チュートリアル: Azure の Ubuntu 仮想マシンで SQL Server の可用性グループを構成する
このチュートリアルで学習する内容は次のとおりです。
- 仮想マシンを作成し、可用性セット内に配置します。
- 高可用性 (HA) を有効にする
- Pacemaker クラスターの作成
- STONITH デバイスを作成してフェンス エージェントを構成する
- SQL Server と mssql-tools を Ubuntu にインストールする
- SQL Server Always On 可用性グループを構成する
- Pacemaker クラスター内に可用性グループ (AG) のリソースを構成する
- フェールオーバーとフェンス エージェントをテストする
Note
バイアスフリーなコミュニケーション
この記事には、この文脈で使用した場合に不快感を与えると Microsoft が考える slave (スレーブ、奴隷) という用語の言及が含まれています。 これはソフトウェアに現在表示されるものであるため、この記事に出現します。 ソフトウェアからこの用語が削除された時点で、この記事から削除します。
このチュートリアルでは、Azure CLI を使用して、Azure にリソースをデプロイします。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
Azure Cloud Shell で Bash 環境を使用します。 詳細については、「Azure Cloud Shell の Bash のクイックスタート」を参照してください。

CLI リファレンス コマンドをローカルで実行する場合、Azure CLI をインストールします。 Windows または macOS で実行している場合は、Docker コンテナーで Azure CLI を実行することを検討してください。 詳細については、「Docker コンテナーで Azure CLI を実行する方法」を参照してください。
ローカル インストールを使用する場合は、az login コマンドを使用して Azure CLI にサインインします。 認証プロセスを完了するには、ターミナルに表示される手順に従います。 その他のサインイン オプションについては、Azure CLI でのサインインに関するページを参照してください。
初回使用時にインストールを求められたら、Azure CLI 拡張機能をインストールします。 拡張機能の詳細については、Azure CLI で拡張機能を使用する方法に関するページを参照してください。
az version を実行し、インストールされているバージョンおよび依存ライブラリを検索します。 最新バージョンにアップグレードするには、az upgrade を実行します。
- この記事では、Azure CLI のバージョン 2.0.30 以降が必要です。 Azure Cloud Shell を使用している場合は、最新バージョンが既にインストールされています。
リソース グループを作成する
複数のサブスクリプションがある場合は、これらのリソースをデプロイするサブスクリプションを設定します。
次のコマンドを使用して、リージョンにリソース グループ <resourceGroupName> を作成します。 <resourceGroupName> は、任意の名前に置き換えてください。 このチュートリアルでは East US 2 を使用します。 詳細については、次のクイックスタートを参照してください。
az group create --name <resourceGroupName> --location eastus2
可用性セットの作成
次の手順は可用性セットの作成です。 Azure Cloud Shell で次のコマンドを実行します。<resourceGroupName> は、実際のリソース グループ名に置き換えてください。 <availabilitySetName> の名前を選択します。
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
コマンドが完了すると、次の結果が得られます。
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
仮想ネットワークとサブネットの作成
IP アドレス範囲が事前に割り当てられた、名前付きサブネットを作成します。 次のコマンドで、これらの値を置き換えます。
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24前のコマンドでは、VNet と、カスタム IP 範囲を含むサブネットを作成します。
可用性セット内に Ubuntu VM を作成する
Azure で Ubuntu ベースの OS を提供する仮想マシン イメージのリストを取得します。
az vm image list --all --offer "sql2022-ubuntupro2004"BYOS イメージを検索すると、次の結果が表示されます。
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]このチュートリアルでは
Ubuntu 20.04を使用します。重要
可用性グループを設定するには、マシン名の長さが 15 文字未満である必要があります。 ユーザー名に大文字を含めることはできません。また、パスワードは 12 文字以上 72 文字以下である必要があります。
可用性セットに 3 つの VM を作成します。 次のコマンドで、これらの値を置き換えます。
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>- 例: "Standard_D16s_v3"<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
前のコマンドでは、前に定義した VNet を使用して VM を作成します。 さまざまな構成の詳細については、az vm create に関する記事を参照してください。
コマンドには、128 GB のカスタム OS ドライブ サイズを作成するための --os-disk-size-gb パラメーターも含まれています。 後でこのサイズを大きくする場合は、インストールに合わせて適切なフォルダー ボリュームを拡張し、論理ボリューム マネージャー (LVM) を構成します。
各 VM のコマンドが完了すると、次のような結果が得られます。
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
作成された VM への接続をテストする
Azure Cloud Shell で次のコマンドを使用して、それぞれの VM に接続します。 自分の VM の IP がわからない場合は、こちらの Azure Cloud Shell のクイックスタートに従ってください。
ssh <username>@<publicIPAddress>
接続に成功すると、Linux ターミナルを表す次の出力が表示されます。
[<username>@ubuntu1 ~]$
「exit」と入力して SSH セッションを終了します。
ノード間にパスワードなしの SSH アクセスを構成する
パスワードレス SSH アクセスを使用すると、VM で SSH 公開キーを使用して相互に通信できるようになります。 各ノードで SSH キーを構成し、それらのキーを各ノードにコピーする必要があります。
新しい SSH キーを生成する
必要な SSH キー サイズは 4,096 ビットです。 各 VM で /root/.ssh フォルダーに変更し、次のコマンドを実行します。
ssh-keygen -t rsa -b 4096
この手順では、既存の SSH ファイルを上書きするように求められる場合があります。 このプロンプトに同意する必要があります。 パスフレーズを入力する必要はありません。
SSH 公開キーをコピーする
各 VM 上で、ssh-copy-id コマンドを使って、先ほど作成したノードから公開キーをコピーする必要があります。 ターゲット VM 上でターゲット ディレクトリを指定する場合は、-i パラメーターを使用します。
次のコマンド内の <username> アカウントは、VM の作成時に各ノード用に構成したものと同じアカウントにすることができます。 root アカウントを使うこともできますが、運用環境ではこのオプションはお勧めしません。
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
各ノードからのパスワードレス アクセスを確認する
SSH 公開キーが各ノードにコピーされたことを確認するには、各ノードから ssh コマンドを使用します。 キーを正しくコピーした場合は、パスワードの入力は求められず、接続は成功です。
この例では、最初の VM (ubuntu1) から 2 番目と 3 番目のノードに接続しています。 繰り返しになりますが、<username> アカウントは、VM の作成時に各ノード用に構成したものと同じアカウントにすることができます。
ssh <username>@ubuntu2
ssh <username>@ubuntu3
各ノードでパスワードを必要とせずに他のノードと通信できるように、3 つのノードすべてからこのプロセスを繰り返します。
名前解決を構成する
名前解決は、DNS を使用するか、各ノードで etc/hosts ファイルを手動で編集することで構成できます。
DNS と Active Directory の詳細については、「Linux ホスト上の SQL Server を Active Directory ドメインに参加させる」を参照してください。
重要
前の例では、プライベート IP アドレスを使用することをお勧めします。 この構成でパブリック IP アドレスを使用すると、設定が失敗し、VM が外部ネットワークに公開されるおそれがあります。
この例で使用されている VM とその IP アドレスを次に示します。
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
高可用性の有効化
ssh を使用して 3 つの各 VM に接続します。接続したら、次のコマンドを実行して高可用性を有効にします。
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Pacemaker をインストールして構成します。
Pacemaker クラスターの構成を開始するには、必要なパッケージとリソース エージェントをインストールする必要があります。 各 VM で次のコマンドを実行します。
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
次に、プライマリ サーバーで認証キーの作成に進みます。
sudo corosync-keygen
認証キーは /etc/corosync/authkey の場所で生成されます。 次の場所にあるセカンダリ サーバーに認証キーをコピーします: /etc/corosync/authkey。
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
ホーム ディレクトリから認証キーを /etc/corosync に移動します。
sudo mv authkey /etc/corosync/authkey
次のコマンドを使用して、クラスターの作成に進みます。
cd /etc/corosync/
sudo vi corosync.conf
Corosync ファイルを編集して、内容を次のように表示します。
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
corosync.conf ファイルを他のノードにコピーしてから /etc/corosync/corosync.conf にコピーします。
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
Pacemaker と Corosync を再起動し、状態を確認します。
sudo systemctl restart pacemaker corosync
sudo crm status
出力は次の例のようになります。
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
フェンス エージェントを構成する
クラスターでフェンスを構成します。 フェンスとは、クラスター内の障害が発生したノードを分離することです。 フェンスでは、障害が発生したノードを再起動し、ダウンさせ、リセットし、再び起動して、クラスターに再び参加させます。
フェンスを構成するには、次のアクションを実行します。
- Microsoft Entra ID に新規アプリケーションを登録し、新しいシークレットを作成する
- powershell/CLI で json ファイルからカスタム役割を作成する
- クラスター内の VM に役割とアプリケーションを割り当てる
- フェンス エージェントのプロパティを設定する
Microsoft Entra ID に新規アプリケーションを登録し、新しいシークレットを作成する
- ポータルで Microsoft Entra ID に移動し、テナント ID をメモします。
- 左のメニューで [アプリの登録] を選択し、[新規登録] を選択します。
- 名前を入力し、[Accounts in this organization directory only](この組織ディレクトリ内のアカウントのみ) を選択します。
- [アプリケーション タイプ] に [Web] を選択します。サインオン URL (
http://localhost) を入力し、[登録] をクリックします。 - 左のメニューで [証明書とシークレット] を選択し、[新しいクライアント シークレット] を選択します。
- 説明を入力し、有効期限を選択します。
- シークレットの値をメモします。これは次のパスワードとシークレット ID として使用され、次のユーザー名として使用されます。
- [概要] を選択し、アプリケーション ID をメモします。 これは、次のログインとして使用されます。
fence-agent-role.json と言う JSON ファイルを作成し、次を追加します (サブスクリプション ID を追加します)。
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
PowerShell/CLI で JSON ファイルからカスタム役割を作成する
az role definition create --role-definition fence-agent-role.json
クラスター内の VM に役割とアプリケーションを割り当てる
- クラスター内の各 VM について、サイド メニューから [アクセス制御 (IAM)] を選択します。
- [ロールの割り当てを追加する] を選択します (クラシック エクスペリエンスを使用します)。
- 前に作成した役割を選択します。
- [選択] 一覧に、前に作成したアプリケーションの名前を入力します。
これで、前の値とサブスクリプション ID を使用してフェンス エージェント リソースを作成できます。
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
フェンス エージェントのプロパティを設定する
次のコマンドを実行して、フェンス エージェントのプロパティを設定します。
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
クラスターの状態を確認します。
sudo crm status
出力は次の例のようになります。
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
SQL Server と mssql-tools をインストールする
SQL Server をインストールするには、次のコマンドを使用します。
パブリック リポジトリの GPG キーをインポートします。
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascUbuntu リポジトリを登録します。
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"次のコマンドを実行して SQL Server をインストールします。
sudo apt-get update sudo apt-get install -y mssql-serverパッケージのインストールが完了したら、
mssql-conf setupを実行し、プロンプトに従って SA パスワードを設定し、エディションを選択します。 次のエディションは無料でライセンスが付与されます。Evaluation、Developer、Express。sudo /opt/mssql/bin/mssql-conf setup構成が完了したら、サービスが実行されていることを確認します。
systemctl status mssql-server --no-pagerSQL Server コマンドライン ツールをインストールする
データベースを作成するには、SQL Server 上で Transact-SQL ステートメントを実行できるツールを使用して接続する必要があります。 次の手順で SQL Server コマンドライン ツールの sqlcmd と bcp をインストールします。
次の手順を使用して、Ubuntu に mssql-tools18 をインストールします。
Note
- Ubuntu 18.04 は SQL Server 2019 CU 3 以降でサポートされています。
- Ubuntu 20.04 は SQL Server 2019 CU 10 以降でサポートされています。
- Ubuntu 22.04 は SQL Server 2022 CU 10 以降でサポートされています。
スーパーユーザー モードにします。
sudo suパブリック リポジトリの GPG キーをインポートします。
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascMicrosoft Ubuntu リポジトリを登録します。
Ubuntu 22.04 の場合は、次のコマンドを実行します:
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listUbuntu 20.04 の場合は、次のコマンドを実行します:
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listUbuntu 18.04 の場合は、次のコマンドを実行します:
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listUbuntu 16.04 の場合は、次のコマンドを実行します:
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
スーパーユーザー モードを終了します。
exitソース一覧を更新し、unixODBC 開発者パッケージを使用してインストール コマンドを実行します。
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-dev注意
最新バージョンの mssql-tools に更新するには、次のコマンドを実行します:
sudo apt-get update sudo apt-get install mssql-tools18省略可能:bash シェルで
PATH環境変数に/opt/mssql-tools18/bin/を追加します。ログイン セッション用に bash シェルから sqlcmd と bcp にアクセスできるようにするには、次のコマンドで
~/.bash_profileのPATHを変更します:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profile対話型/非ログイン セッション用に bash シェルから sqlcmd と bcp にアクセスできるようにするには、次のコマンドで
~/.bashrcファイルのPATHを変更します:echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
SQL Server の高可用性エージェントをインストールする
すべてのノードで次のコマンドを実行して、SQL Server の高可用性エージェント パッケージをインストールします。
sudo apt-get install mssql-server-ha
可用性グループを構成する
次の手順を使用して、対象の VM の SQL Server Always On 可用性グループを構成します。 詳細については、「Linux で高可用性を実現するために SQL Server の Always On 可用性グループを構成する」を参照してください。
可用性グループを有効にして SQL Server を再起動する
SQL Server インスタンスをホストする各ノードで可用性グループを有効にします。 その後、mssql-server サービスを再起動します。 各ノードで、次のコマンドを実行します。
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
証明書を作成する
Microsoft では、AG エンドポイントに対する Active Directory 認証をサポートしていません。 そのため、AG エンドポイントの暗号化には証明書を使用する必要があります。
SQL Server Management Studio (SSMS) または sqlcmd を使用して、すべてのノードに接続します。 次のコマンドを実行して、AlwaysOn_health セッションを有効にし、マスター キーを作成します。
重要
自分の SQL Server インスタンスにリモートで接続する場合は、ファイアウォールでポート 1433 を開いておく必要があります。 さらに、各 VM の NSG でポート 1433 へのインバウンド接続を許可する必要があります。 インバウンド セキュリティ規則の作成の詳細については、「セキュリティ規則を作成する」を参照してください。
<MasterKeyPassword>は、実際のパスワードに置き換えます。
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GOSSMS または sqlcmd を使用してプライマリ レプリカに接続します。 以下のコマンドを実行すると、プライマリ SQL Server レプリカの
/var/opt/mssql/data/dbm_certificate.cerに証明書が作成され、var/opt/mssql/data/dbm_certificate.pvkに秘密キーが作成されます。<PrivateKeyPassword>は、実際のパスワードに置き換えます。
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
exit コマンドを実行して sqlcmd セッションを終了し、SSH セッションに戻ります。
証明書をセカンダリ レプリカにコピーし、サーバー上に証明書を作成します
作成された 2 つのファイルを、可用性レプリカをホストするすべてのサーバー上の同じ場所にコピーします。
プライマリ サーバー上で次の
scpコマンドを実行して、証明書をターゲット サーバーにコピーします。<username>とsles2を、使用しているユーザー名とターゲット VM 名に置き換えます。- すべてのセカンダリ レプリカに対してこのコマンドを実行します。
Note
root 環境が提供される
sudo -iを実行する必要はありません。 代わりに、各コマンドの先頭でsudoコマンドを実行できます。# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>ターゲット サーバー上で、次のコマンドを実行します。
<username>は、実際のユーザー名に置き換えます。mvコマンドにより、ある場所から別の場所にファイルまたはディレクトリが移動されます。chownコマンドは、ファイル、ディレクトリ、またはリンクの所有者とグループを変更するために使用します。- すべてのセカンダリ レプリカに対してこれらのコマンドを実行します。
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*次の Transact-SQL スクリプトでは、プライマリ SQL Server レプリカ上に作成したバックアップから証明書を作成します。 強力なパスワードでスクリプトを更新してください。 解読パスワードは、前の手順で .pvk ファイルの作成に使ったのと同じパスワードです。 証明書を作成するには、すべてのセカンダリ サーバーで sqlcmd または SSMS を使用して次のスクリプトを実行します。
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
すべてのレプリカにデータベース ミラーリング エンドポイントを作成する
sqlcmd または SSMS を使用して、すべての SQL Server インスタンスで次のスクリプトを実行します。
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
可用性グループを作成する
sqlcmd または SSMS を使用して、プライマリ レプリカをホストする SQL Server インスタンスに接続します。 次のコマンドを実行して、可用性グループを作成します。
ag1を、希望する AG 名に置き換えます。ubuntu1、ubuntu2、およびubuntu3の値は、レプリカをホストする SQL Server インスタンスの名前に置き換えます。
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Pacemaker 用の SQL Server ログインを作成する
すべての SQL Server インスタンスで、Pacemaker 用 SQL Server ログインを作成します。 次の Transact-SQL により、ログインが作成されます。
<password>は、独自の複雑なパスワードに置き換えます。
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
すべての SQL Server インスタンスで、SQL Server ログインに使用される資格情報を保存します。
ファイルを作成します。
sudo vi /var/opt/mssql/secrets/passwdファイルに次の 2 行を追加します。
pacemakerLogin <password>vi エディターを終了するには、まず Esc キーを押し、コマンド
:wqを入力してファイルを書き込み、終了します。ファイルが root によってのみ読み取り可能になるようにします。
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
セカンダリ レプリカを可用性グループに参加させる
対象のセカンダリ レプリカで次のコマンドを実行して、AG に参加させます。
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOプライマリ レプリカと各セカンダリ レプリカで次の Transact-SQL スクリプトを実行します。
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOセカンダリ レプリカを参加させたら、 [Always On 高可用性] ノードを展開して、SSMS オブジェクト エクスプローラーでそれらを確認できます。
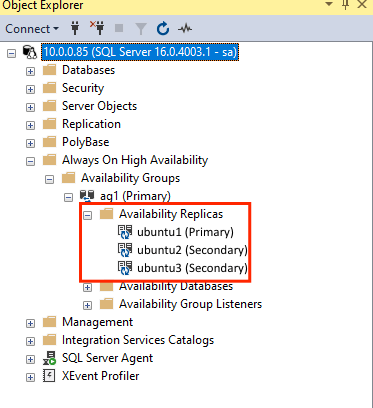
可用性グループにデータベースを追加する
このセクションは、可用性グループへのデータベースの追加について説明する記事に従います。
この手順では、次の Transact-SQL コマンドを使用します。 プライマリ レプリカ上でこれらのコマンドを実行します。
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
セカンダリ サーバーにデータベースが作成されたことを確認する
各セカンダリ SQL Server レプリカで次のクエリを実行して、db1 データベースが作成され、SYNCHRONIZED 状態にあるかどうかを確認します。
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
db1 に対して synchronization_state_desc が SYNCHRONIZED と示される場合は、レプリカが同期されていることを意味します。 セカンダリでは、プライマリ レプリカの db1 が表示されます。
Pacemaker クラスター内に可用性グループのリソースを作成する
Pacemaker 内に可用性グループのリソースを作成するには、次のコマンドを実行します。
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
上記のコマンドを実行すると、ag1_cluster リソース、つまり可用性グループのリソースが作成されます。 次に、ms-ag1 リソース (Pacemaker のプライマリ/セカンダリ リソースが作成され、それに AG リソースが追加されます。これにより、AG リソースはクラスター内の 3 つのノードすべてで実行されますが、プライマリ ノードは 1 つだけになります)。
AG グループ リソースを表示し、クラスターの状態をチェックするには:
sudo crm resource status ms-ag1
sudo crm status
出力は次の例のようになります。
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
出力は次の例のようになります。 コロケーションと昇格の制約を追加するには、「チュートリアル: Linux Virtual Machines で可用性グループ リスナーを構成する」を参照してください。
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
リスナーとロード バランサーに適用されるコロケーションと昇格の制約を個別に適用する必要がないように、次のコマンドを実行してグループ リソースを作成します。
sudo crm configure group virtualip-group azure-load-balancer virtualip
crm status の出力は次の例のようになります。
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1