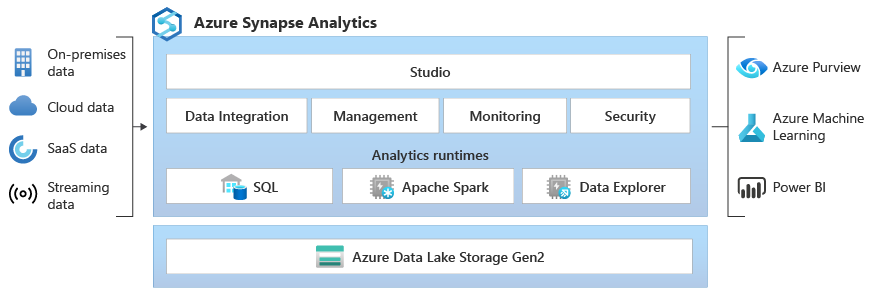
Azure Synapse Data Explorer とは (プレビュー)
Azure Synapse Data Explorer は、ログとテレメトリ データから分析情報を引き出すための対話型クエリ エクスペリエンスをお客様に提供します。 既存の SQL および Apache Spark 分析ランタイム エンジンを補完するために、Data Explorer の分析ランタイムは、効率的なログ分析用に最適化されており、強力なインデックス作成テクノロジを使用して、テレメトリ データに一般的なフリーテキスト データと半構造化データのインデックスを自動的に作成します。
詳細については、次のビデオを参照してください。
Azure Synapse Data Explorer を唯一無二の存在にしている要素は何ですか?
インジェストが容易 - Data Explorer には、高スループットのデータ インジェストとリアルタイム ソースからのデータのキャッシュをノーコードまたはローコードで実現する組み込みの統合機能が備わっています。 Azure Event Hubs、Kafka、Azure Data Lake などのソースや、Fluentd、Fluent Bit などのオープン ソース エージェント、さらには、多種多様なクラウド ソースおよびオンプレミス データ ソースからデータを取り込むことができます。
複雑なデータ モデリングが不要 - Data Explorer では、複雑なデータ モデルを作成する必要がありません。消費される前のデータを変換するための複雑なスクリプトも不要です。
インデックスのメンテナンスが不要 - クエリのパフォーマンスを目的としたデータ最適化のメンテナンス作業は不要です。また、インデックスのメンテナンスも必要ありません。 Data Explorer では、すべての生データがすぐに利用できるため、ストリーミング データと永続データに対してハイパフォーマンス、かつハイ コンカレンシーのクエリを実行できます。 これらのクエリを使用して、凖リアルタイムのダッシュボードやアラートを作成したり、その他のデータ分析プラットフォーム機能に運用分析データを結び付けたりすることができます。
データ分析を民主化 - Data Explorer は、Excel の手軽さと SQL の表現力、そしてパワーを兼ね備えた直感的な Kusto 照会言語 (KQL) によって、セルフ サービスのビッグ データ分析のハードルを下げます。 KQL は、生のテレメトリ データと時系列データを調査する目的に対して高度に最適化されています。そのために活用されているのが、Data Explorer のクラス最高のテキスト インデックス作成テクノロジを使用した効率的なフリー テキスト検索と正規表現検索、そして、包括的な解析機能を使用したトレース データやテキスト データ、JSON 半構造化データ (配列や入れ子の構造も含む) のクエリです。 KQL では、複数の時系列を作成、操作、分析する先進の時系列機能と、エンジン内で Python を実行してモデルのスコアリングを行う機能がサポートされています。
ペタバイト スケールの実績あるテクノロジ - Data Explorer は、別々にスケーリングできるコンピューティング リソースとストレージを備えた分散システムであるため、ギガバイト規模やペタバイト規模のデータを分析することができます。
統合 - Azure Synapse Analytics は、Data Explorer、Apache Spark、SQL エンジンの垣根を越えたデータ相互運用性を備えているため、データ エンジニアやデータ サイエンティスト、データ アナリストは、容易にかつ安全に、データ レイク内の同じデータにアクセスし、共同作業を行うことができます。
Azure Synapse Data Explorer はどのような場合に使用するのですか?
ログ分析と IoT 分析を準リアルタイムで行うソリューションを構築するためのデータ プラットフォームとして Data Explorer を使うことにより、次のことが可能となります。
オンプレミス、クラウド、サードパーティのデータ ソースの垣根を超えてログとイベントのデータを統合し、関連付けます。
AI Ops の取り組みを促進します (パターン認識、異常検出、予測など)。
インフラストラクチャベースのログ検索ソリューションを置き換えて、コストを節約し、生産性を向上させます。
IoT データ用の IoT 分析ソリューションを構築します。
内部および外部の顧客にサービスを提供する分析 SaaS ソリューションを構築します。
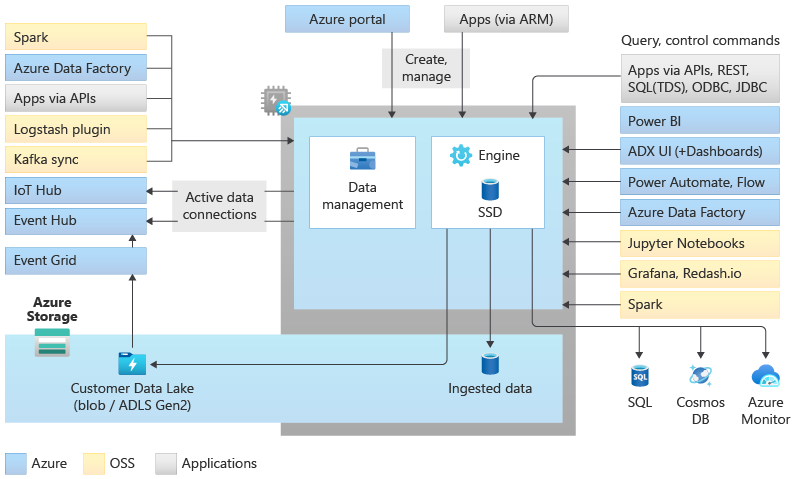
Data Explorer プールのアーキテクチャ
Data Explorer プールは、コンピューティング リソースとストレージ リソースを分離することで、スケールアウト アーキテクチャを実現します。 これによって、それぞれのリソースを別々にスケーリングし、たとえば、同じデータに対して複数の読み取り専用コンピューティングを実行することができます。 Data Explorer のプールは、インデックス作成、圧縮、キャッシュ、分散クエリ処理の自動実行を担うエンジンを実行する一連のコンピューティング リソースで構成されます。 また、それとは別に、バックグラウンド システム ジョブ、マネージド データ インジェスト、キュー データ インジェストを担うデータ管理サービスを実行する一連のコンピューティング リソースも備わっています。 すべてのデータは、圧縮列形式を使用してマネージド BLOB ストレージ アカウントに永続化されます。
Data Explorer のプールは、コネクタ、SDK、REST API などのマネージド機能を使用してデータを取り込むための豊富なエコシステムをサポートします。 アドホック クエリ、レポート、ダッシュボード、アラート、REST API、SDK 用に、データを使用するさまざまな方法が用意されています。
Azure におけるログ分析と時系列分析に最適な分析エンジンとして、Data Explore は他にはない特別な機能を数多く備えています。
以降のセクションでは、主な差別化要因に注目します。
フリーテキスト データと半構造化データのインデックス作成によって、高パフォーマンス、高コンカレンシーの、凖リアルタイムのクエリが可能となります
Data Explorer では半構造化データ (JSON) および非構造化データ (フリー テキスト) のインデックスを作成することにより、この種のデータに対するクエリ実行のパフォーマンスが高まります。 既定では、データ インジェスト時にすべてのフィールドのインデックスが作成されますが、必要に応じて、低レベルのエンコーディング ポリシーを使って、特定のフィールドのインデックスを微調整したり無効にしたりすることができます。 インデックスのスコープは、個々のデータ シャードです。
次に示したように、インデックスの実装はフィールドの型によって異なります。
| フィールドの種類 | インデックスの実装 |
|---|---|
| String | 文字列型列の値には、エンジンによって語句の逆引きインデックスが作成されます。 各文字列値は分析されて、正規化された語句に分割されます。その個々の語句について、レコードの序数を含んだ論理位置の順序指定済みリストが記録されます。 その結果、語句とその対応する位置の並べ替え済みリストが得られ、不変の B ツリーとして格納されます。 |
|
数字 DateTime TimeSpan |
シンプルな範囲ベースの正引きインデックスがエンジンによって作成されます。 インデックスには、各ブロックの最小値と最大値、ブロックのグループの最小値と最大値、データ シャード内の列全体の最小値と最大値が記録されます。 |
| 動的 | インジェスト プロセスで、動的な値に含まれる "アトミック" な要素 (プロパティ名、値、配列要素など) がすべて列挙されてインデックス ビルダーに転送されます。 動的フィールドには、文字列フィールドと同じ逆引きの語句インデックスが作成されます。 |
こうした効率的なインデックス作成機能によって、Data Explore は、準リアルタイムでデータを提供する高パフォーマンス、高コンカレンシーのクエリを実現しています。 パフォーマンスをさらに高めるために、データ シャードは自動的に最適化されます。
Kusto クエリ言語
Azure Monitor Log Analytics と Application Insights、Microsoft Sentinel、Azure Data Explore など、Microsoft オファリングの急速な普及に伴い、KQL には大規模なコミュニティが形成されています。 この言語は読みやすい構文を目指して設計されており、1 行だけの簡単なクエリから複雑なデータ処理クエリへとスムーズに移行できます。 このことが、Data Explorer の充実した IntelliSense のサポートと豊富な言語コンストラクト、そして、SQL では利用できない集計、時系列、ユーザー分析のための組み込み機能によるテレメトリ データの高速な探索を可能にしています。