Azure Web PubSub Service の回復性とディザスター リカバリー
回復性とディザスター リカバリーは、各種オンライン システムに共通の要件です。 Azure Web PubSub Service では既に 99.9% の可用性が保証されていますが、それはまだリージョン サービスです。 リージョン規模の停止が発生したときに、サービスによるリアルタイム メッセージの処理を、別のリージョンで続行することが極めて重要です。
リージョンのディザスター リカバリーを行う場合は、次の 2 つの方法をお勧めします。
- geo レプリケーションを有効にする (簡単な方法)。 この機能は、リージョンのフェールオーバーを自動的に処理します。 有効にすると、Azure SignalR インスタンスは 1 つだけのままで、コードの変更は発生しません。 詳細については、geo レプリケーションに関するページを確認してください。
- 複数のエンドポイントを利用します。 このドキュメントでは、その方法について説明します。
Web PubSub サービスの高可用性アーキテクチャ
Web PubSub サービスを使用する一般的なパターンは 2 つあります。
- 1 つは、クライアントがサーバーにイベントを送信し、サーバーがクライアントにメッセージをプッシュするクライアント サーバー パターンです。
- もう 1 つは、Web PubSub サービスを介してクライアントから他のクライアントとメッセージを送受信 (pub/sub) するクライアント/クライアント パターンです。
以下のセクションでは、これら 2 つのパターンでディザスター リカバリーを行うさまざまな方法について説明します。
クライアント/サーバー パターンの高可用性アーキテクチャ
Web PubSub サービスでリージョンをまたぐ回復性を確保するためには、複数のサービス インスタンスを異なるリージョンにセットアップする必要があります。 そうすることで、1 つのリージョンがダウンしても、その他のリージョンをバックアップとして使用することができます。
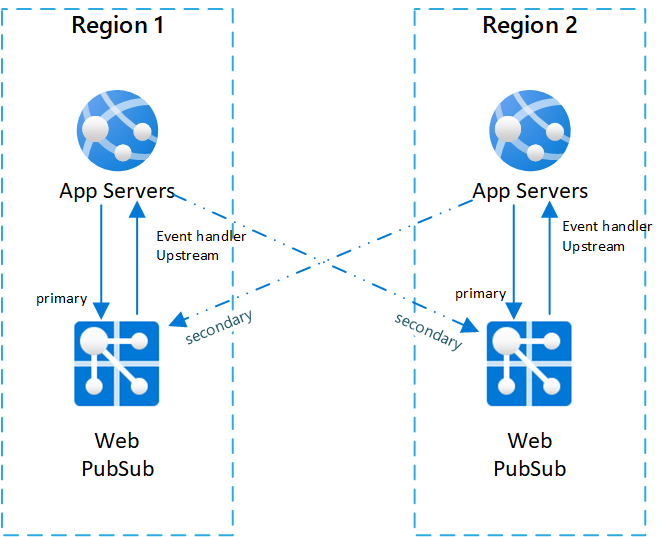
リージョンをまたぐシナリオの一般的な 1 つの構成は、Web PubSub サービス インスタンスとアプリ サーバーのペアを 2 組 (またはそれ以上) 用意することです。
アプリ サーバーと Web PubSub サービスのペアはそれぞれ同じリージョンに配置され、Web PubSub サービスによって同じリージョン内のアプリ サーバーへのイベント ハンドラー アップストリームが設定されます。
アーキテクチャをわかりやすく説明するために、Web PubSub サービスを同じペアのアプリ サーバーに対するプライマリ サービスと呼びます。 また、他のペアの Web PubSub サービスを、アプリ サーバーに対するセカンダリ サービスと呼びます。
アプリケーション サーバーでは、サービス正常性チェック API を使用して、プライマリ サービスとセカンダリ サービスが正常であるかどうかが検出されます。 たとえば、demo という名前の Web PubSub サービスの場合、サービスが正常であれば、https://demo.webpubsub.azure.com/api/health エンドポイントによって 200 が返されます。 アプリ サーバーでは、エンドポイントを定期的に呼び出すかオンデマンドでエンドポイントを呼び出して、エンドポイントが正常かどうかを確認できます。 WebSocket クライアントでは、通常、まずアプリケーション サーバーとのネゴシエートを行って、Web PubSub サービスに接続するための URL が取得され、アプリケーションでは、このネゴシエート手順を使用して、クライアントの他の正常なセカンダリ サービスへのフェールオーバーが行われます。 詳細な手順は次のとおりです。
- クライアントによるアプリ サーバーとのネゴシエート時、アプリ サーバーによって返されるのはプライマリ Web PubSub サービス エンドポイントのみであるため、通常の場合、クライアントの接続先はプライマリ エンドポイントのみになります。
- プライマリ インスタンスがダウンしている場合は、ネゴシエートによって正常なセカンダリ エンドポイントが返されるため、クライアントの接続は引き続き可能であり、クライアントはセカンダリ エンドポイントに接続されます。
- プライマリ インスタンスが起動している場合は、ネゴシエートによって正常なプライマリ エンドポイントが返されるため、クライアントではプライマリ エンドポイントに接続できるようになります。
- アプリ サーバーでメッセージをブロードキャストする場合は、プライマリとセカンダリの両方を含むすべての正常なエンドポイントにメッセージがブロードキャストされる必要があります。
- アプリ サーバーでは、セカンダリ エンドポイントに接続されている接続を閉じることで、クライアントが正常なプライマリ エンドポイントに再接続するように強制できます。
このトポロジによって、すべてのアプリ サーバーと Web PubSub サービス インスタンスが相互接続されているので、引き続き 1 つのサーバーからのメッセージをすべてのクライアントに配信できます。
この戦略は SDK にまだ統合されていないため、今のところ、アプリケーションでこの戦略を単独で実装する必要があります。
アプリケーション側で実装する必要があるものの要約を次に示します。
- 正常性チェック: アプリケーションでは、サービス正常性チェック API をバックグラウンドで定期的に使用するか、すべてのネゴシエート呼び出しに対してオンデマンドで実行して、サービスが正常であるかどうかを確認できます。
- ネゴシエート ロジック: 既定では、アプリケーションによって正常なプライマリ エンドポイントが返されます。 プライマリ エンドポイントがダウンしている場合は、アプリケーションによって正常なセカンダリ エンドポイントが返されます。
- ブロードキャスト ロジック: 複数のクライアントにメッセージを送信する場合、アプリケーションでは、正常なすべてのエンドポイントにメッセージをブロードキャストする必要があります。
次の図は、そのようなトポロジを示したものです。
フェールオーバーのシーケンスとベスト プラクティス
以上で、適切なシステム トポロジのセットアップが完了しました。 片方の Web PubSub サービス インスタンスがダウンすると、オンライン トラフィックは他方のインスタンスにルーティングされます。 プライマリ インスタンスがダウンしたとき (そしてその後しばらくしてから復旧するとき) の挙動を次に示します。
- プライマリ サービス インスタンスがダウンすると、このインスタンスに接続されているすべてのサーバーが切断されます。
- 新しいクライアントまたは再接続クライアントによるアプリ サーバーとのネゴシエート
- アプリ サーバーによってプライマリ サービス インスタンスの停止が検出され、ネゴシエートでこのエンドポイントを返すことが停止され、正常なセカンダリエンド ポイントを返すことが開始されます。
- クライアントは、セカンダリ インスタンスに接続されます。
- これですべてのオンライン トラフィックがセカンダリ インスタンスに向かうようになりました。 セカンダリはすべてのアプリ サーバーに接続されているため、サーバーからクライアントへのメッセージは依然としてすべて配信されます。 ただし、クライアントからサーバーへのイベント メッセージは、同じリージョン内のアップストリーム アプリ サーバーにのみ送信されます。
- プライマリ インスタンスが回復してオンラインに戻ると、アプリ サーバーによってプライマリ インスタンスが正常な状態に戻ったことが検出されます。 以後ネゴシエートでは再びプライマリ エンドポイントが返されるようになるので、新しいクライアントは元どおりプライマリに接続されます。 ただし、既存のクライアントは切断されず、自ら切断するまでそのままセカンダリへの接続が続行されます。
下の図は、フェールオーバーのしくみを示しています。
図.1 フェールオーバー前 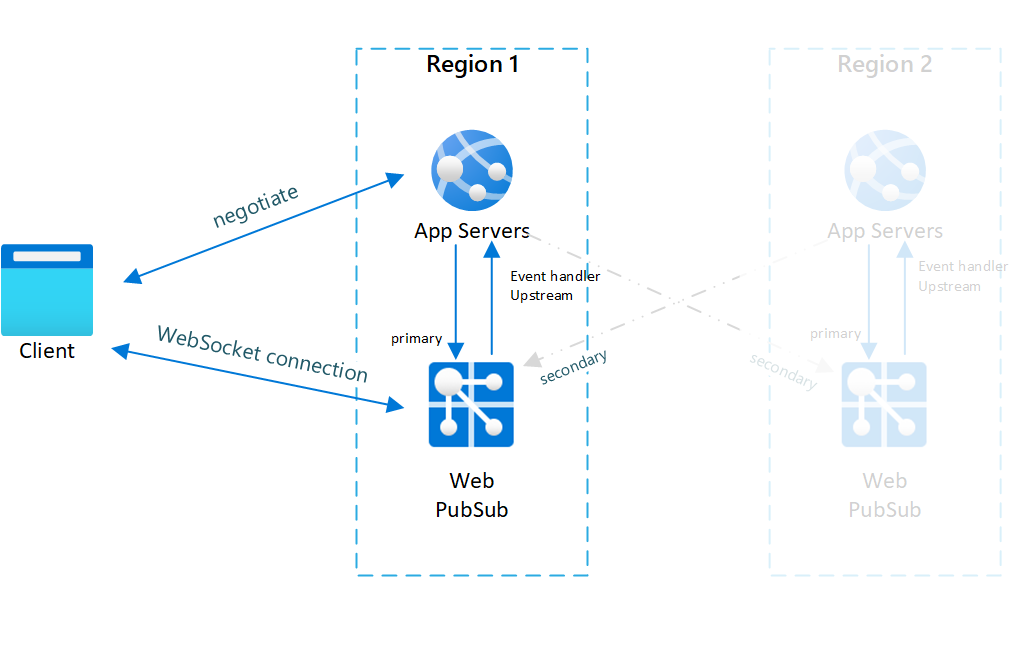
図.2 フェールオーバー後 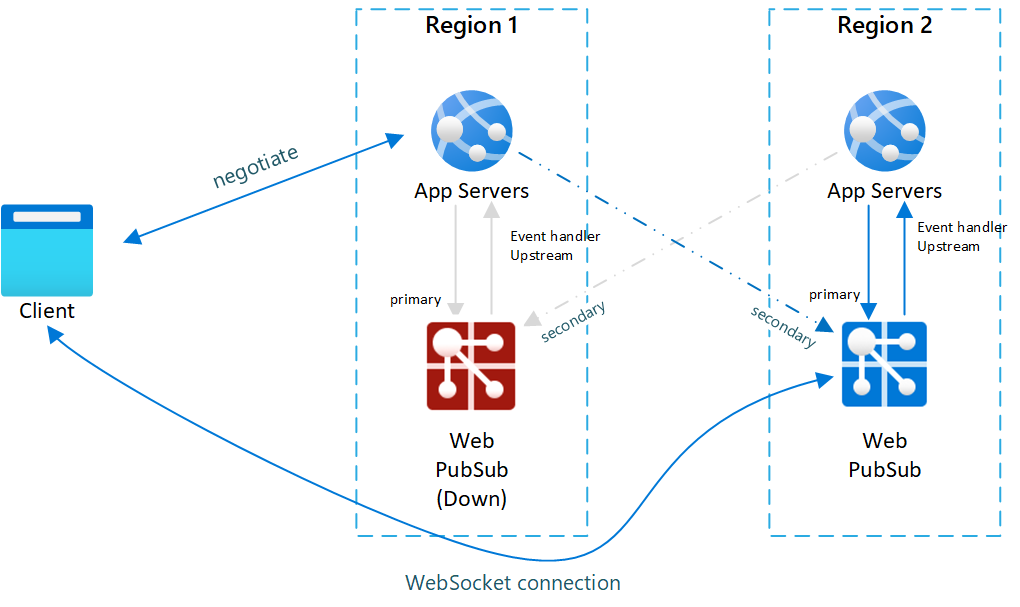
図.3 プライマリの復旧後間もなく 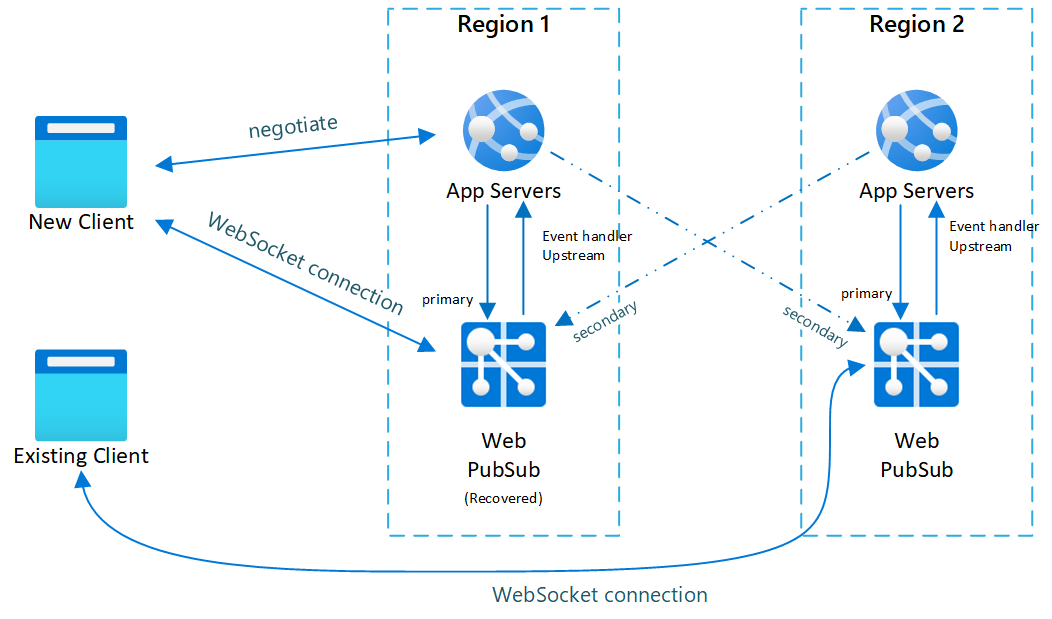
通常は、プライマリのアプリ サーバーと Web PubSub サービスにのみオンライン トラフィック (青色) があることがわかります。
フェールオーバー後は、セカンダリのアプリ サーバーと Web PubSub サービスもアクティブになります。 プライマリの Web PubSub サービスがオンラインに戻った後、新しいクライアントはプライマリの Web PubSub に接続されます。 一方、既存のクライアントはそのままセカンダリに接続された状態になるので、両方のインスタンスにトラフィックが向かうことになります。
既存のクライアントがすべて切断されると、システムが正常な状態に戻ります (図 1)。
リージョンをまたぐ高可用性アーキテクチャを導入する場合、主に次の 2 つのパターンがあります。
- 1 つ目は、アプリ サーバーと Web PubSub サービス インスタンスの 1 つのペアですべてのオンライン トラフィックを処理し、別のペアをバックアップとして使用する方法です (これは "アクティブ/パッシブ" と呼ばれます。図 1 を参照)。
- もう 1 つは、アプリ サーバーと Web PubSub サービス インスタンスのペアを 2 つ (またはそれ以上) 用意し、それぞれのペアでオンライン トラフィックを分担して処理し、他のペアのバックアップとして機能させる方法です (これは "アクティブ/アクティブ" と呼ばれます。図 3 と同様)。
Web PubSub サービスでは両方のパターンをサポートできます。主な違いはアプリ サーバーの実装方法です。 アプリ サーバーがアクティブ/パッシブである場合、Web PubSub サービスもアクティブ/パッシブになります (プライマリのアプリ サーバーから返されるのはそのプライマリ Web PubSub サービス インスタンスのみであるため)。 アプリ サーバーがアクティブ/アクティブである場合、Web PubSub サービスもアクティブ/アクティブになります (すべてのアプリ サーバーから、それぞれのプライマリ Web PubSub インスタンスが返されるので、そのすべてのインスタンスでトラフィックを受けることができます)。
どちらのパターンを使用するにしても、それぞれの Web PubSub サービス インスタンスをプライマリ ロールとしてアプリ サーバーに接続する必要があることに注意してください。
また、WebSocket 接続 (長時間接続) の性質上、障害とフェールオーバーが発生すると、クライアントで接続の切断が発生します。 そのようなケースはクライアント側で処理して、エンド ユーザーからは見えないようにする必要があります。 たとえば、接続が閉じられた後で再接続を行うことが考えられます。
クライアント/クライアント パターンの高可用性アーキテクチャ
現在のところ、クライアント/クライアント パターンでは、複数のインスタンスを使用したダウンタイムの無いディザスター リカバリーはサポートされていません。 高可用性の要件がある場合は、geo レプリケーションを使用することを検討してください。
フェールオーバーをテストする方法
フェールオーバーをトリガーするには、次の手順に従います。
- ポータルのプライマリ リソースの [ネットワーク] タブで、パブリック ネットワーク アクセスを無効にします。 リソースでプライベート ネットワークが有効になっている場合は、"アクセス制御ルール" を使用して、すべてのトラフィックを拒否します。
- プライマリ リソースを再起動します。
次のステップ
この記事では、Web PubSub サービスに回復性を持たせるためのアプリケーションの構成方法について説明しました。
これらのリソースを使用して、独自のアプリケーションの構築を開始します。